 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFABLE: A Localized, Targeted Adversarial Attack on Weather Forecasting Models
May 17, 2025Deep learning-based weather forecasting models have recently demonstrated significant performance improvements over gold-standard physics-based simulation tools. However, these models are vulnerable to adversarial attacks, which raises concerns about their trustworthiness. In this paper, we first investigate the feasibility of applying existing adversarial attack methods to weather forecasting models. We argue that a successful attack should (1) not modify significantly its original inputs, (2) be faithful, i.e., achieve the desired forecast at targeted locations with minimal changes to non-targeted locations, and (3) be geospatio-temporally realistic. However, balancing these criteria is a challenge as existing methods are not designed to preserve the geospatio-temporal dependencies of the original samples. To address this challenge, we propose a novel framework called FABLE (Forecast Alteration By Localized targeted advErsarial attack), which employs a 3D discrete wavelet decomposition to extract the varying components of the geospatio-temporal data. By regulating the magnitude of adversarial perturbations across different components, FABLE can generate adversarial inputs that maintain geospatio-temporal coherence while remaining faithful and closely aligned with the original inputs. Experimental results on multiple real-world datasets demonstrate the effectiveness of our framework over baseline methods across various metrics.
Population Graph Cross-Network Node Classification for Autism Detection Across Sample Groups
Jan 10, 2024Graph neural networks (GNN) are a powerful tool for combining imaging and non-imaging medical information for node classification tasks. Cross-network node classification extends GNN techniques to account for domain drift, allowing for node classification on an unlabeled target network. In this paper we present OTGCN, a powerful, novel approach to cross-network node classification. This approach leans on concepts from graph convolutional networks to harness insights from graph data structures while simultaneously applying strategies rooted in optimal transport to correct for the domain drift that can occur between samples from different data collection sites. This blended approach provides a practical solution for scenarios with many distinct forms of data collected across different locations and equipment. We demonstrate the effectiveness of this approach at classifying Autism Spectrum Disorder subjects using a blend of imaging and non-imaging data.
DeepExtrema: A Deep Learning Approach for Forecasting Block Maxima in Time Series Data
May 05, 2022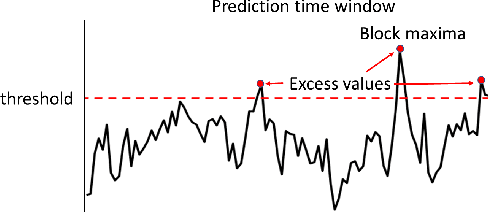

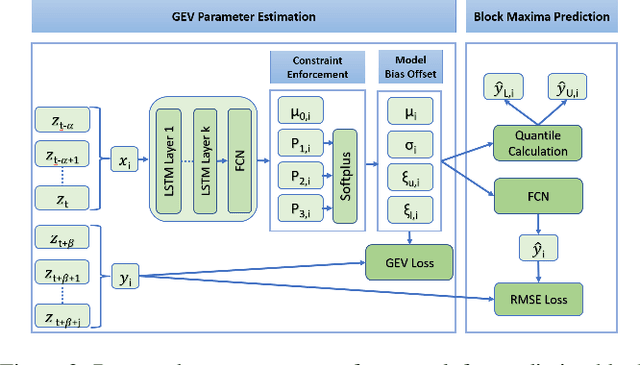
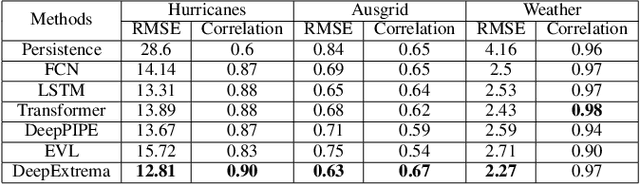
Accurate forecasting of extreme values in time series is critical due to the significant impact of extreme events on human and natural systems. This paper presents DeepExtrema, a novel framework that combines a deep neural network (DNN) with generalized extreme value (GEV) distribution to forecast the block maximum value of a time series. Implementing such a network is a challenge as the framework must preserve the inter-dependent constraints among the GEV model parameters even when the DNN is initialized. We describe our approach to address this challenge and present an architecture that enables both conditional mean and quantile prediction of the block maxima. The extensive experiments performed on both real-world and synthetic data demonstrated the superiority of DeepExtrema compared to other baseline methods.
