 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Uncertainty and Diversity of Samples: Leveraging Diversity of Least, High Confidence Samples for Effective Active Learning
May 21, 2026Deep learning models, including Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), have achieved state-of-the-art performance on various computer vision tasks such as object classification, detection, segmentation, generation, and many more. However, these models are data-hungry as they require more training data to learn millions or billions of parameters. Especially for supervised learning tasks, curating a large number of labeled samples for model training is an expensive and time-consuming task. Active Learning (AL) has been used to address this problem for many years. Existing active learning methods aim at choosing the samples for annotation from a pool of unlabeled samples that are either diverse or uncertain. Choosing such samples may hinder the model's performance as we pool based on one dimension, i.e., either diverse or uncertain. In this paper, we propose four novel hybrid sampling methods for pooling both easy and hard samples, which are also diverse. To verify the efficacy of the proposed methods, extensive experiments are conducted using high and low-confidence samples separately. We observe from our experiments that the proposed hybrid sampling method, Least Confident and Diverse (LCD), consistently performs better compared to state-of-the-art methods. It is observed that selecting uncertain and diverse instances helps the model learn more distinct features. The codes related to this study will be available at https://github.com/XXX/LCD.
Detection of Virus and Small Cell Patches in Foci Images Using Switchable Convolution and Feature Pyramid Networks
May 21, 2026Accurate detection and counting of virus patches in focus-forming unit (FFU) images, also known as foci images, are important for quantifying viral infection and analyzing cellular structures. This task is challenging because biomedical targets often vary substantially in size, density, contrast, and shape. In this paper, we propose an enhanced YOLOv2-based detector that integrates a Feature Pyramid Network (FPN) to improve multi-scale feature representation. We also incorporate a switchable atrous convolution mechanism to adapt the receptive field for fine-grained targets in dense microscopy images. The proposed method is evaluated on biomedical foci image datasets for virus patch and small cell patch detection. For small cell patch detection, the model achieves a mean average precision (mAP) of 40.5% at a 25% Intersection over Union (IoU) threshold. For FFU virus patch detection, the model achieves an mAP of 68%. These results indicate that combining FPN-based feature fusion with switchable convolution improves the suitability of YOLOv2 for specialized biomedical object detection tasks
Plantation Monitoring Using Drone Images: A Dataset and Performance Review
Feb 12, 2025Automatic monitoring of tree plantations plays a crucial role in agriculture. Flawless monitoring of tree health helps farmers make informed decisions regarding their management by taking appropriate action. Use of drone images for automatic plantation monitoring can enhance the accuracy of the monitoring process, while still being affordable to small farmers in developing countries such as India. Small, low cost drones equipped with an RGB camera can capture high-resolution images of agricultural fields, allowing for detailed analysis of the well-being of the plantations. Existing methods of automated plantation monitoring are mostly based on satellite images, which are difficult to get for the farmers. We propose an automated system for plantation health monitoring using drone images, which are becoming easier to get for the farmers. We propose a dataset of images of trees with three categories: ``Good health", ``Stunted", and ``Dead". We annotate the dataset using CVAT annotation tool, for use in research purposes. We experiment with different well-known CNN models to observe their performance on the proposed dataset. The initial low accuracy levels show the complexity of the proposed dataset. Further, our study revealed that, depth-wise convolution operation embedded in a deep CNN model, can enhance the performance of the model on drone dataset. Further, we apply state-of-the-art object detection models to identify individual trees to better monitor them automatically.
UnSeGArmaNet: Unsupervised Image Segmentation using Graph Neural Networks with Convolutional ARMA Filters
Oct 08, 2024



The data-hungry approach of supervised classification drives the interest of the researchers toward unsupervised approaches, especially for problems such as medical image segmentation, where labeled data are difficult to get. Motivated by the recent success of Vision transformers (ViT) in various computer vision tasks, we propose an unsupervised segmentation framework with a pre-trained ViT. Moreover, by harnessing the graph structure inherent within the image, the proposed method achieves a notable performance in segmentation, especially in medical images. We further introduce a modularity-based loss function coupled with an Auto-Regressive Moving Average (ARMA) filter to capture the inherent graph topology within the image. Finally, we observe that employing Scaled Exponential Linear Unit (SELU) and SILU (Swish) activation functions within the proposed Graph Neural Network (GNN) architecture enhances the performance of segmentation. The proposed method provides state-of-the-art performance (even comparable to supervised methods) on benchmark image segmentation datasets such as ECSSD, DUTS, and CUB, as well as challenging medical image segmentation datasets such as KVASIR, CVC-ClinicDB, ISIC-2018. The github repository of the code is available on \url{https://github.com/ksgr5566/UnSeGArmaNet}.
