 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Uniform Illumination Attack for Fooling Convolutional Neural Networks
Sep 05, 2024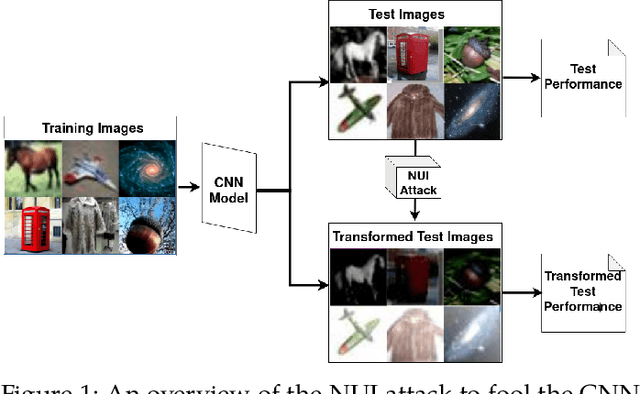
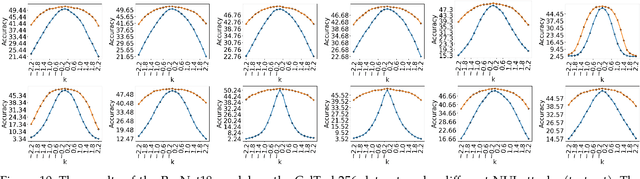
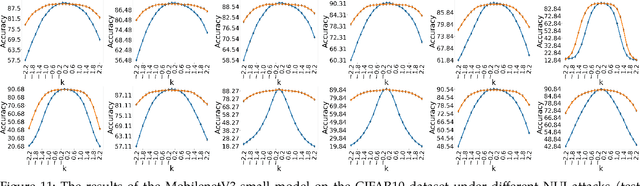
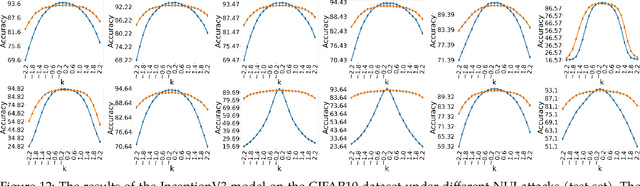
Convolutional Neural Networks (CNNs) have made remarkable strides; however, they remain susceptible to vulnerabilities, particularly in the face of minor image perturbations that humans can easily recognize. This weakness, often termed as 'attacks', underscores the limited robustness of CNNs and the need for research into fortifying their resistance against such manipulations. This study introduces a novel Non-Uniform Illumination (NUI) attack technique, where images are subtly altered using varying NUI masks. Extensive experiments are conducted on widely-accepted datasets including CIFAR10, TinyImageNet, and CalTech256, focusing on image classification with 12 different NUI attack models. The resilience of VGG, ResNet, MobilenetV3-small and InceptionV3 models against NUI attacks are evaluated. Our results show a substantial decline in the CNN models' classification accuracy when subjected to NUI attacks, indicating their vulnerability under non-uniform illumination. To mitigate this, a defense strategy is proposed, including NUI-attacked images, generated through the new NUI transformation, into the training set. The results demonstrate a significant enhancement in CNN model performance when confronted with perturbed images affected by NUI attacks. This strategy seeks to bolster CNN models' resilience against NUI attacks.