COMET Flows: Towards Generative Modeling of Multivariate Extremes and Tail Dependence
May 02, 2022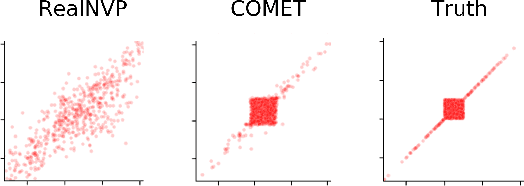
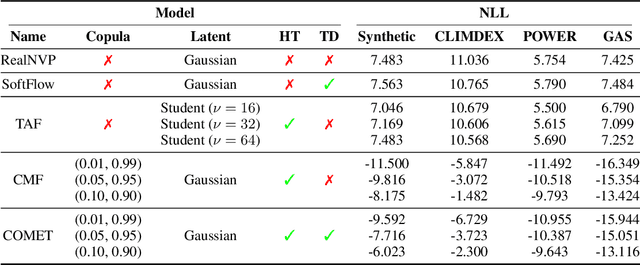

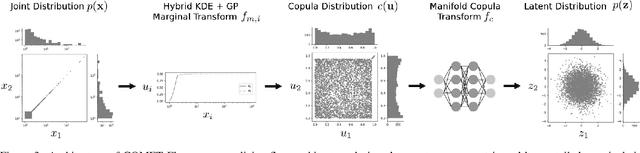
Normalizing flows, a popular class of deep generative models, often fail to represent extreme phenomena observed in real-world processes. In particular, existing normalizing flow architectures struggle to model multivariate extremes, characterized by heavy-tailed marginal distributions and asymmetric tail dependence among variables. In light of this shortcoming, we propose COMET (COpula Multivariate ExTreme) Flows, which decompose the process of modeling a joint distribution into two parts: (i) modeling its marginal distributions, and (ii) modeling its copula distribution. COMET Flows capture heavy-tailed marginal distributions by combining a parametric tail belief at extreme quantiles of the marginals with an empirical kernel density function at mid-quantiles. In addition, COMET Flows capture asymmetric tail dependence among multivariate extremes by viewing such dependence as inducing a low-dimensional manifold structure in feature space. Experimental results on both synthetic and real-world datasets demonstrate the effectiveness of COMET Flows in capturing both heavy-tailed marginals and asymmetric tail dependence compared to other state-of-the-art baseline architectures. All code is available on GitHub at https://github.com/andrewmcdonald27/COMETFlows.
Learning Deep Neural Networks under Agnostic Corrupted Supervision
Feb 12, 2021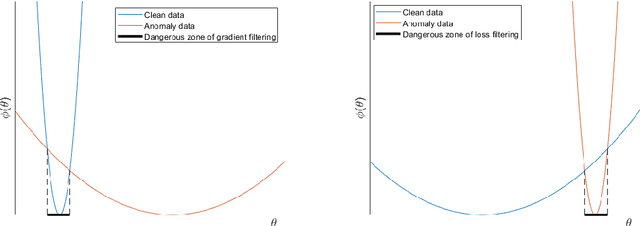
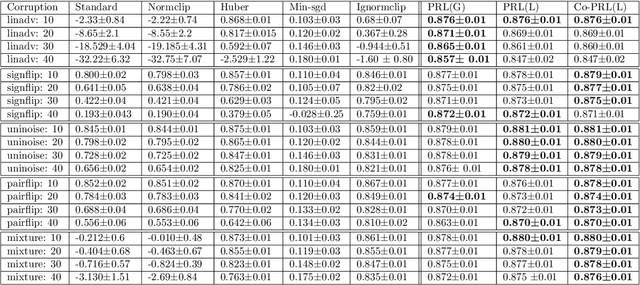

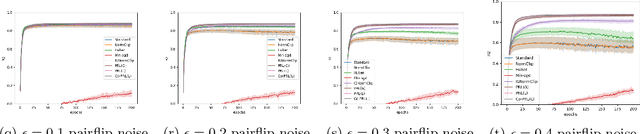
Training deep neural models in the presence of corrupted supervision is challenging as the corrupted data points may significantly impact the generalization performance. To alleviate this problem, we present an efficient robust algorithm that achieves strong guarantees without any assumption on the type of corruption and provides a unified framework for both classification and regression problems. Unlike many existing approaches that quantify the quality of the data points (e.g., based on their individual loss values), and filter them accordingly, the proposed algorithm focuses on controlling the collective impact of data points on the average gradient. Even when a corrupted data point failed to be excluded by our algorithm, the data point will have a very limited impact on the overall loss, as compared with state-of-the-art filtering methods based on loss values. Extensive experiments on multiple benchmark datasets have demonstrated the robustness of our algorithm under different types of corruption.
