 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto Efficient Fairness in Supervised Learning: From Extraction to Tracing
Apr 04, 2021
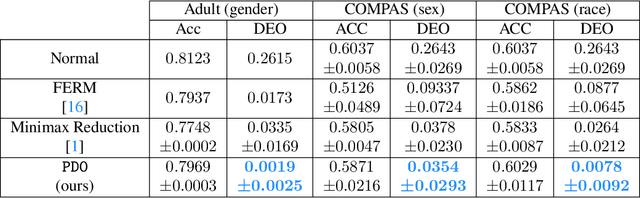
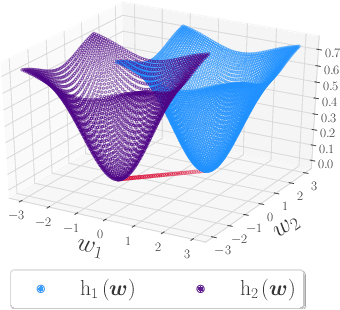
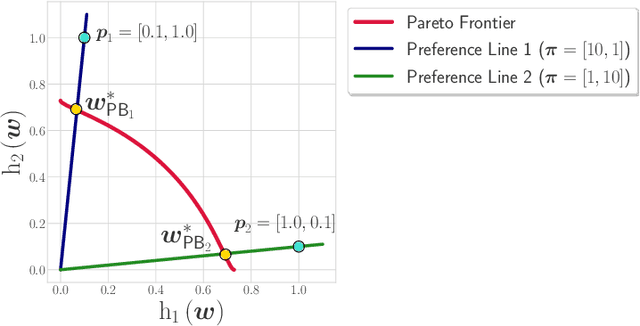
As algorithmic decision-making systems are becoming more pervasive, it is crucial to ensure such systems do not become mechanisms of unfair discrimination on the basis of gender, race, ethnicity, religion, etc. Moreover, due to the inherent trade-off between fairness measures and accuracy, it is desirable to learn fairness-enhanced models without significantly compromising the accuracy. In this paper, we propose Pareto efficient Fairness (PEF) as a suitable fairness notion for supervised learning, that can ensure the optimal trade-off between overall loss and other fairness criteria. The proposed PEF notion is definition-agnostic, meaning that any well-defined notion of fairness can be reduced to the PEF notion. To efficiently find a PEF classifier, we cast the fairness-enhanced classification as a bilevel optimization problem and propose a gradient-based method that can guarantee the solution belongs to the Pareto frontier with provable guarantees for convex and non-convex objectives. We also generalize the proposed algorithmic solution to extract and trace arbitrary solutions from the Pareto frontier for a given preference over accuracy and fairness measures. This approach is generic and can be generalized to any multicriteria optimization problem to trace points on the Pareto frontier curve, which is interesting by its own right. We empirically demonstrate the effectiveness of the PEF solution and the extracted Pareto frontier on real-world datasets compared to state-of-the-art methods.
Minimal Variance Sampling with Provable Guarantees for Fast Training of Graph Neural Networks
Jun 24, 2020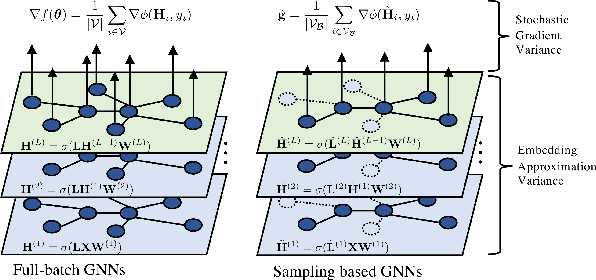

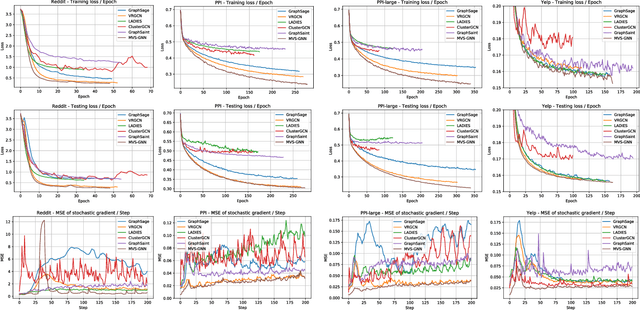

Sampling methods (e.g., node-wise, layer-wise, or subgraph) has become an indispensable strategy to speed up training large-scale Graph Neural Networks (GNNs). However, existing sampling methods are mostly based on the graph structural information and ignore the dynamicity of optimization, which leads to high variance in estimating the stochastic gradients. The high variance issue can be very pronounced in extremely large graphs, where it results in slow convergence and poor generalization. In this paper, we theoretically analyze the variance of sampling methods and show that, due to the composite structure of empirical risk, the variance of any sampling method can be decomposed into \textit{embedding approximation variance} in the forward stage and \textit{stochastic gradient variance} in the backward stage that necessities mitigating both types of variance to obtain faster convergence rate. We propose a decoupled variance reduction strategy that employs (approximate) gradient information to adaptively sample nodes with minimal variance, and explicitly reduces the variance introduced by embedding approximation. We show theoretically and empirically that the proposed method, even with smaller mini-batch sizes, enjoys a faster convergence rate and entails a better generalization compared to the existing methods.