WSD: Wild Selfie Dataset for Face Recognition in Selfie Images
Feb 14, 2023



With the rise of handy smart phones in the recent years, the trend of capturing selfie images is observed. Hence efficient approaches are required to be developed for recognising faces in selfie images. Due to the short distance between the camera and face in selfie images, and the different visual effects offered by the selfie apps, face recognition becomes more challenging with existing approaches. A dataset is needed to be developed to encourage the study to recognize faces in selfie images. In order to alleviate this problem and to facilitate the research on selfie face images, we develop a challenging Wild Selfie Dataset (WSD) where the images are captured from the selfie cameras of different smart phones, unlike existing datasets where most of the images are captured in controlled environment. The WSD dataset contains 45,424 images from 42 individuals (i.e., 24 female and 18 male subjects), which are divided into 40,862 training and 4,562 test images. The average number of images per subject is 1,082 with minimum and maximum number of images for any subject are 518 and 2,634, respectively. The proposed dataset consists of several challenges, including but not limited to augmented reality filtering, mirrored images, occlusion, illumination, scale, expressions, view-point, aspect ratio, blur, partial faces, rotation, and alignment. We compare the proposed dataset with existing benchmark datasets in terms of different characteristics. The complexity of WSD dataset is also observed experimentally, where the performance of the existing state-of-the-art face recognition methods is poor on WSD dataset, compared to the existing datasets. Hence, the proposed WSD dataset opens up new challenges in the area of face recognition and can be beneficial to the community to study the specific challenges related to selfie images and develop improved methods for face recognition in selfie images.
DFW-PP: Dynamic Feature Weighting based Popularity Prediction for Social Media Content
Oct 16, 2021
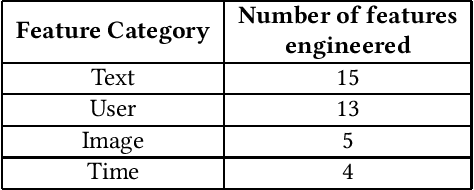
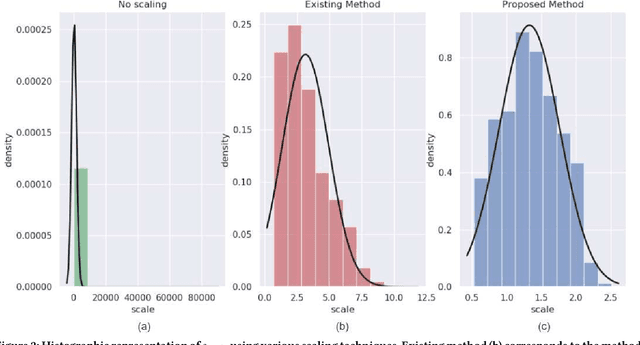

The increasing popularity of social media platforms makes it important to study user engagement, which is a crucial aspect of any marketing strategy or business model. The over-saturation of content on social media platforms has persuaded us to identify the important factors that affect content popularity. This comes from the fact that only an iota of the humongous content available online receives the attention of the target audience. Comprehensive research has been done in the area of popularity prediction using several Machine Learning techniques. However, we observe that there is still significant scope for improvement in analyzing the social importance of media content. We propose the DFW-PP framework, to learn the importance of different features that vary over time. Further, the proposed method controls the skewness of the distribution of the features by applying a log-log normalization. The proposed method is experimented with a benchmark dataset, to show promising results. The code will be made publicly available at https://github.com/chaitnayabasava/DFW-PP.
