 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRusso-Ukrainian War: Prediction and explanation of Twitter suspension
Jun 06, 2023



On 24 February 2022, Russia invaded Ukraine, starting what is now known as the Russo-Ukrainian War, initiating an online discourse on social media. Twitter as one of the most popular SNs, with an open and democratic character, enables a transparent discussion among its large user base. Unfortunately, this often leads to Twitter's policy violations, propaganda, abusive actions, civil integrity violation, and consequently to user accounts' suspension and deletion. This study focuses on the Twitter suspension mechanism and the analysis of shared content and features of the user accounts that may lead to this. Toward this goal, we have obtained a dataset containing 107.7M tweets, originating from 9.8 million users, using Twitter API. We extract the categories of shared content of the suspended accounts and explain their characteristics, through the extraction of text embeddings in junction with cosine similarity clustering. Our results reveal scam campaigns taking advantage of trending topics regarding the Russia-Ukrainian conflict for Bitcoin and Ethereum fraud, spam, and advertisement campaigns. Additionally, we apply a machine learning methodology including a SHapley Additive explainability model to understand and explain how user accounts get suspended.
BotArtist: Twitter bot detection Machine Learning model based on Twitter suspension
Jun 02, 2023Twitter as one of the most popular social networks, offers a means for communication and online discourse, which unfortunately has been the target of bots and fake accounts, leading to the manipulation and spreading of false information. Towards this end, we gather a challenging, multilingual dataset of social discourse on Twitter, originating from 9M users regarding the recent Russo-Ukrainian war, in order to detect the bot accounts and the conversation involving them. We collect the ground truth for our dataset through the Twitter API suspended accounts collection, containing approximately 343K of bot accounts and 8M of normal users. Additionally, we use a dataset provided by Botometer-V3 with 1,777 Varol, 483 German accounts, and 1,321 US accounts. Besides the publicly available datasets, we also manage to collect 2 independent datasets around popular discussion topics of the 2022 energy crisis and the 2022 conspiracy discussions. Both of the datasets were labeled according to the Twitter suspension mechanism. We build a novel ML model for bot detection using the state-of-the-art XGBoost model. We combine the model with a high volume of labeled tweets according to the Twitter suspension mechanism ground truth. This requires a limited set of profile features allowing labeling of the dataset in different time periods from the collection, as it is independent of the Twitter API. In comparison with Botometer our methodology achieves an average 11% higher ROC-AUC score over two real-case scenario datasets.
Twitter Dataset on the Russo-Ukrainian War
Apr 07, 2022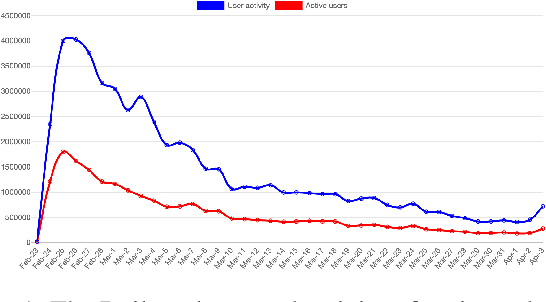
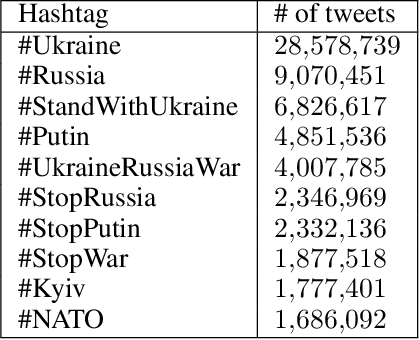
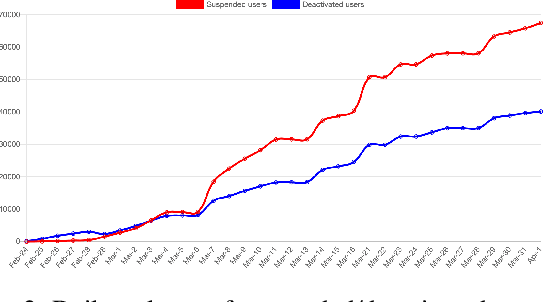
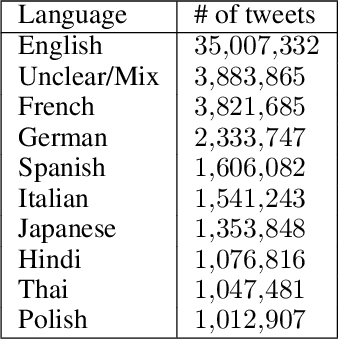
On 24 February 2022, Russia invaded Ukraine, also known now as Russo-Ukrainian War. We have initiated an ongoing dataset acquisition from Twitter API. Until the day this paper was written the dataset has reached the amount of 57.3 million tweets, originating from 7.7 million users. We apply an initial volume and sentiment analysis, while the dataset can be used to further exploratory investigation towards topic analysis, hate speech, propaganda recognition, or even show potential malicious entities like botnets.