Efficient Fair Principal Component Analysis
Nov 12, 2019
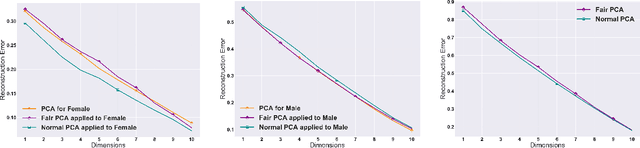
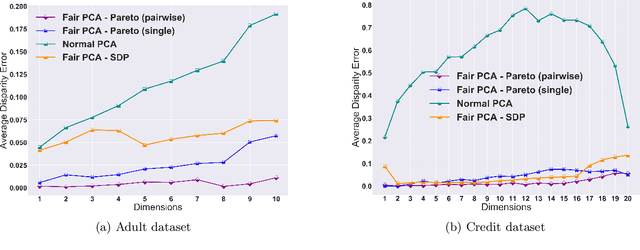
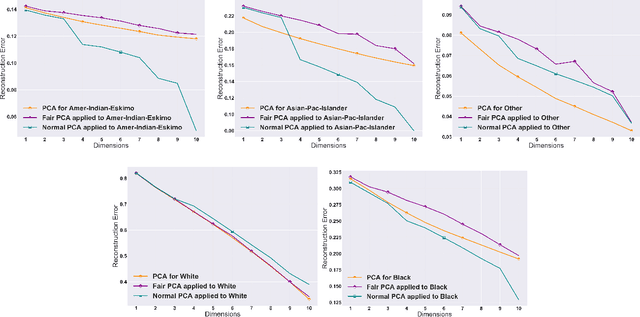
The flourishing assessments of fairness measure in machine learning algorithms have shown that dimension reduction methods such as PCA treat data from different sensitive groups unfairly. In particular, by aggregating data of different groups, the reconstruction error of the learned subspace becomes biased towards some populations that might hurt or benefit those groups inherently, leading to an unfair representation. On the other hand, alleviating the bias to protect sensitive groups in learning the optimal projection, would lead to a higher reconstruction error overall. This introduces a trade-off between sensitive groups' sacrifices and benefits, and the overall reconstruction error. In this paper, in pursuit of achieving fairness criteria in PCA, we introduce a more efficient notion of Pareto fairness, cast the Pareto fair dimensionality reduction as a multi-objective optimization problem, and propose an adaptive gradient-based algorithm to solve it. Using the notion of Pareto optimality, we can guarantee that the solution of our proposed algorithm belongs to the Pareto frontier for all groups, which achieves the optimal trade-off between those aforementioned conflicting objectives. This framework can be efficiently generalized to multiple group sensitive features, as well. We provide convergence analysis of our algorithm for both convex and non-convex objectives and show its efficacy through empirical studies on different datasets, in comparison with the state-of-the-art algorithm.
Semi-supervised Collaborative Ranking with Push at Top
Nov 17, 2015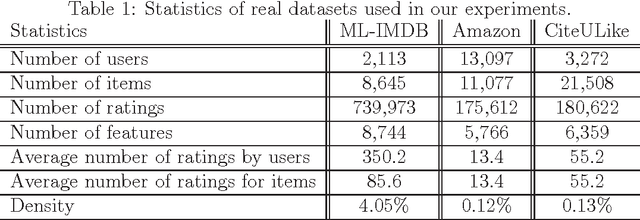



Existing collaborative ranking based recommender systems tend to perform best when there is enough observed ratings for each user and the observation is made completely at random. Under this setting recommender systems can properly suggest a list of recommendations according to the user interests. However, when the observed ratings are extremely sparse (e.g. in the case of cold-start users where no rating data is available), and are not sampled uniformly at random, existing ranking methods fail to effectively leverage side information to transduct the knowledge from existing ratings to unobserved ones. We propose a semi-supervised collaborative ranking model, dubbed \texttt{S$^2$COR}, to improve the quality of cold-start recommendation. \texttt{S$^2$COR} mitigates the sparsity issue by leveraging side information about both observed and missing ratings by collaboratively learning the ranking model. This enables it to deal with the case of missing data not at random, but to also effectively incorporate the available side information in transduction. We experimentally evaluated our proposed algorithm on a number of challenging real-world datasets and compared against state-of-the-art models for cold-start recommendation. We report significantly higher quality recommendations with our algorithm compared to the state-of-the-art.