AdaNorm: Adaptive Gradient Norm Correction based Optimizer for CNNs
Oct 12, 2022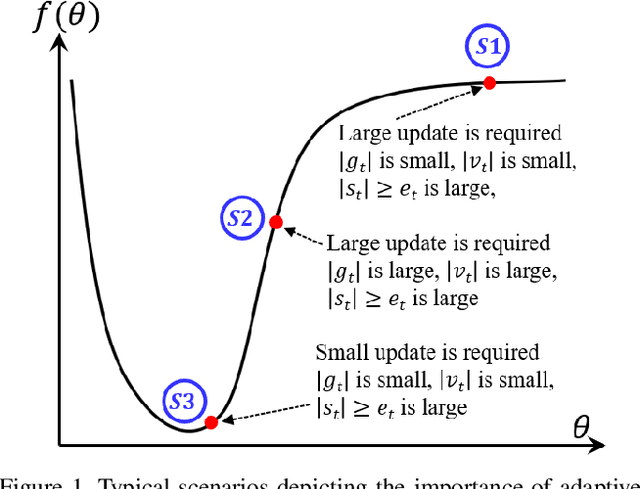
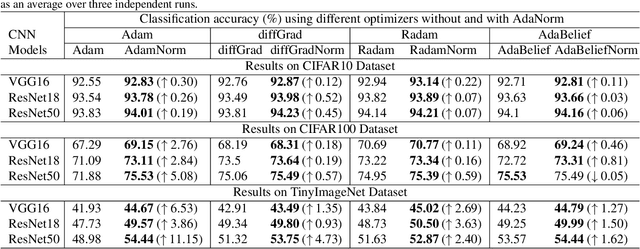
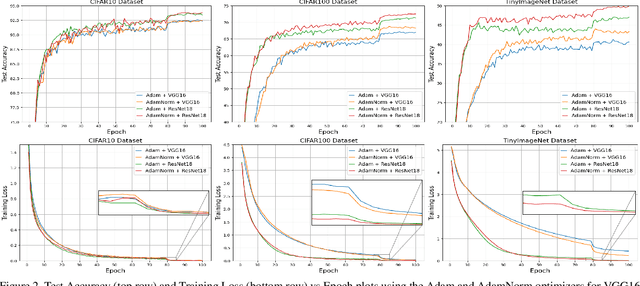

The stochastic gradient descent (SGD) optimizers are generally used to train the convolutional neural networks (CNNs). In recent years, several adaptive momentum based SGD optimizers have been introduced, such as Adam, diffGrad, Radam and AdaBelief. However, the existing SGD optimizers do not exploit the gradient norm of past iterations and lead to poor convergence and performance. In this paper, we propose a novel AdaNorm based SGD optimizers by correcting the norm of gradient in each iteration based on the adaptive training history of gradient norm. By doing so, the proposed optimizers are able to maintain high and representive gradient throughout the training and solves the low and atypical gradient problems. The proposed concept is generic and can be used with any existing SGD optimizer. We show the efficacy of the proposed AdaNorm with four state-of-the-art optimizers, including Adam, diffGrad, Radam and AdaBelief. We depict the performance improvement due to the proposed optimizers using three CNN models, including VGG16, ResNet18 and ResNet50, on three benchmark object recognition datasets, including CIFAR10, CIFAR100 and TinyImageNet. Code: \url{https://github.com/shivram1987/AdaNorm}.