Deep Model Compression based on the Training History
Jan 30, 2021
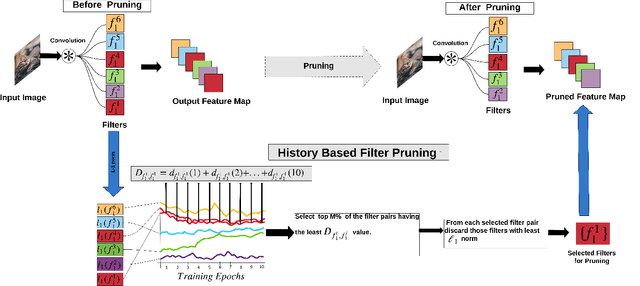
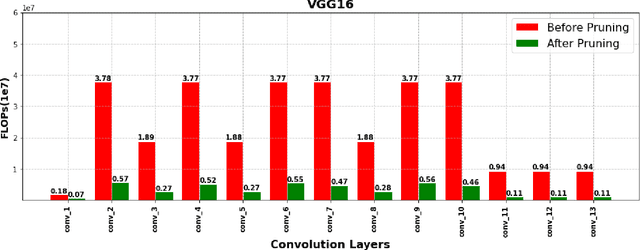
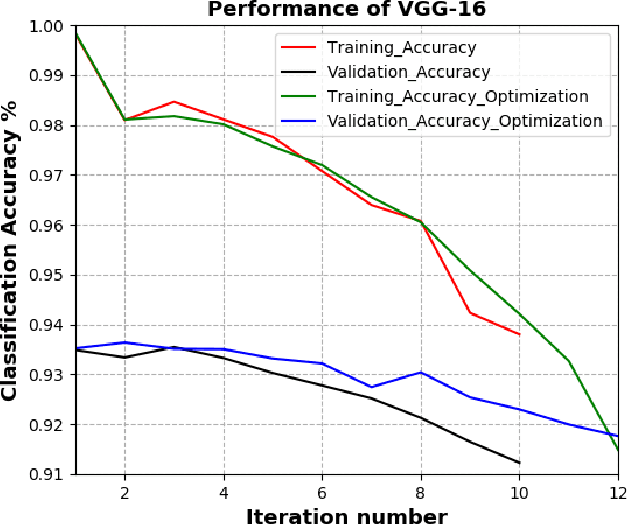
Deep Convolutional Neural Networks (DCNNs) have shown promising results in several visual recognition problems which motivated the researchers to propose popular architectures such as LeNet, AlexNet, VGGNet, ResNet, and many more. These architectures come at a cost of high computational complexity and parameter storage. To get rid of storage and computational complexity, deep model compression methods have been evolved. We propose a novel History Based Filter Pruning (HBFP) method that utilizes network training history for filter pruning. Specifically, we prune the redundant filters by observing similar patterns in the L1-norms of filters (absolute sum of weights) over the training epochs. We iteratively prune the redundant filters of a CNN in three steps. First, we train the model and select the filter pairs with redundant filters in each pair. Next, we optimize the network to increase the similarity between the filters in a pair. It facilitates us to prune one filter from each pair based on its importance without much information loss. Finally, we retrain the network to regain the performance, which is dropped due to filter pruning. We test our approach on popular architectures such as LeNet-5 on MNIST dataset and VGG-16, ResNet-56, and ResNet-110 on CIFAR-10 dataset. The proposed pruning method outperforms the state-of-the-art in terms of FLOPs reduction (floating-point operations) by 97.98%, 83.42%, 78.43%, and 74.95% for LeNet-5, VGG-16, ResNet-56, and ResNet-110 models, respectively, while maintaining the less error rate.
MERANet: Facial Micro-Expression Recognition using 3D Residual Attention Network
Dec 07, 2020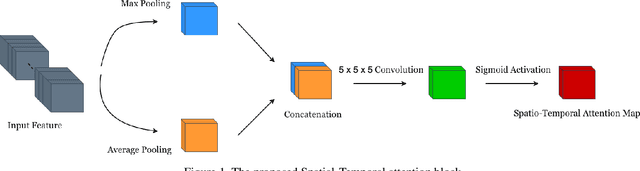
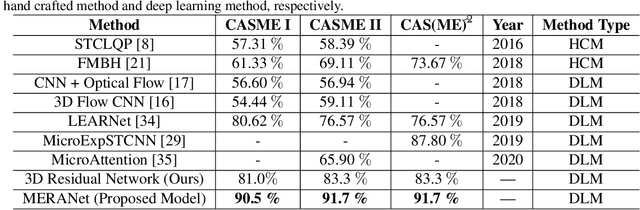

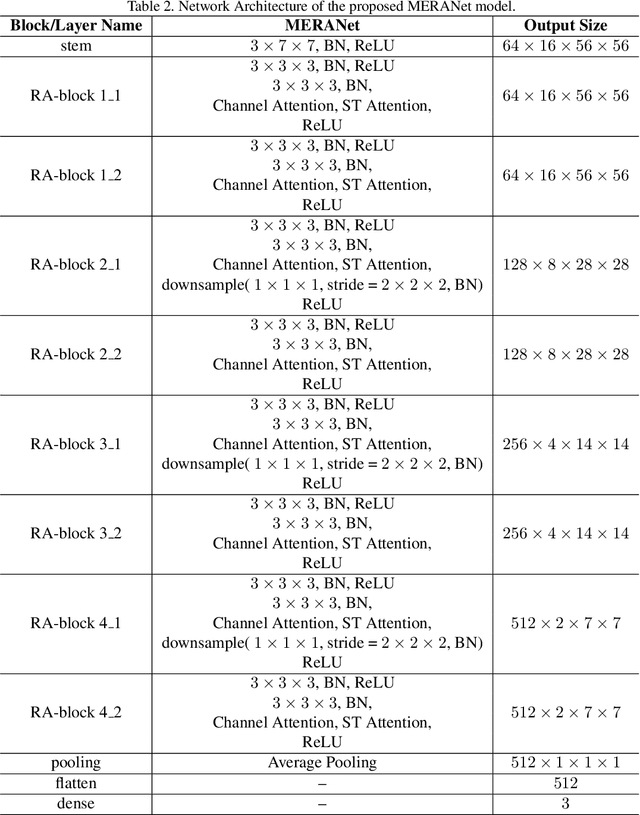