Matrix Factorization with Explicit Trust and Distrust Relationships
Aug 02, 2014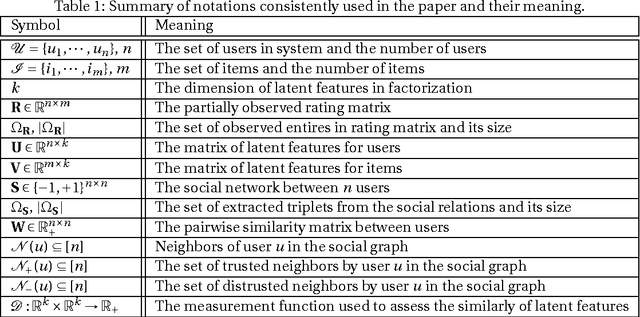
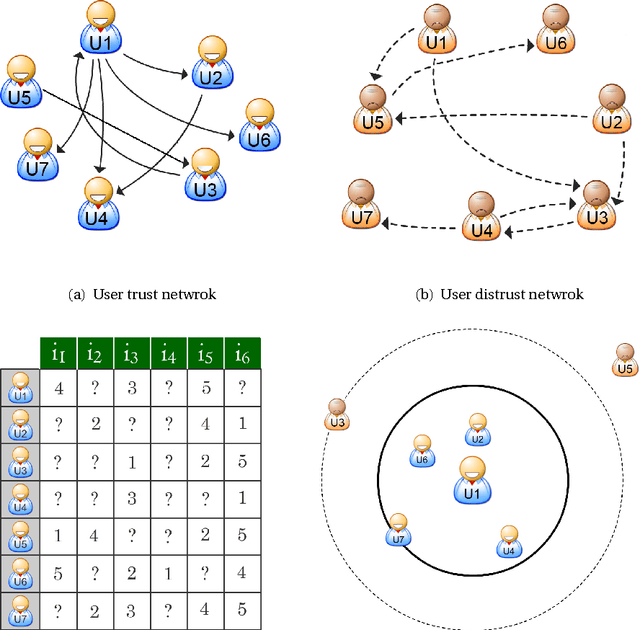
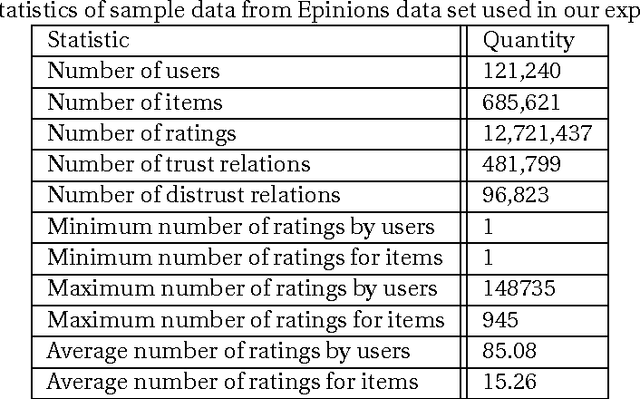
With the advent of online social networks, recommender systems have became crucial for the success of many online applications/services due to their significance role in tailoring these applications to user-specific needs or preferences. Despite their increasing popularity, in general recommender systems suffer from the data sparsity and the cold-start problems. To alleviate these issues, in recent years there has been an upsurge of interest in exploiting social information such as trust relations among users along with the rating data to improve the performance of recommender systems. The main motivation for exploiting trust information in recommendation process stems from the observation that the ideas we are exposed to and the choices we make are significantly influenced by our social context. However, in large user communities, in addition to trust relations, the distrust relations also exist between users. For instance, in Epinions the concepts of personal "web of trust" and personal "block list" allow users to categorize their friends based on the quality of reviews into trusted and distrusted friends, respectively. In this paper, we propose a matrix factorization based model for recommendation in social rating networks that properly incorporates both trust and distrust relationships aiming to improve the quality of recommendations and mitigate the data sparsity and the cold-start users issues. Through experiments on the Epinions data set, we show that our new algorithm outperforms its standard trust-enhanced or distrust-enhanced counterparts with respect to accuracy, thereby demonstrating the positive effect that incorporation of explicit distrust information can have on recommender systems.