 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA BLSTM Network for Printed Bengali OCR System with High Accuracy
Aug 23, 2019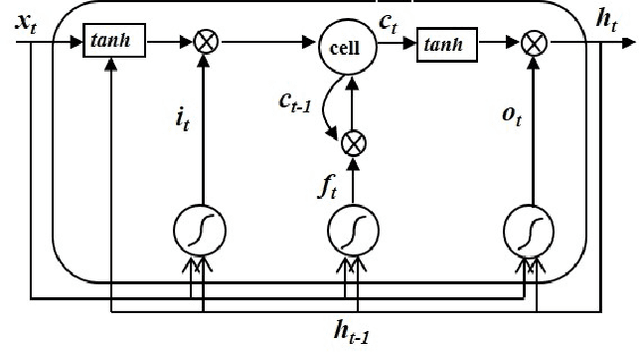
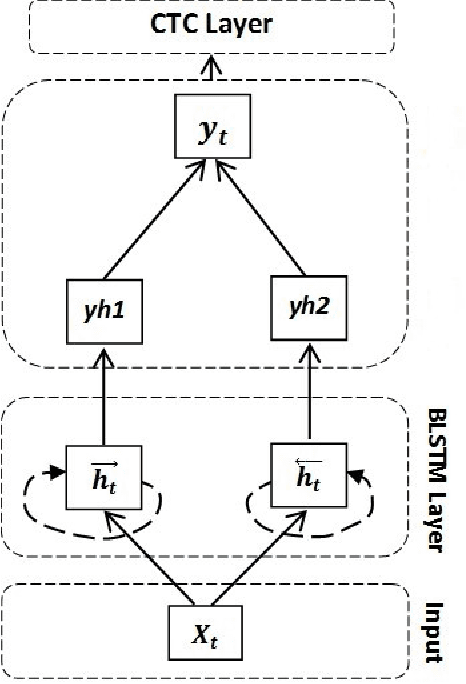
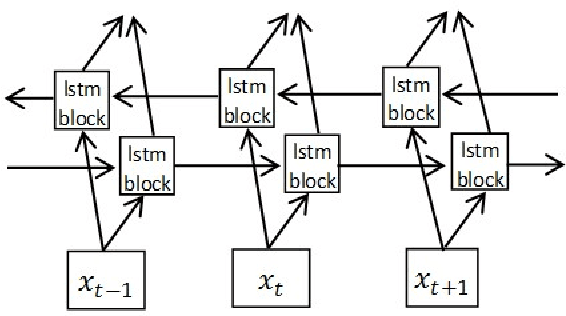

This paper presents a printed Bengali and English text OCR system developed by us using a single hidden BLSTM-CTC architecture having 128 units. Here, we did not use any peephole connection and dropout in the BLSTM, which helped us in getting better accuracy. This architecture was trained by 47,720 text lines that include English words also. When tested over 20 different Bengali fonts, it has produced character level accuracy of 99.32% and word level accuracy of 96.65%. A good Indic multi script OCR system is also developed by Google. It sometimes recognizes a character of Bengali into the same character of a non-Bengali script, especially Assamese, which has no distinction from Bengali, except for a few characters. For example, Bengali character for 'RA' is sometimes recognized as that of Assamese, mainly in conjunct consonant forms. Our OCR is free from such errors. This OCR system is available online at https://banglaocr.nltr.org