 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Benchmark Framework for Active Learning Methods in Entity Matching
Mar 29, 2020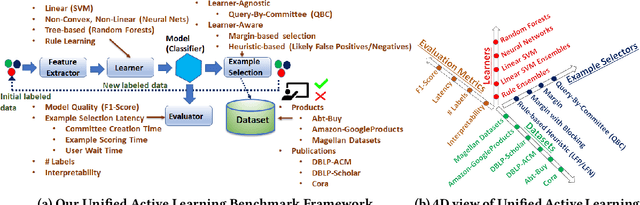
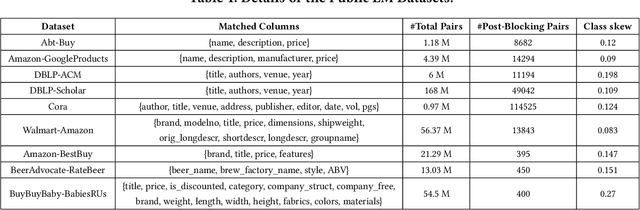
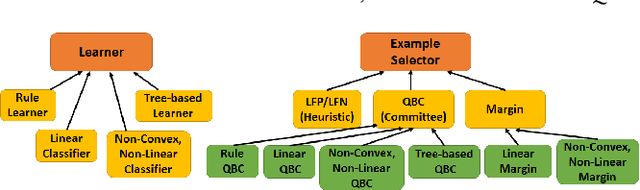

Entity Matching (EM) is a core data cleaning task, aiming to identify different mentions of the same real-world entity. Active learning is one way to address the challenge of scarce labeled data in practice, by dynamically collecting the necessary examples to be labeled by an Oracle and refining the learned model (classifier) upon them. In this paper, we build a unified active learning benchmark framework for EM that allows users to easily combine different learning algorithms with applicable example selection algorithms. The goal of the framework is to enable concrete guidelines for practitioners as to what active learning combinations will work well for EM. Towards this, we perform comprehensive experiments on publicly available EM datasets from product and publication domains to evaluate active learning methods, using a variety of metrics including EM quality, #labels and example selection latencies. Our most surprising result finds that active learning with fewer labels can learn a classifier of comparable quality as supervised learning. In fact, for several of the datasets, we show that there is an active learning combination that beats the state-of-the-art supervised learning result. Our framework also includes novel optimizations that improve the quality of the learned model by roughly 9% in terms of F1-score and reduce example selection latencies by up to 10x without affecting the quality of the model.
Matrix Factorization with Explicit Trust and Distrust Relationships
Aug 02, 2014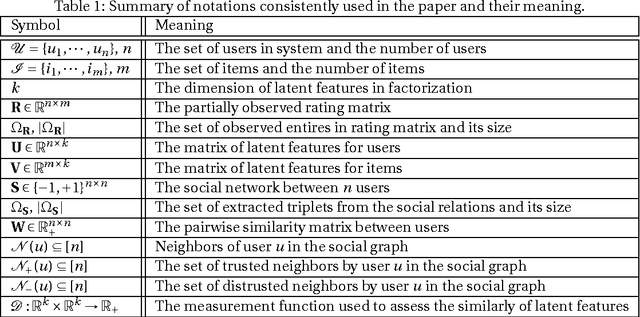
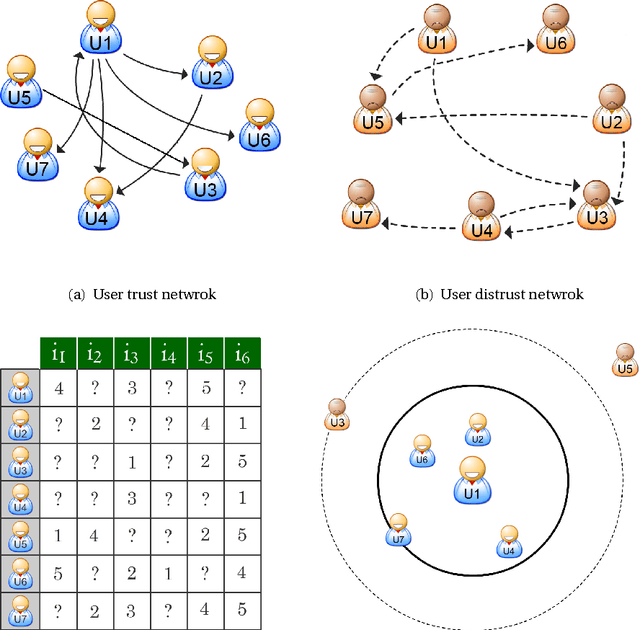
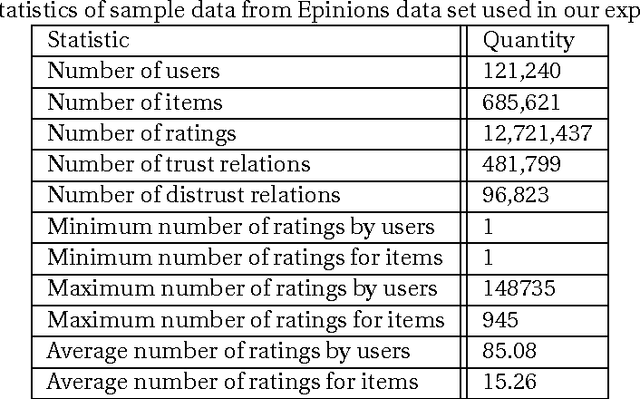
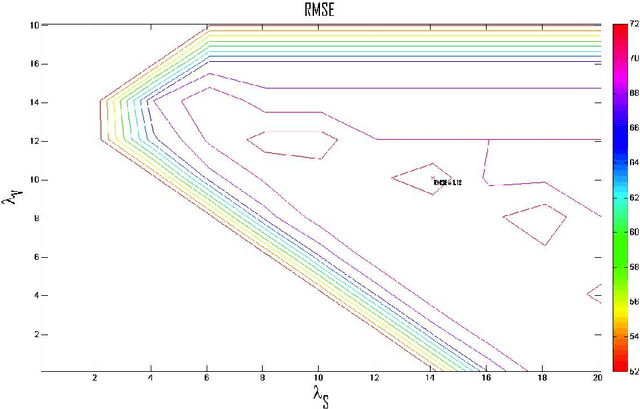
With the advent of online social networks, recommender systems have became crucial for the success of many online applications/services due to their significance role in tailoring these applications to user-specific needs or preferences. Despite their increasing popularity, in general recommender systems suffer from the data sparsity and the cold-start problems. To alleviate these issues, in recent years there has been an upsurge of interest in exploiting social information such as trust relations among users along with the rating data to improve the performance of recommender systems. The main motivation for exploiting trust information in recommendation process stems from the observation that the ideas we are exposed to and the choices we make are significantly influenced by our social context. However, in large user communities, in addition to trust relations, the distrust relations also exist between users. For instance, in Epinions the concepts of personal "web of trust" and personal "block list" allow users to categorize their friends based on the quality of reviews into trusted and distrusted friends, respectively. In this paper, we propose a matrix factorization based model for recommendation in social rating networks that properly incorporates both trust and distrust relationships aiming to improve the quality of recommendations and mitigate the data sparsity and the cold-start users issues. Through experiments on the Epinions data set, we show that our new algorithm outperforms its standard trust-enhanced or distrust-enhanced counterparts with respect to accuracy, thereby demonstrating the positive effect that incorporation of explicit distrust information can have on recommender systems.