We propose a facial micro-expression recognition model using 3D residual attention network called MERANet. The proposed model takes advantage of spatial-temporal attention and channel attention together, to learn deeper fine-grained subtle features for classification of emotions. The proposed model also encompasses both spatial and temporal information simultaneously using the 3D kernels and residual connections. Moreover, the channel features and spatio-temporal features are re-calibrated using the channel and spatio-temporal attentions, respectively in each residual module. The experiments are conducted on benchmark facial micro-expression datasets. A superior performance is observed as compared to the state-of-the-art for facial micro-expression recognition.
AutoTune: Automatically Tuning Convolutional Neural Networks for Improved Transfer Learning
Apr 25, 2020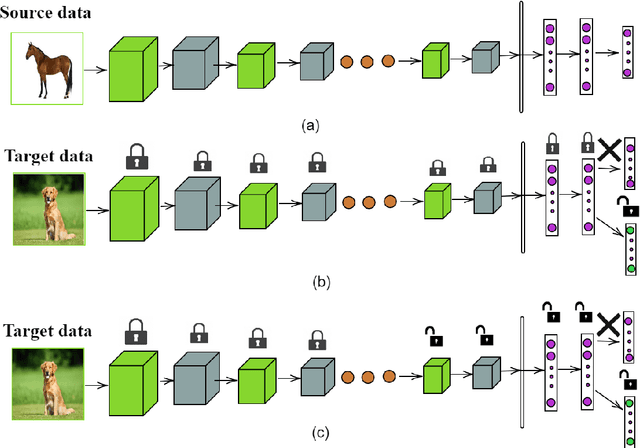
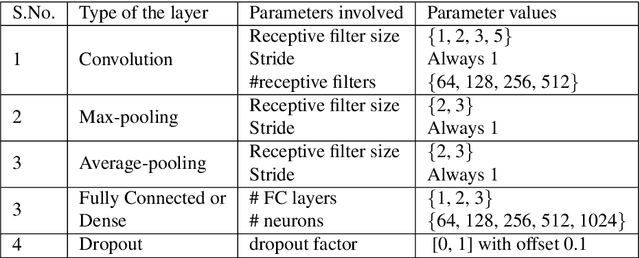
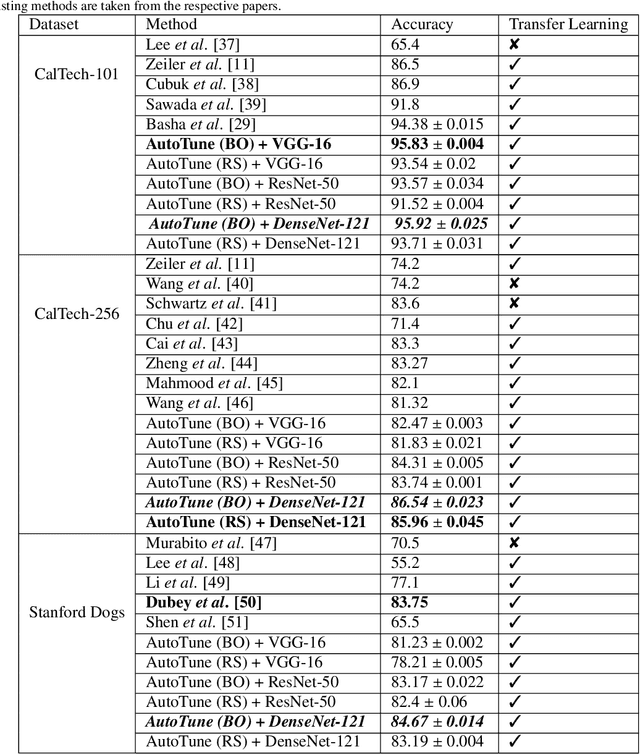
Transfer learning enables solving a specific task having limited data by using the pre-trained deep networks trained on large-scale datasets. Typically, while transferring the learned knowledge from source task to the target task, the last few layers are fine-tuned (re-trained) over the target dataset. However, these layers are originally designed for the source task which might not be suitable for the target task. In this paper, we introduce a mechanism for automatically tuning the Convolutional Neural Networks (CNN) for improved transfer learning. The CNN layers are tuned with the knowledge from target data using Bayesian Optimization. Initially, we train the final layer of the base CNN model by replacing the number of neurons in the softmax layer with the number of classes involved in the target task. Next, the CNN is tuned automatically by observing the classification performance on the validation data (greedy criteria). To evaluate the performance of the proposed method, experiments are conducted on three benchmark datasets, e.g., CalTech-101, CalTech-256, and Stanford Dogs. The classification results obtained through the