 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation Graph Cross-Network Node Classification for Autism Detection Across Sample Groups
Jan 10, 2024Graph neural networks (GNN) are a powerful tool for combining imaging and non-imaging medical information for node classification tasks. Cross-network node classification extends GNN techniques to account for domain drift, allowing for node classification on an unlabeled target network. In this paper we present OTGCN, a powerful, novel approach to cross-network node classification. This approach leans on concepts from graph convolutional networks to harness insights from graph data structures while simultaneously applying strategies rooted in optimal transport to correct for the domain drift that can occur between samples from different data collection sites. This blended approach provides a practical solution for scenarios with many distinct forms of data collected across different locations and equipment. We demonstrate the effectiveness of this approach at classifying Autism Spectrum Disorder subjects using a blend of imaging and non-imaging data.
Fairness Perception from a Network-Centric Perspective
Oct 07, 2020
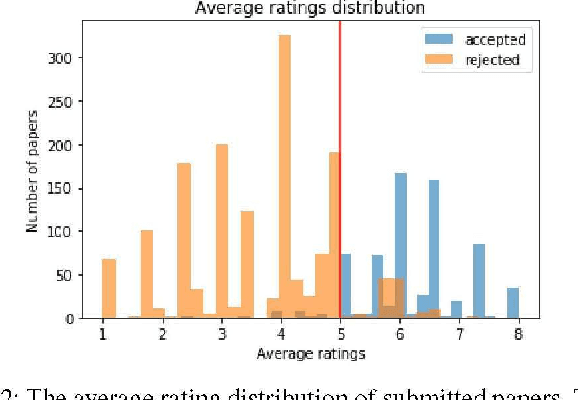
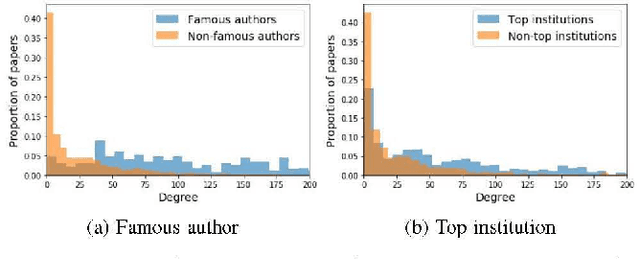

Algorithmic fairness is a major concern in recent years as the influence of machine learning algorithms becomes more widespread. In this paper, we investigate the issue of algorithmic fairness from a network-centric perspective. Specifically, we introduce a novel yet intuitive function known as network-centric fairness perception and provide an axiomatic approach to analyze its properties. Using a peer-review network as case study, we also examine its utility in terms of assessing the perception of fairness in paper acceptance decisions. We show how the function can be extended to a group fairness metric known as fairness visibility and demonstrate its relationship to demographic parity. We also illustrate a potential pitfall of the fairness visibility measure that can be exploited to mislead individuals into perceiving that the algorithmic decisions are fair. We demonstrate how the problem can be alleviated by increasing the local neighborhood size of the fairness perception function.
Semi-supervised Collaborative Ranking with Push at Top
Nov 17, 2015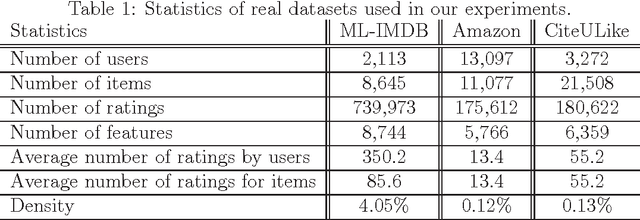



Existing collaborative ranking based recommender systems tend to perform best when there is enough observed ratings for each user and the observation is made completely at random. Under this setting recommender systems can properly suggest a list of recommendations according to the user interests. However, when the observed ratings are extremely sparse (e.g. in the case of cold-start users where no rating data is available), and are not sampled uniformly at random, existing ranking methods fail to effectively leverage side information to transduct the knowledge from existing ratings to unobserved ones. We propose a semi-supervised collaborative ranking model, dubbed \texttt{S$^2$COR}, to improve the quality of cold-start recommendation. \texttt{S$^2$COR} mitigates the sparsity issue by leveraging side information about both observed and missing ratings by collaboratively learning the ranking model. This enables it to deal with the case of missing data not at random, but to also effectively incorporate the available side information in transduction. We experimentally evaluated our proposed algorithm on a number of challenging real-world datasets and compared against state-of-the-art models for cold-start recommendation. We report significantly higher quality recommendations with our algorithm compared to the state-of-the-art.