 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Planning for Optimal Data Pipeline Instantiation
Mar 16, 2025
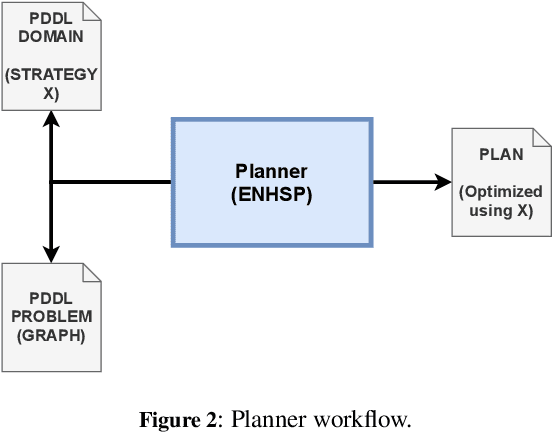


Data pipeline frameworks provide abstractions for implementing sequences of data-intensive transformation operators, automating the deployment and execution of such transformations in a cluster. Deploying a data pipeline, however, requires computing resources to be allocated in a data center, ideally minimizing the overhead for communicating data and executing operators in the pipeline while considering each operator's execution requirements. In this paper, we model the problem of optimal data pipeline deployment as planning with action costs, where we propose heuristics aiming to minimize total execution time. Experimental results indicate that the heuristics can outperform the baseline deployment and that a heuristic based on connections outperforms other strategies.
Online Goal Recognition in Discrete and Continuous Domains Using a Vectorial Representation
Jul 15, 2023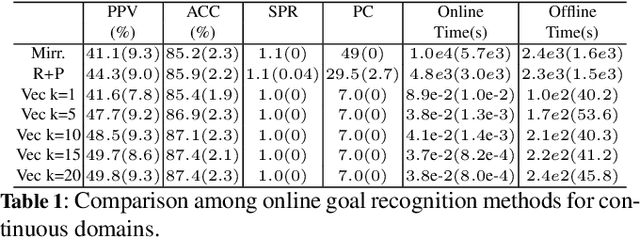

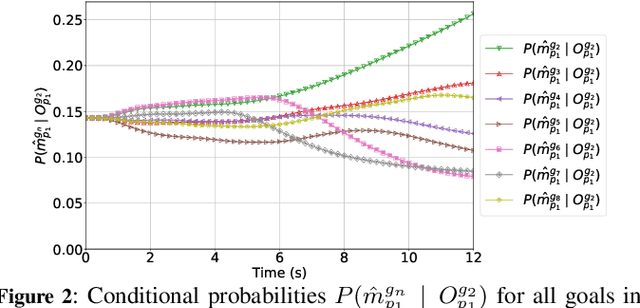
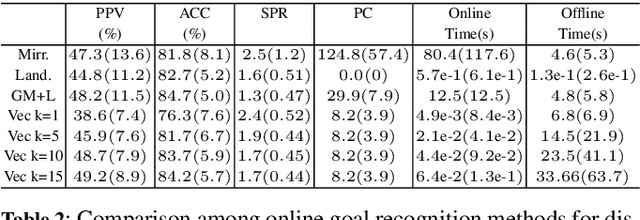
While recent work on online goal recognition efficiently infers goals under low observability, comparatively less work focuses on online goal recognition that works in both discrete and continuous domains. Online goal recognition approaches often rely on repeated calls to the planner at each new observation, incurring high computational costs. Recognizing goals online in continuous space quickly and reliably is critical for any trajectory planning problem since the real physical world is fast-moving, e.g. robot applications. We develop an efficient method for goal recognition that relies either on a single call to the planner for each possible goal in discrete domains or a simplified motion model that reduces the computational burden in continuous ones. The resulting approach performs the online component of recognition orders of magnitude faster than the current state of the art, making it the first online method effectively usable for robotics applications that require sub-second recognition.
Goal Recognition as Reinforcement Learning
Feb 13, 2022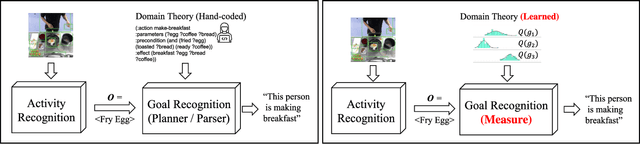
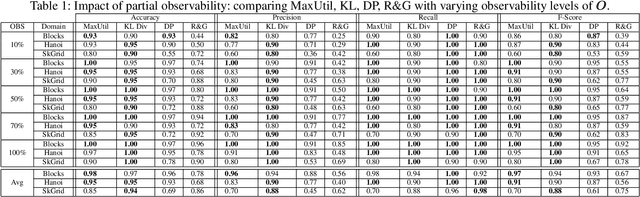
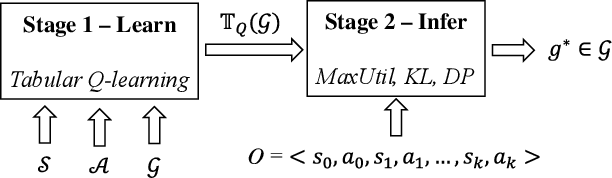

Most approaches for goal recognition rely on specifications of the possible dynamics of the actor in the environment when pursuing a goal. These specifications suffer from two key issues. First, encoding these dynamics requires careful design by a domain expert, which is often not robust to noise at recognition time. Second, existing approaches often need costly real-time computations to reason about the likelihood of each potential goal. In this paper, we develop a framework that combines model-free reinforcement learning and goal recognition to alleviate the need for careful, manual domain design, and the need for costly online executions. This framework consists of two main stages: Offline learning of policies or utility functions for each potential goal, and online inference. We provide a first instance of this framework using tabular Q-learning for the learning stage, as well as three measures that can be used to perform the inference stage. The resulting instantiation achieves state-of-the-art performance against goal recognizers on standard evaluation domains and superior performance in noisy environments.