proposed AutoTune method outperforms the standard baseline transfer learning methods over the three datasets by achieving $95.92\%$, $86.54\%$, and $84.67\%$ accuracy over CalTech-101, CalTech-256, and Stanford Dogs, respectively. The experimental results obtained in this study depict that tuning of the pre-trained CNN layers with the knowledge from the target dataset confesses better transfer learning ability.
An Information-rich Sampling Technique over Spatio-Temporal CNN for Classification of Human Actions in Videos
Feb 07, 2020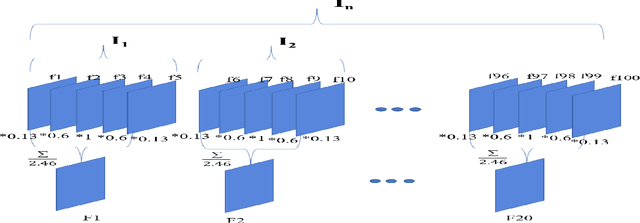
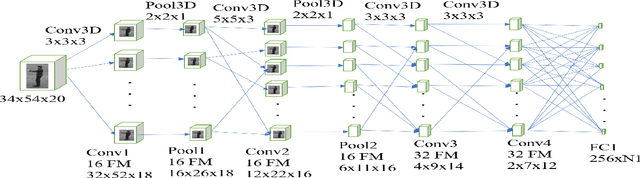
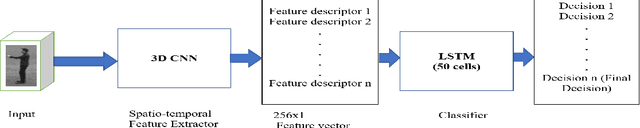
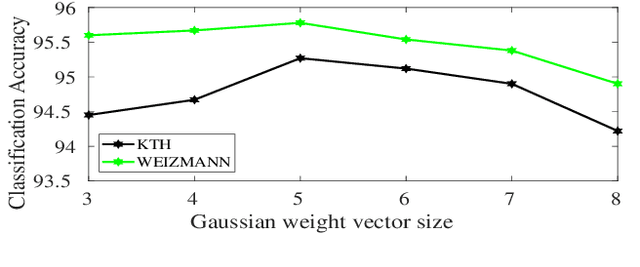
We propose a novel scheme for human action recognition in videos, using a 3-dimensional Convolutional Neural Network (3D CNN) based classifier. Traditionally in deep learning based human activity recognition approaches, either a few random frames or every $k^{th}$ frame of the video is considered for training the 3D CNN, where $k$ is a small positive integer, like 4, 5, or 6. This kind of sampling reduces the volume of the input data, which speeds-up training of the network and also avoids over-fitting to some extent, thus enhancing the performance of the 3D CNN model. In the proposed video sampling technique, consecutive $k$ frames of a video are aggregated into a single frame by computing a Gaussian-weighted summation of the $k$ frames. The resulting frame (aggregated frame) preserves the information in a better way than the conventional approaches and experimentally shown to perform better. In this paper, a 3D CNN architecture is proposed to extract the spatio-temporal features and follows Long Short-Term Memory (LSTM) to recognize human actions. The proposed 3D CNN architecture is capable of handling the videos where the camera is placed at a distance from the performer. Experiments are performed with KTH and WEIZMANN human actions datasets, whereby it is shown to produce comparable results with the state-of-the-art techniques.