A Comprehensive Survey and Performance Analysis of Activation Functions in Deep Learning
Sep 29, 2021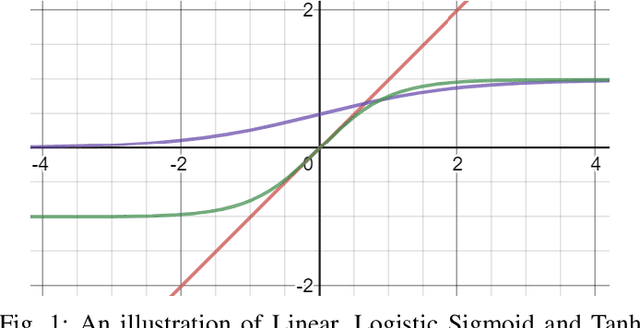
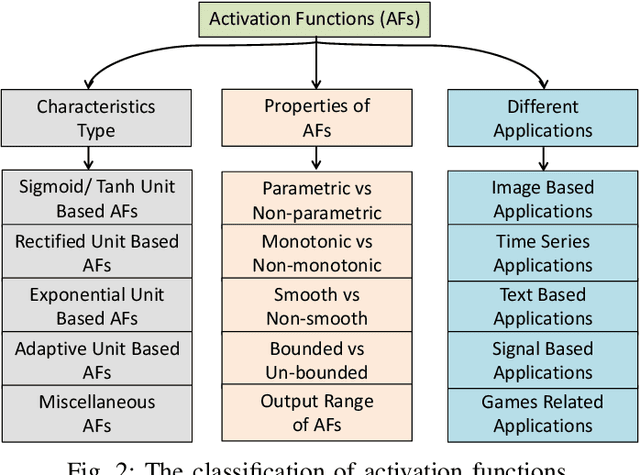
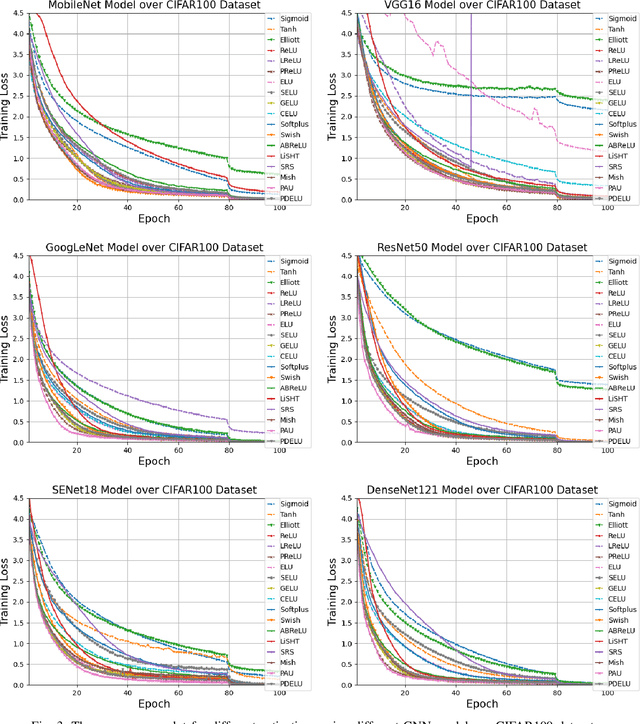
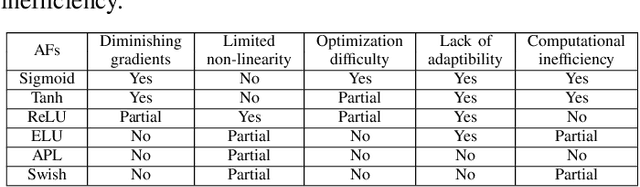
Neural networks have shown tremendous growth in recent years to solve numerous problems. Various types of neural networks have been introduced to deal with different types of problems. However, the main goal of any neural network is to transform the non-linearly separable input data into more linearly separable abstract features using a hierarchy of layers. These layers are combinations of linear and nonlinear functions. The most popular and common non-linearity layers are activation functions (AFs), such as Logistic Sigmoid, Tanh, ReLU, ELU, Swish and Mish. In this paper, a comprehensive overview and survey is presented for AFs in neural networks for deep learning. Different classes of AFs such as Logistic Sigmoid and Tanh based, ReLU based, ELU based, and Learning based are covered. Several characteristics of AFs such as output range, monotonicity, and smoothness are also pointed out. A performance comparison is also performed among 18 state-of-the-art AFs with different networks on different types of data. The insights of AFs are presented to benefit the researchers for doing further research and practitioners to select among different choices. The code used for experimental comparison is released at: \url{https://github.com/shivram1987/ActivationFunctions}.
