 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRusso-Ukrainian War: Prediction and explanation of Twitter suspension
Jun 06, 2023



On 24 February 2022, Russia invaded Ukraine, starting what is now known as the Russo-Ukrainian War, initiating an online discourse on social media. Twitter as one of the most popular SNs, with an open and democratic character, enables a transparent discussion among its large user base. Unfortunately, this often leads to Twitter's policy violations, propaganda, abusive actions, civil integrity violation, and consequently to user accounts' suspension and deletion. This study focuses on the Twitter suspension mechanism and the analysis of shared content and features of the user accounts that may lead to this. Toward this goal, we have obtained a dataset containing 107.7M tweets, originating from 9.8 million users, using Twitter API. We extract the categories of shared content of the suspended accounts and explain their characteristics, through the extraction of text embeddings in junction with cosine similarity clustering. Our results reveal scam campaigns taking advantage of trending topics regarding the Russia-Ukrainian conflict for Bitcoin and Ethereum fraud, spam, and advertisement campaigns. Additionally, we apply a machine learning methodology including a SHapley Additive explainability model to understand and explain how user accounts get suspended.
BotArtist: Twitter bot detection Machine Learning model based on Twitter suspension
Jun 02, 2023Twitter as one of the most popular social networks, offers a means for communication and online discourse, which unfortunately has been the target of bots and fake accounts, leading to the manipulation and spreading of false information. Towards this end, we gather a challenging, multilingual dataset of social discourse on Twitter, originating from 9M users regarding the recent Russo-Ukrainian war, in order to detect the bot accounts and the conversation involving them. We collect the ground truth for our dataset through the Twitter API suspended accounts collection, containing approximately 343K of bot accounts and 8M of normal users. Additionally, we use a dataset provided by Botometer-V3 with 1,777 Varol, 483 German accounts, and 1,321 US accounts. Besides the publicly available datasets, we also manage to collect 2 independent datasets around popular discussion topics of the 2022 energy crisis and the 2022 conspiracy discussions. Both of the datasets were labeled according to the Twitter suspension mechanism. We build a novel ML model for bot detection using the state-of-the-art XGBoost model. We combine the model with a high volume of labeled tweets according to the Twitter suspension mechanism ground truth. This requires a limited set of profile features allowing labeling of the dataset in different time periods from the collection, as it is independent of the Twitter API. In comparison with Botometer our methodology achieves an average 11% higher ROC-AUC score over two real-case scenario datasets.
Twitter Dataset on the Russo-Ukrainian War
Apr 07, 2022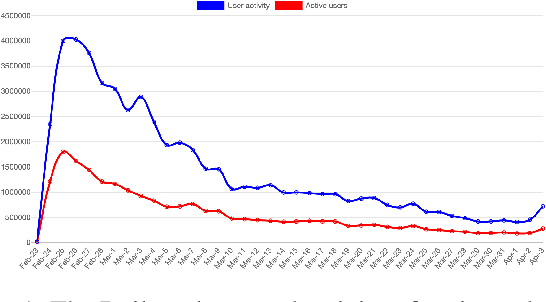
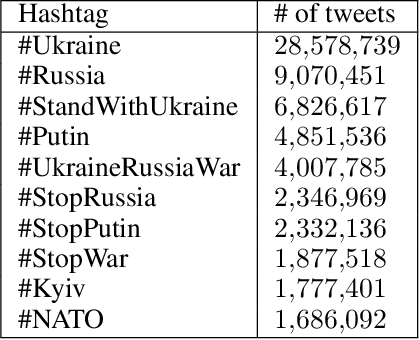
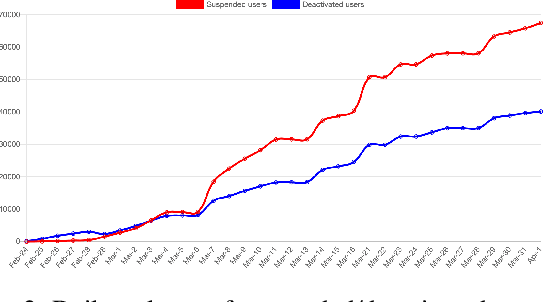
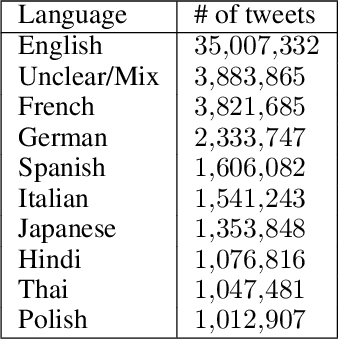
On 24 February 2022, Russia invaded Ukraine, also known now as Russo-Ukrainian War. We have initiated an ongoing dataset acquisition from Twitter API. Until the day this paper was written the dataset has reached the amount of 57.3 million tweets, originating from 7.7 million users. We apply an initial volume and sentiment analysis, while the dataset can be used to further exploratory investigation towards topic analysis, hate speech, propaganda recognition, or even show potential malicious entities like botnets.