Fairness Perception from a Network-Centric Perspective
Oct 07, 2020
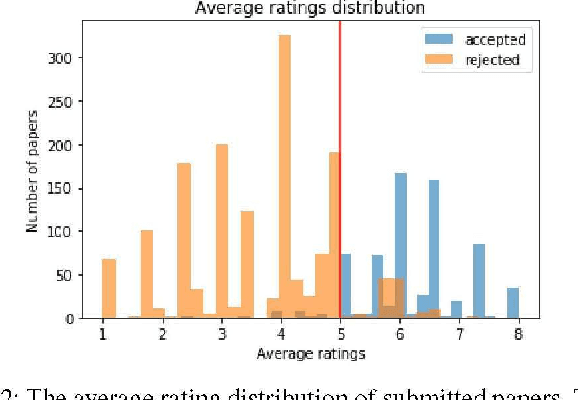
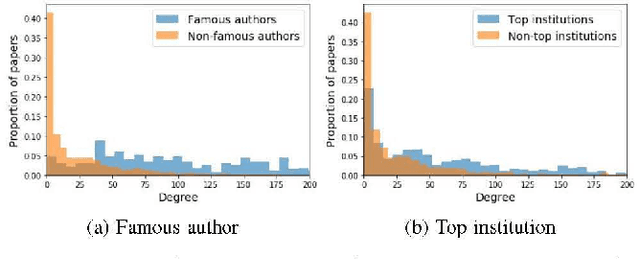

Algorithmic fairness is a major concern in recent years as the influence of machine learning algorithms becomes more widespread. In this paper, we investigate the issue of algorithmic fairness from a network-centric perspective. Specifically, we introduce a novel yet intuitive function known as network-centric fairness perception and provide an axiomatic approach to analyze its properties. Using a peer-review network as case study, we also examine its utility in terms of assessing the perception of fairness in paper acceptance decisions. We show how the function can be extended to a group fairness metric known as fairness visibility and demonstrate its relationship to demographic parity. We also illustrate a potential pitfall of the fairness visibility measure that can be exploited to mislead individuals into perceiving that the algorithmic decisions are fair. We demonstrate how the problem can be alleviated by increasing the local neighborhood size of the fairness perception function.
