 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-Depth Study of Filter-Agnostic Vector Search on a PostgreSQL Database System: [Experiments and Analysis]
Mar 24, 2026Filtered Vector Search (FVS) is critical for supporting semantic search and GenAI applications in modern database systems. However, existing research most often evaluates algorithms in specialized libraries, making optimistic assumptions that do not align with enterprise-grade database systems. Our work challenges this premise by demonstrating that in a production-grade database system, commonly made assumptions do not hold, leading to performance characteristics and algorithmic trade-offs that are fundamentally different from those observed in isolated library settings. This paper presents the first in-depth analysis of filter-agnostic FVS algorithms within a production PostgreSQL-compatible system. We systematically evaluate post-filtering and inline-filtering strategies across a wide range of selectivities and correlations. Our central finding is that the optimal algorithm is not dictated by the cost of distance computations alone, but that system-level overheads that come from both distance computations and filter operations (like page accesses and data retrieval) play a significant role. We demonstrate that graph-based approaches (such as NaviX/ACORN) can incur prohibitive numbers of filter checks and system-level overheads, compared with clustering-based indexes such as ScaNN, often canceling out their theoretical benefits in real-world database environments. Ultimately, our findings provide the database community with crucial insights and practical guidelines, demonstrating that the optimal choice for a filter-agnostic FVS algorithm is not absolute, but rather a system-aware decision contingent on the interplay between workload characteristics and the underlying costs of data access in a real-world database architecture.
100x Cost & Latency Reduction: Performance Analysis of AI Query Approximation using Lightweight Proxy Models
Mar 16, 2026Several data warehouse and database providers have recently introduced extensions to SQL called AI Queries, enabling users to specify functions and conditions in SQL that are evaluated by LLMs, thereby broadening significantly the kinds of queries one can express over the combination of structured and unstructured data. LLMs offer remarkable semantic reasoning capabilities, making them an essential tool for complex and nuanced queries that blend structured and unstructured data. While extremely powerful, these AI queries can become prohibitively costly when invoked thousands of times. This paper provides an extensive evaluation of a recent AI query approximation approach that enables low cost analytics and database applications to benefit from AI queries. The approach delivers >100x cost and latency reduction for the semantic filter (AI.IF) operator and also important gains for semantic ranking (AI.RANK). The cost and performance gains come from utilizing cheap and accurate proxy models over embedding vectors. We show that despite the massive gains in latency and cost, these proxy models preserve accuracy and occasionally improve accuracy across various benchmark datasets, including the extended Amazon reviews benchmark that has 10M rows. We present an OLAP-friendly architecture within Google \textit{BigQuery} for this approach for purely online (ad hoc) queries, and a low-latency HTAP database-friendly architecture in \textit{AlloyDB} that could further improve the latency by moving the proxy model training offline. We present techniques that accelerate the proxy model training.
CardBench: A Benchmark for Learned Cardinality Estimation in Relational Databases
Aug 28, 2024Cardinality estimation is crucial for enabling high query performance in relational databases. Recently learned cardinality estimation models have been proposed to improve accuracy but there is no systematic benchmark or datasets which allows researchers to evaluate the progress made by new learned approaches and even systematically develop new learned approaches. In this paper, we are releasing a benchmark, containing thousands of queries over 20 distinct real-world databases for learned cardinality estimation. In contrast to other initial benchmarks, our benchmark is much more diverse and can be used for training and testing learned models systematically. Using this benchmark, we explored whether learned cardinality estimation can be transferred to an unseen dataset in a zero-shot manner. We trained GNN-based and transformer-based models to study the problem in three setups: 1-) instance-based, 2-) zero-shot, and 3-) fine-tuned. Our results show that while we get promising results for zero-shot cardinality estimation on simple single table queries; as soon as we add joins, the accuracy drops. However, we show that with fine-tuning, we can still utilize pre-trained models for cardinality estimation, significantly reducing training overheads compared to instance specific models. We are open sourcing our scripts to collect statistics, generate queries and training datasets to foster more extensive research, also from the ML community on the important problem of cardinality estimation and in particular improve on recent directions such as pre-trained cardinality estimation.
Medical Entity Disambiguation Using Graph Neural Networks
Apr 03, 2021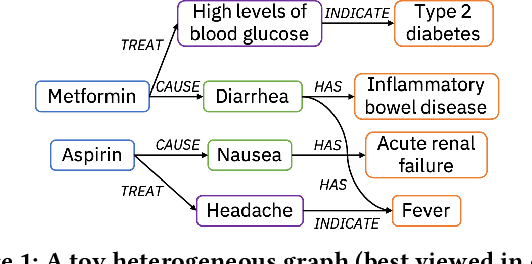
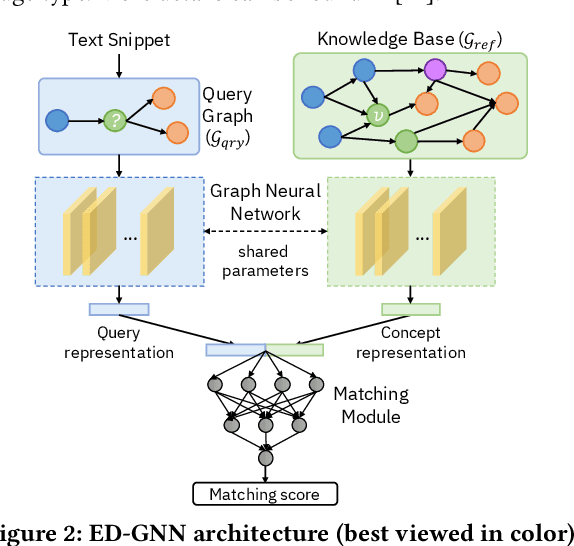
Medical knowledge bases (KBs), distilled from biomedical literature and regulatory actions, are expected to provide high-quality information to facilitate clinical decision making. Entity disambiguation (also referred to as entity linking) is considered as an essential task in unlocking the wealth of such medical KBs. However, existing medical entity disambiguation methods are not adequate due to word discrepancies between the entities in the KB and the text snippets in the source documents. Recently, graph neural networks (GNNs) have proven to be very effective and provide state-of-the-art results for many real-world applications with graph-structured data. In this paper, we introduce ED-GNN based on three representative GNNs (GraphSAGE, R-GCN, and MAGNN) for medical entity disambiguation. We develop two optimization techniques to fine-tune and improve ED-GNN. First, we introduce a novel strategy to represent entities that are mentioned in text snippets as a query graph. Second, we design an effective negative sampling strategy that identifies hard negative samples to improve the model's disambiguation capability. Compared to the best performing state-of-the-art solutions, our ED-GNN offers an average improvement of 7.3% in terms of F1 score on five real-world datasets.