 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Directional Gradient Pattern: A Local Descriptor for Face Recognition
Jan 03, 2022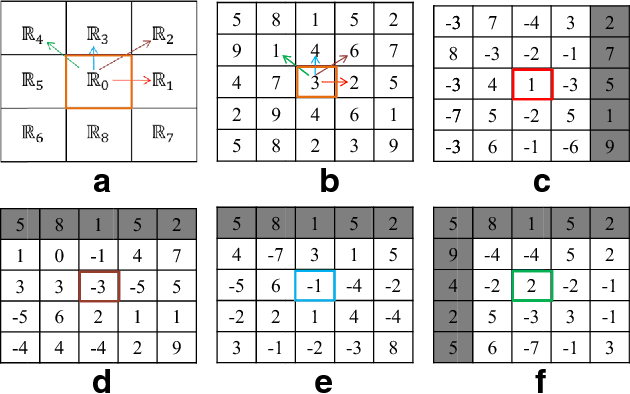


In this paper a local pattern descriptor in high order derivative space is proposed for face recognition. The proposed local directional gradient pattern (LDGP) is a 1D local micropattern computed by encoding the relationships between the higher order derivatives of the reference pixel in four distinct directions. The proposed descriptor identifies the relationship between the high order derivatives of the referenced pixel in four different directions to compute the micropattern which corresponds to the local feature. Proposed descriptor considerably reduces the length of the micropattern which consequently reduces the extraction time and matching time while maintaining the recognition rate. Results of the extensive experiments conducted on benchmark databases AT&T, Extended Yale B and CMU-PIE show that the proposed descriptor significantly reduces the extraction as well as matching time while the recognition rate is almost similar to the existing state of the art methods.
Cascaded Asymmetric Local Pattern: A Novel Descriptor for Unconstrained Facial Image Recognition and Retrieval
Jan 03, 2022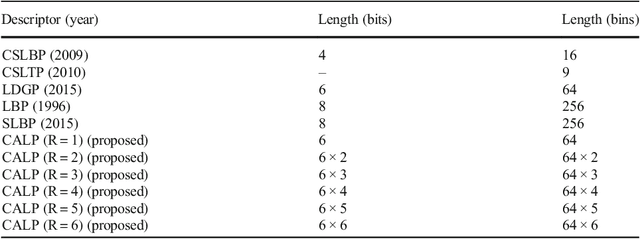
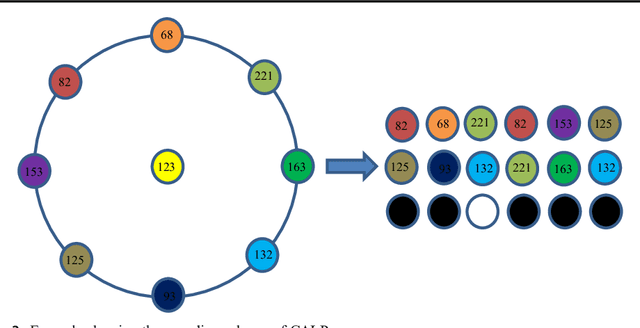