TwitterMancer: Predicting Interactions on Twitter Accurately
Apr 25, 2019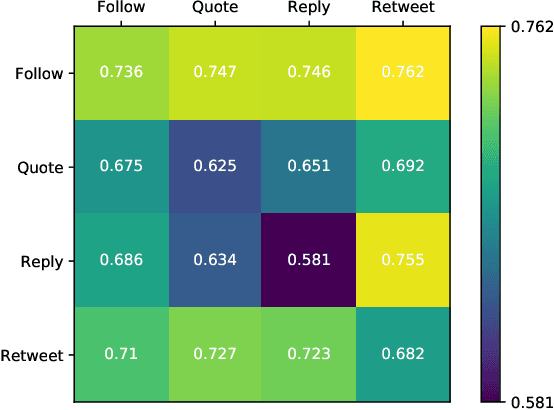
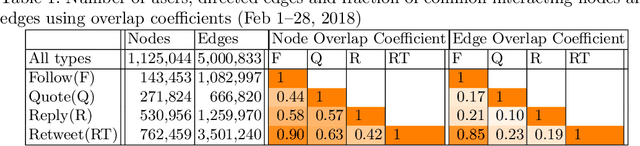


This paper investigates the interplay between different types of user interactions on Twitter, with respect to predicting missing or unseen interactions. For example, given a set of retweet interactions between Twitter users, how accurately can we predict reply interactions? Is it more difficult to predict retweet or quote interactions between a pair of accounts? Also, how important is time locality, and which features of interaction patterns are most important to enable accurate prediction of specific Twitter interactions? Our empirical study of Twitter interactions contributes initial answers to these questions. We have crawled an extensive dataset of Greek-speaking Twitter accounts and their follow, quote, retweet, reply interactions over a period of a month. We find we can accurately predict many interactions of Twitter users. Interestingly, the most predictive features vary with the user profiles, and are not the same across all users. For example, for a pair of users that interact with a large number of other Twitter users, we find that certain "higher-dimensional" triads, i.e., triads that involve multiple types of interactions, are very informative, whereas for less active Twitter users, certain in-degrees and out-degrees play a major role. Finally, we provide various other insights on Twitter user behavior. Our code and data are available at https://github.com/twittermancer/. Keywords: Graph mining, machine learning, social media, social networks
