 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Planning for Optimal Data Pipeline Instantiation
Mar 16, 2025
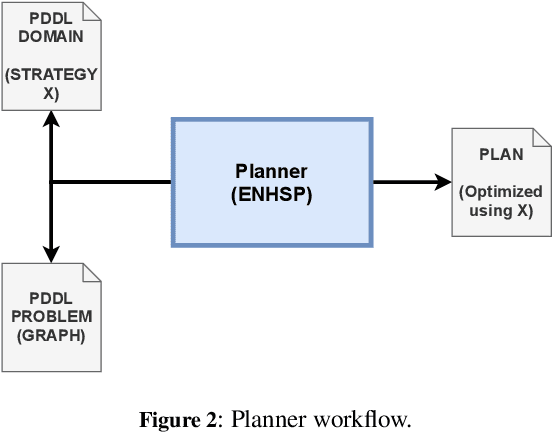


Data pipeline frameworks provide abstractions for implementing sequences of data-intensive transformation operators, automating the deployment and execution of such transformations in a cluster. Deploying a data pipeline, however, requires computing resources to be allocated in a data center, ideally minimizing the overhead for communicating data and executing operators in the pipeline while considering each operator's execution requirements. In this paper, we model the problem of optimal data pipeline deployment as planning with action costs, where we propose heuristics aiming to minimize total execution time. Experimental results indicate that the heuristics can outperform the baseline deployment and that a heuristic based on connections outperforms other strategies.