Identification of Twitter Bots Based on an Explainable Machine Learning Framework: The US 2020 Elections Case Study
Dec 14, 2021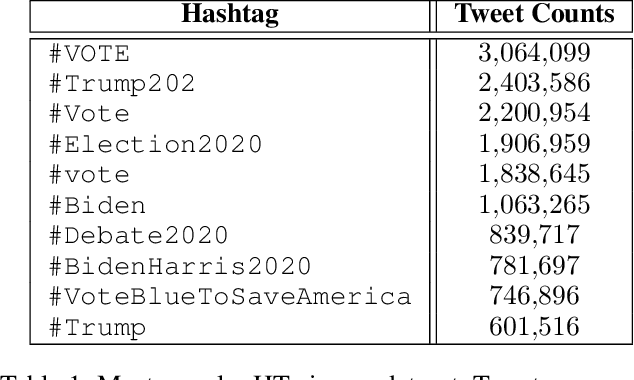
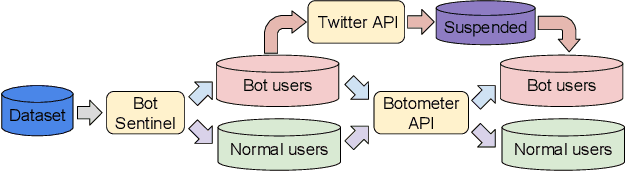
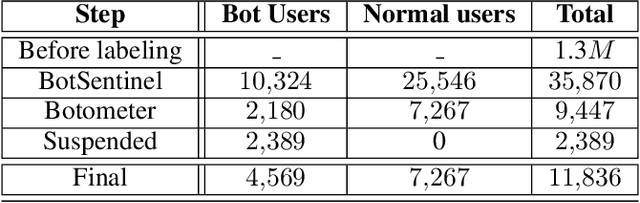
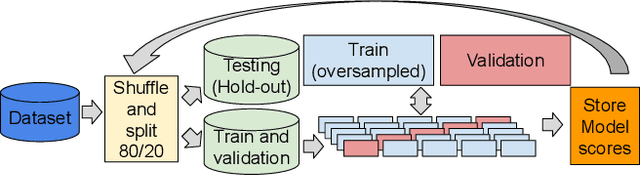
Twitter is one of the most popular social networks attracting millions of users, while a considerable proportion of online discourse is captured. It provides a simple usage framework with short messages and an efficient application programming interface (API) enabling the research community to study and analyze several aspects of this social network. However, the Twitter usage simplicity can lead to malicious handling by various bots. The malicious handling phenomenon expands in online discourse, especially during the electoral periods, where except the legitimate bots used for dissemination and communication purposes, the goal is to manipulate the public opinion and the electorate towards a certain direction, specific ideology, or political party. This paper focuses on the design of a novel system for identifying Twitter bots based on labeled Twitter data. To this end, a supervised machine learning (ML) framework is adopted using an Extreme Gradient Boosting (XGBoost) algorithm, where the hyper-parameters are tuned via cross-validation. Our study also deploys Shapley Additive Explanations (SHAP) for explaining the ML model predictions by calculating feature importance, using the game theoretic-based Shapley values. Experimental evaluation on distinct Twitter datasets demonstrate the superiority of our approach, in terms of bot detection accuracy, when compared against a recent state-of-the-art Twitter bot detection method.