 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Aware Network Architecture Search and Compression for Efficient Knowledge Transfer
May 12, 2022
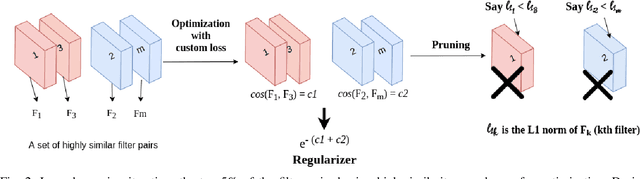

Transfer Learning enables Convolutional Neural Networks (CNN) to acquire knowledge from a source domain and transfer it to a target domain, where collecting large-scale annotated examples is both time-consuming and expensive. Conventionally, while transferring the knowledge learned from one task to another task, the deeper layers of a pre-trained CNN are finetuned over the target dataset. However, these layers that are originally designed for the source task are over-parameterized for the target task. Thus, finetuning these layers over the target dataset reduces the generalization ability of the CNN due to high network complexity. To tackle this problem, we propose a two-stage framework called TASCNet which enables efficient knowledge transfer. In the first stage, the configuration of the deeper layers is learned automatically and finetuned over the target dataset. Later, in the second stage, the redundant filters are pruned from the fine-tuned CNN to decrease the network's complexity for the target task while preserving the performance. This two-stage mechanism finds a compact version of the pre-trained CNN with optimal structure (number of filters in a convolutional layer, number of neurons in a dense layer, and so on) from the hypothesis space. The efficacy of the proposed method is evaluated using VGG-16, ResNet-50, and DenseNet-121 on CalTech-101, CalTech-256, and Stanford Dogs datasets. The proposed TASCNet reduces the computational complexity of pre-trained CNNs over the target task by reducing both trainable parameters and FLOPs which enables resource-efficient knowledge transfer.
AutoTune: Automatically Tuning Convolutional Neural Networks for Improved Transfer Learning
Apr 25, 2020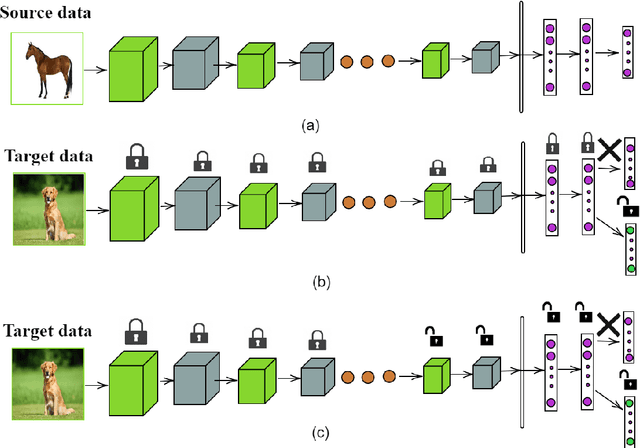
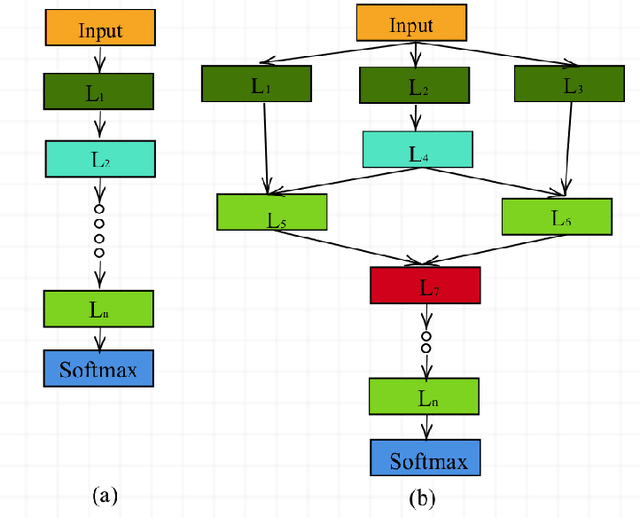
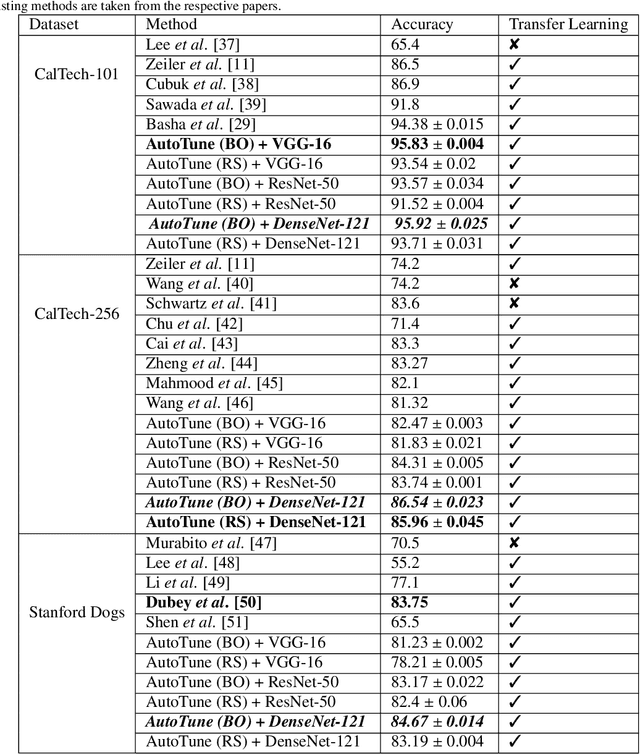
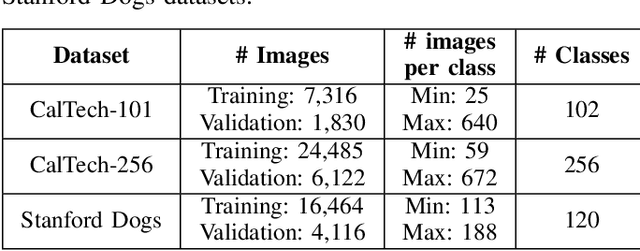
Transfer learning enables solving a specific task having limited data by using the pre-trained deep networks trained on large-scale datasets. Typically, while transferring the learned knowledge from source task to the target task, the last few layers are fine-tuned (re-trained) over the target dataset. However, these layers are originally designed for the source task which might not be suitable for the target task. In this paper, we introduce a mechanism for automatically tuning the Convolutional Neural Networks (CNN) for improved transfer learning. The CNN layers are tuned with the knowledge