Massively-Parallel Feature Selection for Big Data
Aug 23, 2017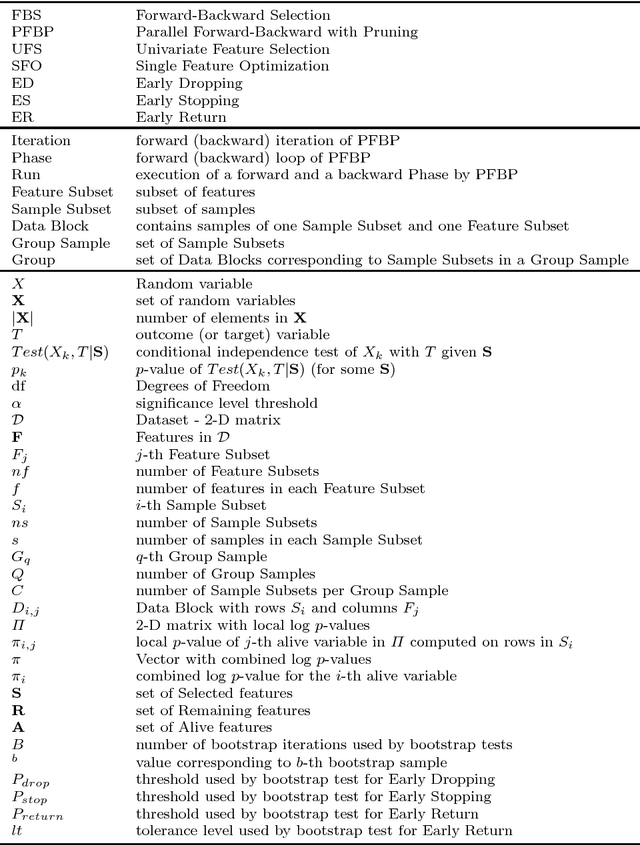
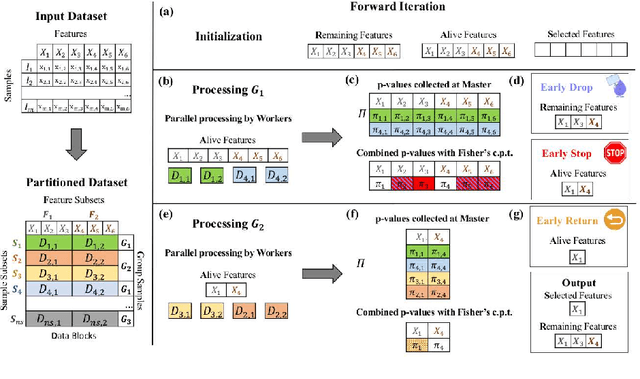
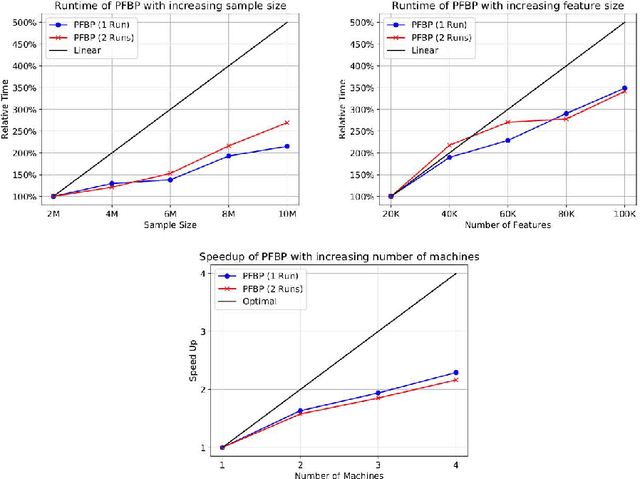
We present the Parallel, Forward-Backward with Pruning (PFBP) algorithm for feature selection (FS) in Big Data settings (high dimensionality and/or sample size). To tackle the challenges of Big Data FS PFBP partitions the data matrix both in terms of rows (samples, training examples) as well as columns (features). By employing the concepts of $p$-values of conditional independence tests and meta-analysis techniques PFBP manages to rely only on computations local to a partition while minimizing communication costs. Then, it employs powerful and safe (asymptotically sound) heuristics to make early, approximate decisions, such as Early Dropping of features from consideration in subsequent iterations, Early Stopping of consideration of features within the same iteration, or Early Return of the winner in each iteration. PFBP provides asymptotic guarantees of optimality for data distributions faithfully representable by a causal network (Bayesian network or maximal ancestral graph). Our empirical analysis confirms a super-linear speedup of the algorithm with increasing sample size, linear scalability with respect to the number of features and processing cores, while dominating other competitive algorithms in its class.