 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Embedding Methods for Entity Alignment: An Experimental Review
Mar 17, 2022
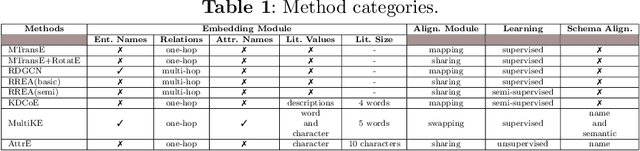


In recent years, we have witnessed the proliferation of knowledge graphs (KG) in various domains, aiming to support applications like question answering, recommendations, etc. A frequent task when integrating knowledge from different KGs is to find which subgraphs refer to the same real-world entity. Recently, embedding methods have been used for entity alignment tasks, that learn a vector-space representation of entities which preserves their similarity in the original KGs. A wide variety of supervised, unsupervised, and semi-supervised methods have been proposed that exploit both factual (attribute based) and structural information (relation based) of entities in the KGs. Still, a quantitative assessment of their strengths and weaknesses in real-world KGs according to different performance metrics and KG characteristics is missing from the literature. In this work, we conduct the first meta-level analysis of popular embedding methods for entity alignment, based on a statistically sound methodology. Our analysis reveals statistically significant correlations of different embedding methods with various meta-features extracted by KGs and rank them in a statistically significant way according to their effectiveness across all real-world KGs of our testbed. Finally, we study interesting trade-offs in terms of methods' effectiveness and efficiency.