Curvature Injected Adaptive Momentum Optimizer for Convolutional Neural Networks
Sep 26, 2021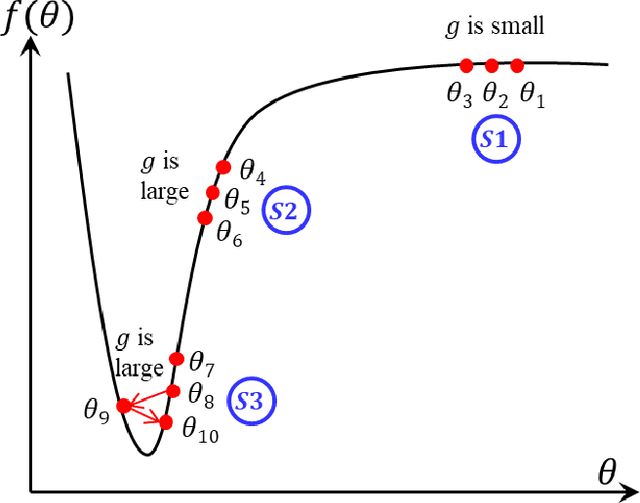
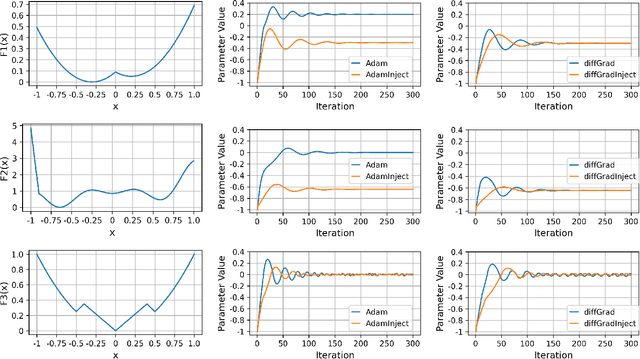
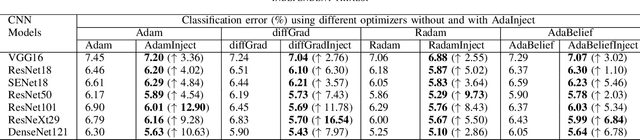
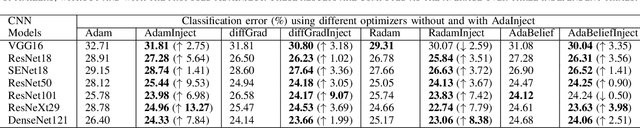
In this paper, we propose a new approach, hereafter referred as AdaInject, for the gradient descent optimizers by injecting the curvature information with adaptive momentum. Specifically, the curvature information is used as a weight to inject the second order moment in the update rule. The curvature information is captured through the short-term parameter history. The AdaInject approach boosts the parameter update by exploiting the curvature information. The proposed approach is generic in nature and can be integrated with any existing adaptive momentum stochastic gradient descent optimizers. The effectiveness of the AdaInject optimizer is tested using a theoretical analysis as well as through toy examples. We also show the convergence property of the proposed injection based optimizer. Further, we depict the efficacy of the AdaInject approach through extensive experiments in conjunction with the state-of-the-art optimizers, i.e., AdamInject, diffGradInject, RadamInject, and AdaBeliefInject on four benchmark datasets. Different CNN models are used in the experiments. A highest improvement in the top-1 classification error rate of $16.54\%$ is observed using diffGradInject optimizer with ResNeXt29 model over the CIFAR10 dataset. Overall, we observe very promising performance improvement of existing optimizers with the proposed AdaInject approach.
