 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Aware Network Architecture Search and Compression for Efficient Knowledge Transfer
Paper and Code
May 12, 2022
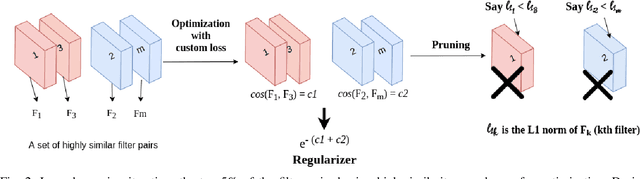

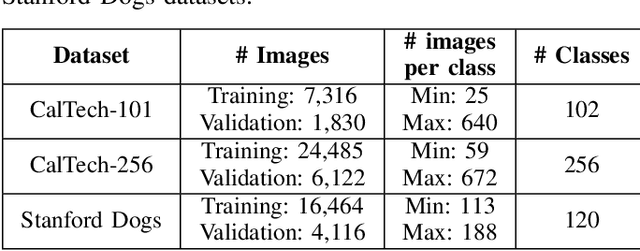
Transfer Learning enables Convolutional Neural Networks (CNN) to acquire knowledge from a source domain and transfer it to a target domain, where collecting large-scale annotated examples is both time-consuming and expensive. Conventionally, while transferring the knowledge learned from one task to another task, the deeper layers of a pre-trained CNN are finetuned over the target dataset. However, these layers that are originally designed for the source task are over-parameterized for the target task. Thus, finetuning these layers over the target dataset reduces the generalization ability of the CNN due to high network complexity. To tackle this problem, we propose a two-stage framework called TASCNet which enables efficient knowledge transfer. In the first stage, the configuration of the deeper layers is learned automatically and finetuned over the target dataset. Later, in the second stage, the redundant filters are pruned from the fine-tuned CNN to decrease the network's complexity for the target task while preserving the performance. This two-stage mechanism finds a compact version of the pre-trained CNN with optimal structure (number of filters in a convolutional layer, number of neurons in a dense layer, and so on) from the hypothesis space. The efficacy of the proposed method is evaluated using VGG-16, ResNet-50, and DenseNet-121 on CalTech-101, CalTech-256, and Stanford Dogs datasets. The proposed TASCNet reduces the computational complexity of pre-trained CNNs over the target task by reducing both trainable parameters and FLOPs which enables resource-efficient knowledge transfer.