 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBI-REC: Guided Data Analysis for Conversational Business Intelligence
May 02, 2021

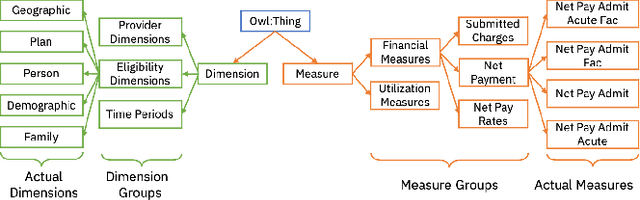
Conversational interfaces to Business Intelligence (BI) applications enable data analysis using a natural language dialog in small incremental steps. To truly unleash the power of conversational BI to democratize access to data, a system needs to provide effective and continuous support for data analysis. In this paper, we propose BI-REC, a conversational recommendation system for BI applications to help users accomplish their data analysis tasks. We define the space of data analysis in terms of BI patterns, augmented with rich semantic information extracted from the OLAP cube definition, and use graph embeddings learned using GraphSAGE to create a compact representation of the analysis state. We propose a two-step approach to explore the search space for useful BI pattern recommendations. In the first step, we train a multi-class classifier using prior query logs to predict the next high-level actions in terms of a BI operation (e.g., {\em Drill-Down} or {\em Roll-up}) and a measure that the user is interested in. In the second step, the high-level actions are further refined into actual BI pattern recommendations using collaborative filtering. This two-step approach allows us to not only divide and conquer the huge search space, but also requires less training data. Our experimental evaluation shows that BI-REC achieves an accuracy of 83% for BI pattern recommendations and up to 2X speedup in latency of prediction compared to a state-of-the-art baseline. Our user study further shows that BI-REC provides recommendations with a precision@3 of 91.90% across several different analysis tasks.
A Comprehensive Benchmark Framework for Active Learning Methods in Entity Matching
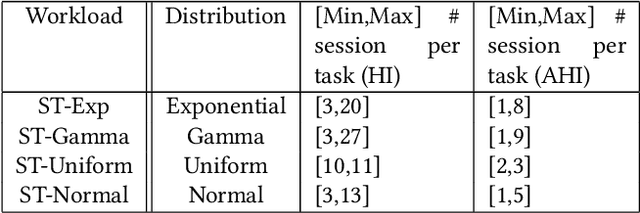
Mar 29, 2020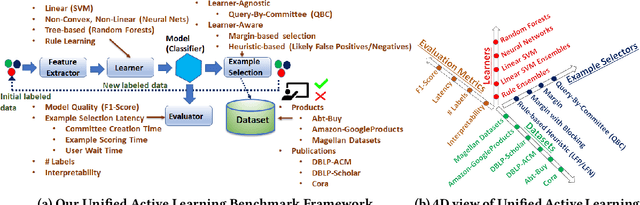
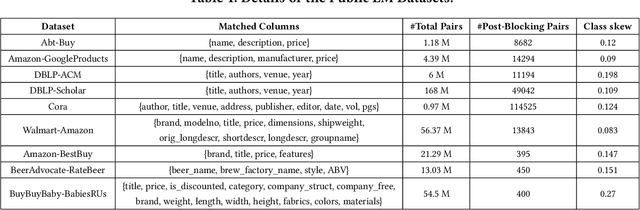
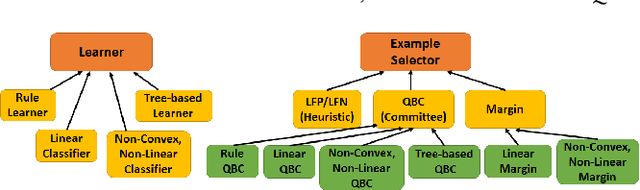

Entity Matching (EM) is a core data cleaning task, aiming to identify different mentions of the same real-world entity. Active learning is one way to address the challenge of scarce labeled data in practice, by dynamically collecting the necessary examples to be labeled by an Oracle and refining the learned model (classifier) upon them. In this paper, we build a unified active learning benchmark framework for EM that allows users to easily combine different learning algorithms with applicable example selection algorithms. The goal of the framework is to enable concrete guidelines for practitioners as to what active learning combinations will work well for EM. Towards this, we perform comprehensive experiments on publicly available EM datasets from product and publication domains to evaluate active learning methods, using a variety of metrics including EM quality, #labels and example selection latencies. Our most surprising result finds that active learning with fewer labels can learn a classifier of comparable quality as supervised learning. In fact, for several of the datasets, we show that there is an active learning combination that beats the state-of-the-art supervised learning result. Our framework also includes novel optimizations that improve the quality of the learned model by roughly 9% in terms of F1-score and reduce example selection latencies by up to 10x without affecting the quality of the model.