 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Influence Signals for Data Debugging
Jun 13, 2025



Improving the quality of training samples is crucial for improving the reliability and performance of ML models. In this paper, we conduct a comparative evaluation of influence-based signals for debugging training data. These signals can potentially identify both mislabeled and anomalous samples from a potentially noisy training set as we build the models and hence alleviate the need for dedicated glitch detectors. Although several influence-based signals (e.g., Self-Influence, Average Absolute Influence, Marginal Influence, GD-class) have been recently proposed in the literature, there are no experimental studies for assessing their power in detecting different glitch types (e.g., mislabeled and anomalous samples) under a common influence estimator (e.g., TraceIn) for different data modalities (image and tabular), and deep learning models (trained from scratch or foundation). Through extensive experiments, we show that signals like Self-Influence effectively detect mislabeled samples, but none of the existing signals can detect anomalies. Existing signals do not take into account the training dynamics, i.e., how the samples' influence on the model changes during training, while some signals fall into influence cancellation effects, i.e., influence score is zero due to unsigned scores accumulation, resulting in misleading influence attribution.
A Meta-level Analysis of Online Anomaly Detectors
Sep 13, 2022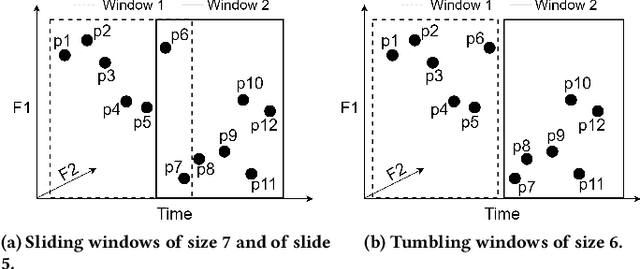
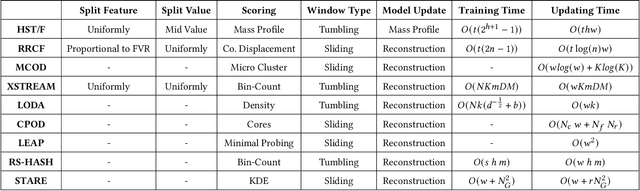
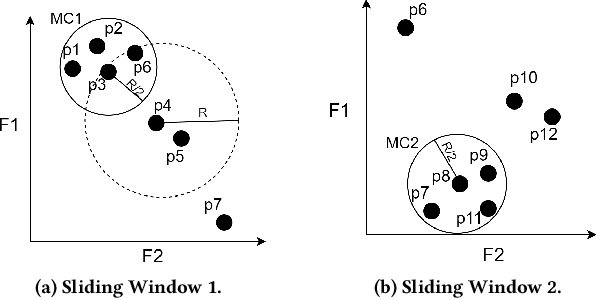
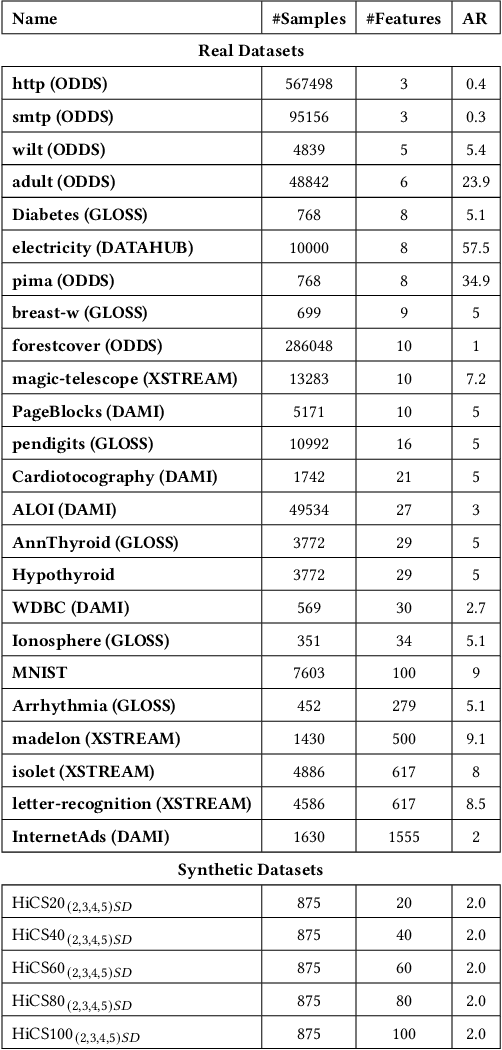
Real-time detection of anomalies in streaming data is receiving increasing attention as it allows us to raise alerts, predict faults, and detect intrusions or threats across industries. Yet, little attention has been given to compare the effectiveness and efficiency of anomaly detectors for streaming data (i.e., of online algorithms). In this paper, we present a qualitative, synthetic overview of major online detectors from different algorithmic families (i.e., distance, density, tree or projection-based) and highlight their main ideas for constructing, updating and testing detection models. Then, we provide a thorough analysis of the results of a quantitative experimental evaluation of online detection algorithms along with their offline counterparts. The behavior of the detectors is correlated with the characteristics of different datasets (i.e., meta-features), thereby providing a meta-level analysis of their performance. Our study addresses several missing insights from the literature such as (a) how reliable are detectors against a random classifier and what dataset characteristics make them perform randomly; (b) to what extent online detectors approximate the performance of offline counterparts; (c) which sketch strategy and update primitives of detectors are best to detect anomalies visible only within a feature subspace of a dataset; (d) what are the tradeoffs between the effectiveness and the efficiency of detectors belonging to different algorithmic families; (e) which specific characteristics of datasets yield an online algorithm to outperform all others.
On Predictive Explanation of Data Anomalies
Oct 18, 2021Numerous algorithms have been proposed for detecting anomalies (outliers, novelties) in an unsupervised manner. Unfortunately, it is not trivial, in general, to understand why a given sample (record) is labelled as an anomaly and thus diagnose its root causes. We propose the following reduced-dimensionality, surrogate model approach to explain detector decisions: approximate the detection model with another one that employs only a small subset of features. Subsequently, samples can be visualized in this low-dimensionality space for human understanding. To this end, we develop PROTEUS, an AutoML pipeline to produce the surrogate model, specifically designed for feature selection on imbalanced datasets. The PROTEUS surrogate model can not only explain the training data, but also the out-of-sample (unseen) data. In other words, PROTEUS produces predictive explanations by approximating the decision surface of an unsupervised detector. PROTEUS is designed to return an accurate estimate of out-of-sample predictive performance to serve as a metric of the quality of the approximation. Computational experiments confirm the efficacy of PROTEUS to produce predictive explanations for different families of detectors and to reliably estimate their predictive performance in unseen data. Unlike several ad-hoc feature importance methods, PROTEUS is robust to high-dimensional data.