from target data using Bayesian Optimization. Initially, we train the final layer of the base CNN model by replacing the number of neurons in the softmax layer with the number of classes involved in the target task. Next, the CNN is tuned automatically by observing the classification performance on the validation data (greedy criteria). To evaluate the performance of the proposed method, experiments are conducted on three benchmark datasets, e.g., CalTech-101, CalTech-256, and Stanford Dogs. The classification results obtained through the proposed AutoTune method outperforms the standard baseline transfer learning methods over the three datasets by achieving $95.92\%$, $86.54\%$, and $84.67\%$ accuracy over CalTech-101, CalTech-256, and Stanford Dogs, respectively. The experimental results obtained in this study depict that tuning of the pre-trained CNN layers with the knowledge from the target dataset confesses better transfer learning ability.
AutoFCL: Automatically Tuning Fully Connected Layers for Transfer Learning
Feb 05, 2020

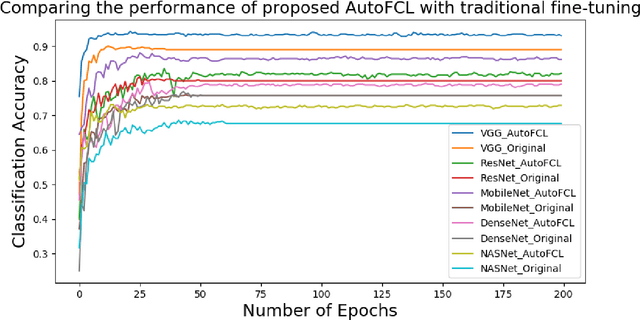
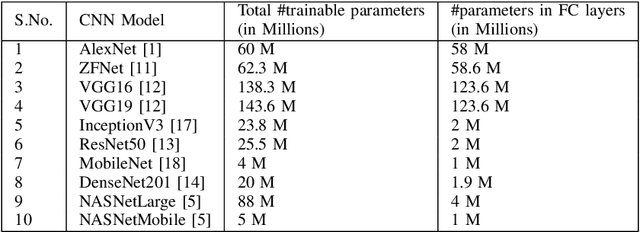
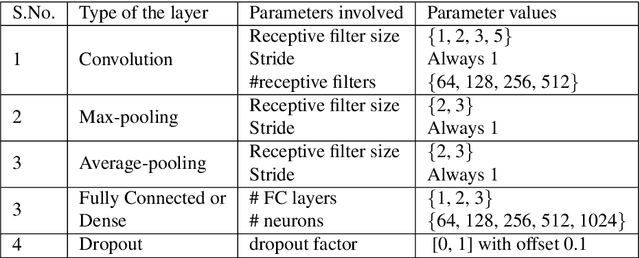
Deep Convolutional Neural Networks (CNN) have evolved as popular machine learning models for image classification during the past few years, due to their ability to learn the problem-specific features directly from the input images. The success of deep learning models solicits architecture engineering rather than hand-engineering the features. However, designing state-of-the-art CNN for a given task remains a non-trivial and challenging task. While transferring the learned knowledge from one task to another, fine-tuning with the target-dependent fully connected layers produces better results over the target task. In this paper, the proposed AutoFCL model attempts to learn the structure of Fully Connected (FC) layers of a CNN automatically using Bayesian optimization. To evaluate the performance of the proposed AutoFCL, we utilize five popular CNN models such as VGG-16, ResNet, DenseNet, MobileNet, and NASNetMobile. The experiments are conducted on three benchmark datasets, namely CalTech-101, Oxford-102 Flowers, and UC Merced Land Use datasets. Fine-tuning the newly learned (target-dependent) FC layers leads to state-of-the-art performance, according to the experiments carried out in this research. The proposed AutoFCL method outperforms the existing methods over CalTech-101 and Oxford-102 Flowers datasets by achieving the accuracy of 94.38% and 98.89%, respectively. However, our method achieves comparable performance on the UC Merced Land Use dataset with 96.83% accuracy.