 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimal Variance Sampling with Provable Guarantees for Fast Training of Graph Neural Networks
Paper and Code
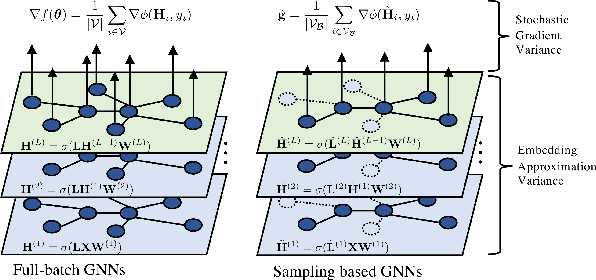

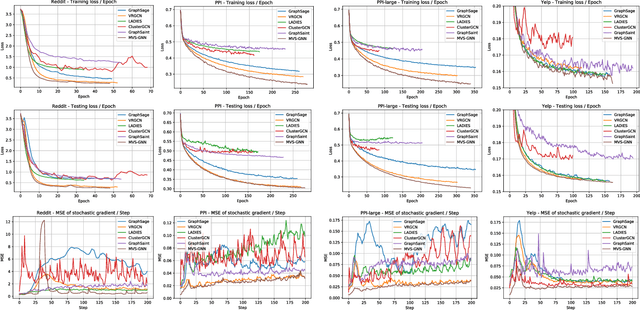

Sampling methods (e.g., node-wise, layer-wise, or subgraph) has become an indispensable strategy to speed up training large-scale Graph Neural Networks (GNNs). However, existing sampling methods are mostly based on the graph structural information and ignore the dynamicity of optimization, which leads to high variance in estimating the stochastic gradients. The high variance issue can be very pronounced in extremely large graphs, where it results in slow convergence and poor generalization. In this paper, we theoretically analyze the variance of sampling methods and show that, due to the composite structure of empirical risk, the variance of any sampling method can be decomposed into \textit{embedding approximation variance} in the forward stage and \textit{stochastic gradient variance} in the backward stage that necessities mitigating both types of variance to obtain faster convergence rate. We propose a decoupled variance reduction strategy that employs (approximate) gradient information to adaptively sample nodes with minimal variance, and explicitly reduces the variance introduced by embedding approximation. We show theoretically and empirically that the proposed method, even with smaller mini-batch sizes, enjoys a faster convergence rate and entails a better generalization compared to the existing methods.