 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-rich Sampling Technique over Spatio-Temporal CNN for Classification of Human Actions in Videos
Paper and Code
Feb 07, 2020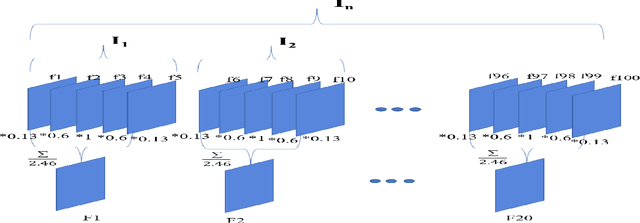
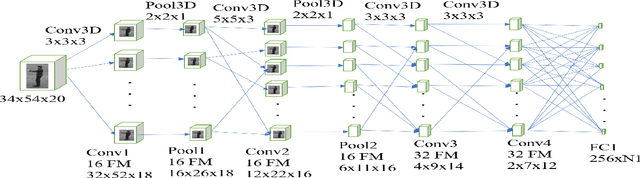
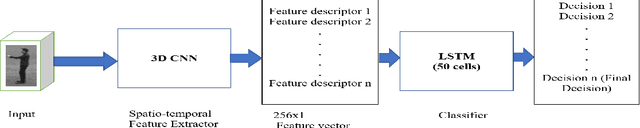
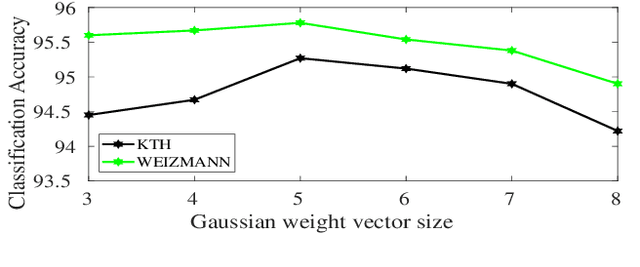
We propose a novel scheme for human action recognition in videos, using a 3-dimensional Convolutional Neural Network (3D CNN) based classifier. Traditionally in deep learning based human activity recognition approaches, either a few random frames or every $k^{th}$ frame of the video is considered for training the 3D CNN, where $k$ is a small positive integer, like 4, 5, or 6. This kind of sampling reduces the volume of the input data, which speeds-up training of the network and also avoids over-fitting to some extent, thus enhancing the performance of the 3D CNN model. In the proposed video sampling technique, consecutive $k$ frames of a video are aggregated into a single frame by computing a Gaussian-weighted summation of the $k$ frames. The resulting frame (aggregated frame) preserves the information in a better way than the conventional approaches and experimentally shown to perform better. In this paper, a 3D CNN architecture is proposed to extract the spatio-temporal features and follows Long Short-Term Memory (LSTM) to recognize human actions. The proposed 3D CNN architecture is capable of handling the videos where the camera is placed at a distance from the performer. Experiments are performed with KTH and WEIZMANN human actions datasets, whereby it is shown to produce comparable results with the state-of-the-art techniques.