Spatially Constrained Spectral Clustering Algorithms for Region Delineation
May 21, 2019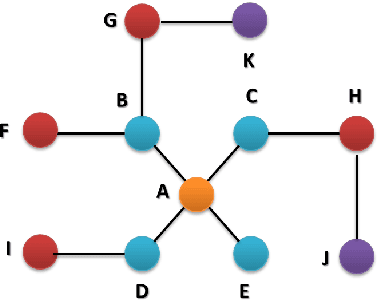
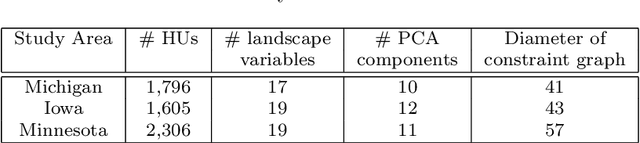
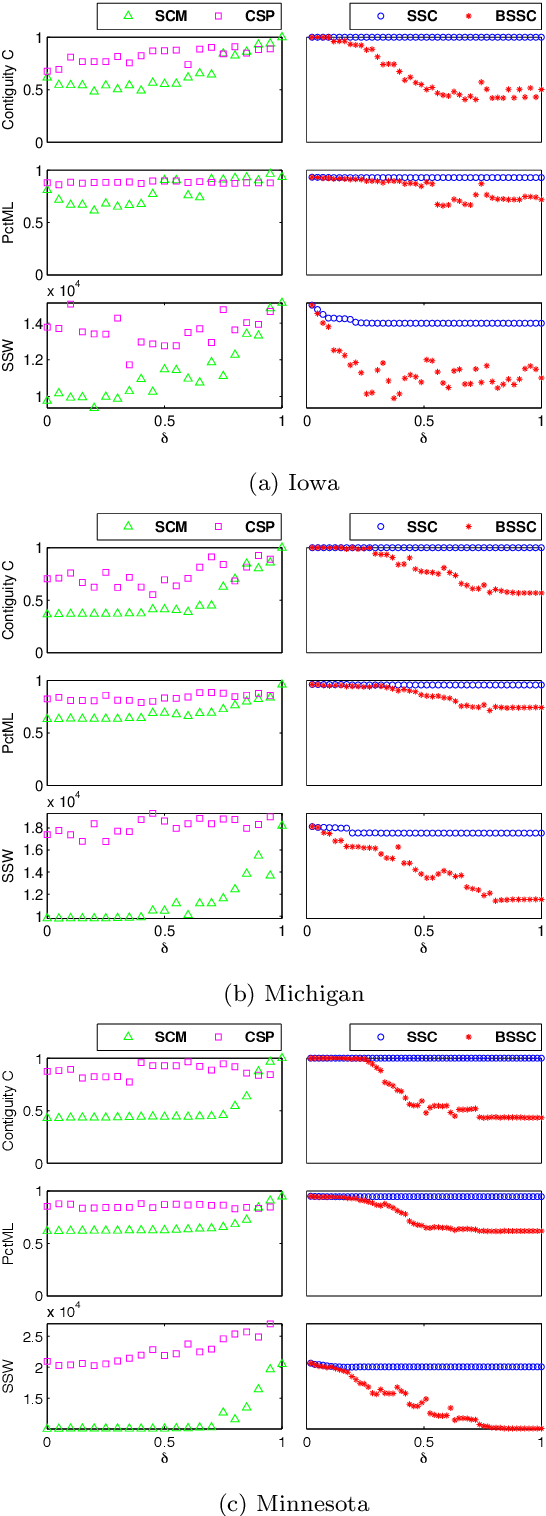

Regionalization is the task of dividing up a landscape into homogeneous patches with similar properties. Although this task has a wide range of applications, it has two notable challenges. First, it is assumed that the resulting regions are both homogeneous and spatially contiguous. Second, it is well-recognized that landscapes are hierarchical such that fine-scale regions are nested wholly within broader-scale regions. To address these two challenges, first, we develop a spatially constrained spectral clustering framework for region delineation that incorporates the tradeoff between region homogeneity and spatial contiguity. The framework uses a flexible, truncated exponential kernel to represent the spatial contiguity constraints, which is integrated with the landscape feature similarity matrix for region delineation. To address the second challenge, we extend the framework to create fine-scale regions that are nested within broader-scaled regions using a greedy, recursive bisection approach. We present a case study of a terrestrial ecology data set in the United States that compares the proposed framework with several baseline methods for regionalization. Experimental results suggest that the proposed framework for regionalization outperforms the baseline methods, especially in terms of balancing region contiguity and homogeneity, as well as creating regions of more similar size, which is often a desired trait of regions.