 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper Logic Programs
Mar 30, 2002

The Autoepistemic Logic of Knowledge and Belief (AELB) is a powerful nonmonotic formalism introduced by Teodor Przymusinski in 1994. In this paper, we specialize it to a class of theories called `super logic programs'. We argue that these programs form a natural generalization of standard logic programs. In particular, they allow disjunctions and default negation of arbibrary positive objective formulas. Our main results are two new and powerful characterizations of the static semant ics of these programs, one syntactic, and one model-theoretic. The syntactic fixed point characterization is much simpler than the fixed point construction of the static semantics for arbitrary AELB theories. The model-theoretic characterization via Kripke models allows one to construct finite representations of the inherently infinite static expansions. Both characterizations can be used as the basis of algorithms for query answering under the static semantics. We describe a query-answering interpreter for super programs which we developed based on the model-theoretic characterization and which is available on the web.
Improving Performance of heavily loaded agents
Dec 11, 2000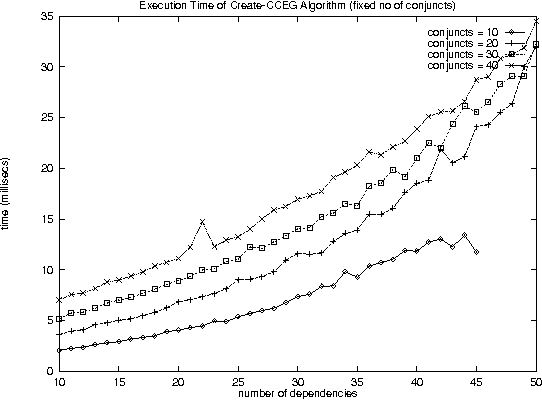
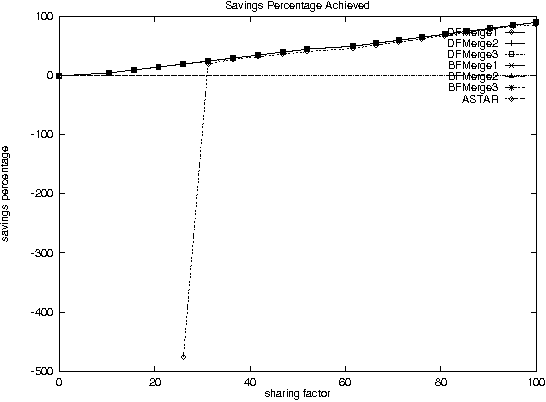
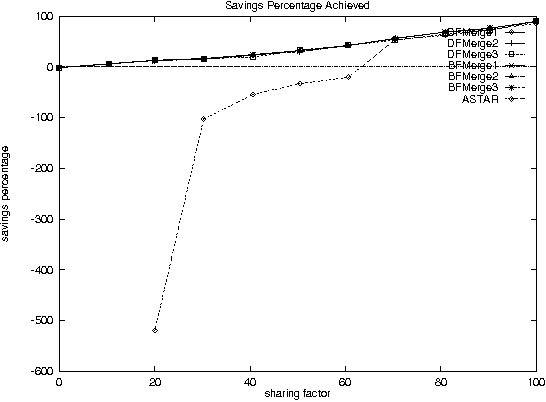
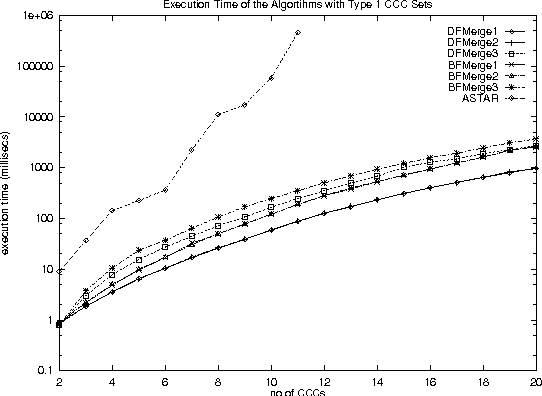
With the increase in agent-based applications, there are now agent systems that support \emph{concurrent} client accesses. The ability to process large volumes of simultaneous requests is critical in many such applications. In such a setting, the traditional approach of serving these requests one at a time via queues (e.g. \textsf{FIFO} queues, priority queues) is insufficient. Alternative models are essential to improve the performance of such \emph{heavily loaded} agents. In this paper, we propose a set of \emph{cost-based algorithms} to \emph{optimize} and \emph{merge} multiple requests submitted to an agent. In order to merge a set of requests, one first needs to identify commonalities among such requests. First, we provide an \emph{application independent framework} within which an agent developer may specify relationships (called \emph{invariants}) between requests. Second, we provide two algorithms (and various accompanying heuristics) which allow an agent to automatically rewrite requests so as to avoid redundant work---these algorithms take invariants associated with the agent into account. Our algorithms are independent of any specific agent framework. For an implementation, we implemented both these algorithms on top of the \impact agent development platform, and on top of a (non-\impact) geographic database agent. Based on these implementations, we conducted experiments and show that our algorithms are considerably more efficient than methods that use the $A^*$ algorithm.
Probabilistic Agent Programs
Oct 21, 1999
Agents are small programs that autonomously take actions based on changes in their environment or ``state.'' Over the last few years, there have been an increasing number of efforts to build agents that can interact and/or collaborate with other agents. In one of these efforts, Eiter, Subrahmanian amd Pick (AIJ, 108(1-2), pages 179-255) have shown how agents may be built on top of legacy code. However, their framework assumes that agent states are completely determined, and there is no uncertainty in an agent's state. Thus, their framework allows an agent developer to specify how his agents will react when the agent is 100% sure about what is true/false in the world state. In this paper, we propose the concept of a \emph{probabilistic agent program} and show how, given an arbitrary program written in any imperative language, we may build a declarative ``probabilistic'' agent program on top of it which supports decision making in the presence of uncertainty. We provide two alternative semantics for probabilistic agent programs. We show that the second semantics, though more epistemically appealing, is more complex to compute. We provide sound and complete algorithms to compute the semantics of \emph{positive} agent programs.