diffGrad: An Optimization Method for Convolutional Neural Networks
Sep 12, 2019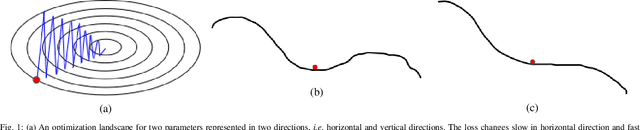
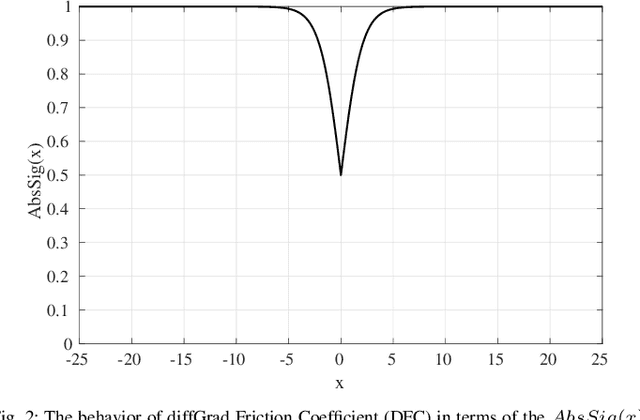
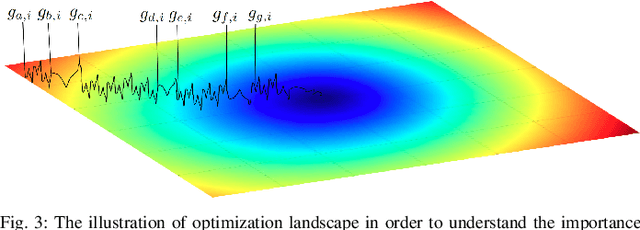
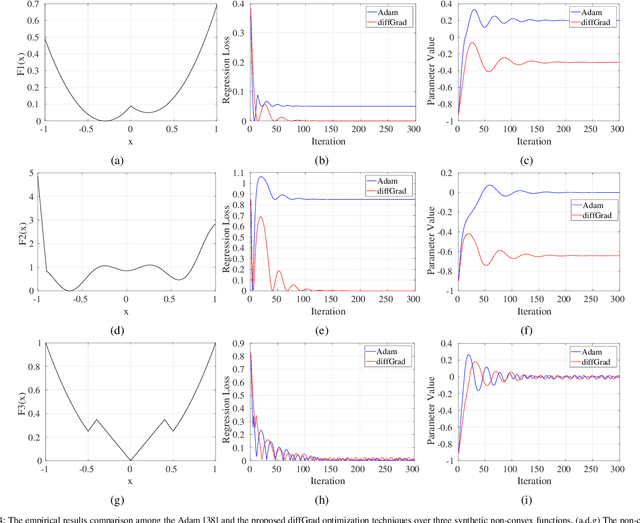
Stochastic Gradient Decent (SGD) is one of the core techniques behind the success of deep neural networks. The gradient provides information on the direction in which function has the steepest rate of change. The main problem with basic SGD is to change by equal sized steps for all parameters, irrespective of gradient behavior. Hence, an efficient way of deep network optimization is to make adaptive step sizes for each parameter. Recently, several attempts have been made to improve gradient descent methods such as AdaGrad, AdaDelta, RMSProp and Adam. These methods rely on the square roots of exponential moving averages of squared past gradients. Thus, these methods do not take the advantage of local change in gradients. In this paper, a novel optimizer is proposed based on the difference between the present and the immediate past gradient (i.e., diffGrad). In the proposed diffGrad optimization technique, the step size is adjusted for each parameter in such a way that it should have a larger step size for faster gradient changing parameters and lower step size for lower gradient changing parameters. The convergence analysis is done using the regret bound approach of online learning framework. Rigorous analysis is made in this paper over three synthetic complex non-convex functions. The image categorization experiments are also conducted over the CIFAR10 and CIFAR100 datasets to observe the performance of diffGrad with respect to the state-of-the-art optimizers such as SGDM, AdaGrad, AdaDelta, RMSProp, AMSGrad, and Adam. The residual unit (ResNet) based Convolutional Neural Networks (CNN) architecture is used in the experiments. The experiments show that diffGrad outperforms the other optimizers. Also, we showed that diffGrad performs uniformly well on network using different activation functions. The source code is made publicly available at https://github.com/shivram1987/diffGrad.
