 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQN-Mixer: A Quasi-Newton MLP-Mixer Model for Sparse-View CT Reconstruction
Feb 29, 2024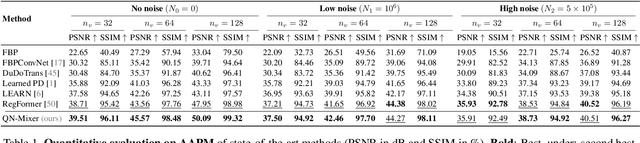
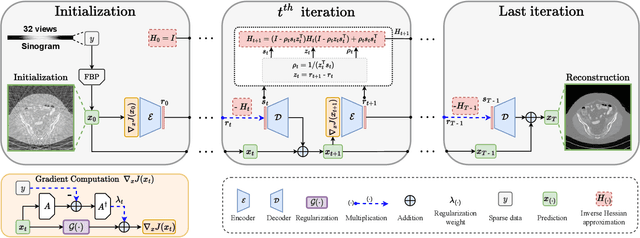
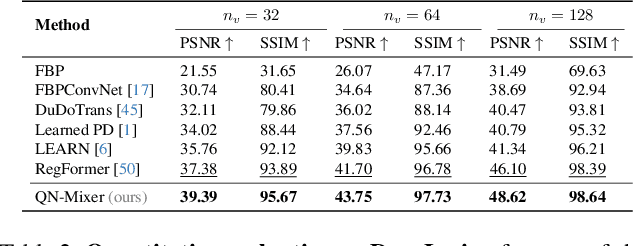
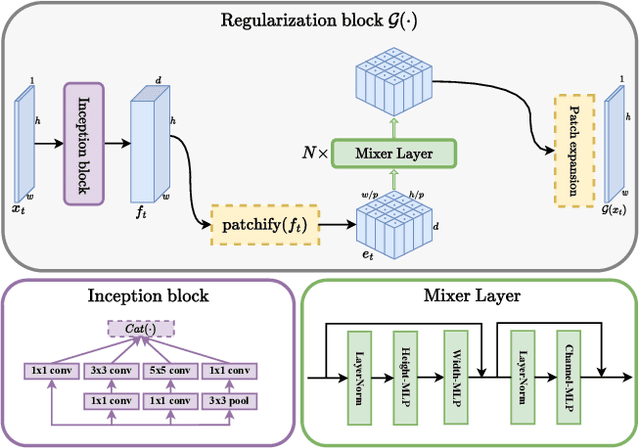
Inverse problems span across diverse fields. In medical contexts, computed tomography (CT) plays a crucial role in reconstructing a patient's internal structure, presenting challenges due to artifacts caused by inherently ill-posed inverse problems. Previous research advanced image quality via post-processing and deep unrolling algorithms but faces challenges, such as extended convergence times with ultra-sparse data. Despite enhancements, resulting images often show significant artifacts, limiting their effectiveness for real-world diagnostic applications. We aim to explore deep second-order unrolling algorithms for solving imaging inverse problems, emphasizing their faster convergence and lower time complexity compared to common first-order methods like gradient descent. In this paper, we introduce QN-Mixer, an algorithm based on the quasi-Newton approach. We use learned parameters through the BFGS algorithm and introduce Incept-Mixer, an efficient neural architecture that serves as a non-local regularization term, capturing long-range dependencies within images. To address the computational demands typically associated with quasi-Newton algorithms that require full Hessian matrix computations, we present a memory-efficient alternative. Our approach intelligently downsamples gradient information, significantly reducing computational requirements while maintaining performance. The approach is validated through experiments on the sparse-view CT problem, involving various datasets and scanning protocols, and is compared with post-processing and deep unrolling state-of-the-art approaches. Our method outperforms existing approaches and achieves state-of-the-art performance in terms of SSIM and PSNR, all while reducing the number of unrolling iterations required.
SeeABLE: Soft Discrepancies and Bounded Contrastive Learning for Exposing Deepfakes
Nov 21, 2022Modern deepfake detectors have achieved encouraging results, when training and test images are drawn from the same collection. However, when applying these detectors to faces manipulated using an unknown technique, considerable performance drops are typically observed. In this work, we propose a novel deepfake detector, called SeeABLE, that formalizes the detection problem as a (one-class) out-of-distribution detection task and generalizes better to unseen deepfakes. Specifically, SeeABLE uses a novel data augmentation strategy to synthesize fine-grained local image anomalies (referred to as soft-discrepancies) and pushes those pristine disrupted faces towards predefined prototypes using a novel regression-based bounded contrastive loss. To strengthen the generalization performance of SeeABLE to unknown deepfake types, we generate a rich set of soft discrepancies and train the detector: (i) to localize, which part of the face was modified, and (ii) to identify the alteration type. Using extensive experiments on widely used datasets, SeeABLE considerably outperforms existing detectors, with gains of up to +10\% on the DFDC-preview dataset in term of detection accuracy over SoTA methods while using a simpler model. Code will be made publicly available.