A BLSTM Network for Printed Bengali OCR System with High Accuracy
Aug 23, 2019
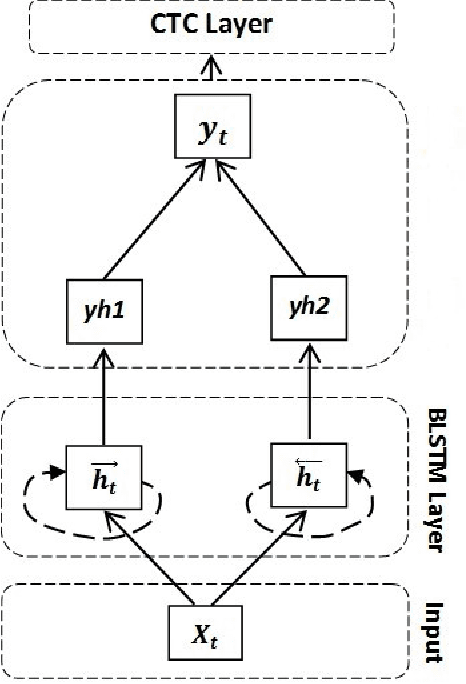
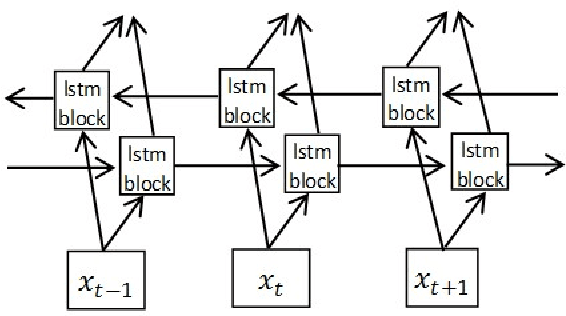

This paper presents a printed Bengali and English text OCR system developed by us using a single hidden BLSTM-CTC architecture having 128 units. Here, we did not use any peephole connection and dropout in the BLSTM, which helped us in getting better accuracy. This architecture was trained by 47,720 text lines that include English words also. When tested over 20 different Bengali fonts, it has produced character level accuracy of 99.32% and word level accuracy of 96.65%. A good Indic multi script OCR system is also developed by Google. It sometimes recognizes a character of Bengali into the same character of a non-Bengali script, especially Assamese, which has no distinction from Bengali, except for a few characters. For example, Bengali character for 'RA' is sometimes recognized as that of Assamese, mainly in conjunct consonant forms. Our OCR is free from such errors. This OCR system is available online at https://banglaocr.nltr.org
Dynamic Trajectory Model for Analysis of Traffic States using DPMM
Mar 18, 2018



Appropriate modeling of a surveillance scene is essential while analyzing and detecting anomalies in road traffic. Learning usual paths can provide much insight into road traffic situation and to identify abnormal routes taken by commuters/vehicles in a traffic scene. If usual traffic paths are learned in a nonparametric way, manual effort of marking the roads can be avoided. We propose an unsupervised and nonparametric method to learn frequently used paths from the tracks of moving objects in $\Theta(kn)$ time, where $k$ is the number of paths and $n$ represents the number of tracks. In the proposed method, temporal correlation of the moving objects is taken into consideration to make the clustering meaningful using Temporally Incremental Gravity Model-Dynamic Trajectory Model (TIGM-DTM). In addition, the scene learning is based on distance, thus making it realistically intuitive in estimating the model parameters. Experimental validation reveals that the proposed method can learn a scene quickly without knowing the number of paths ($k$). We have compared the results with mean shift and DBSCAN. Further, we extend the model to represent states of a scene that can be used for taking timely actions. We have applied the model to understand its effectiveness in other domain.