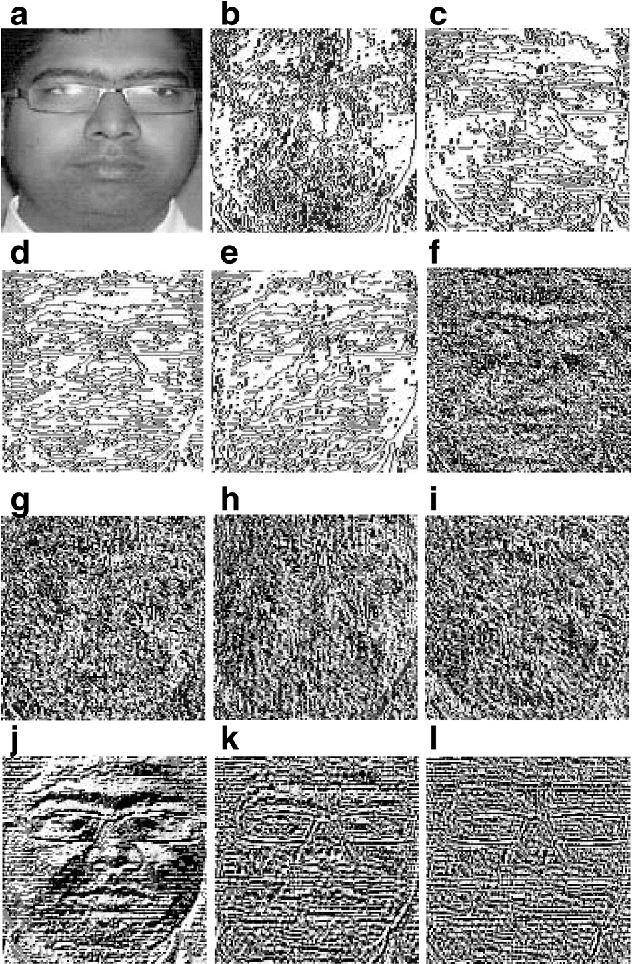
Feature description is one of the most frequently studied areas in the expert systems and machine learning. Effective encoding of the images is an essential requirement for accurate matching. These encoding schemes play a significant role in recognition and retrieval systems. Facial recognition systems should be effective enough to accurately recognize individuals under intrinsic and extrinsic variations of the system. The templates or descriptors used in these systems encode spatial relationships of the pixels in the local neighbourhood of an image. Features encoded using these hand crafted descriptors should be robust against variations such as; illumination, background, poses, and expressions. In this paper a novel hand crafted cascaded asymmetric local pattern (CALP) is proposed for retrieval and recognition facial image. The proposed descriptor uniquely encodes relationship amongst the neighbouring pixels in horizontal and vertical directions. The proposed encoding scheme has optimum feature length and shows significant improvement in accuracy under environmental and physiological changes in a facial image. State of the art hand crafted descriptors namely; LBP, LDGP, CSLBP, SLBP and CSLTP are compared with the proposed descriptor on most challenging datasets namely; Caltech-face, LFW, and CASIA-face-v5. Result analysis shows that, the proposed descriptor outperforms state of the art under uncontrolled variations in expressions, background, pose and illumination.
Local Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022

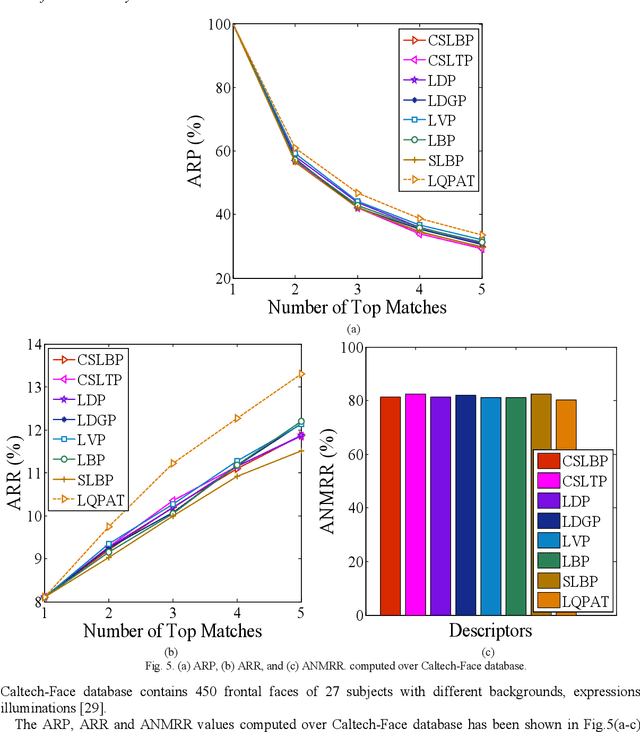

In this paper a novel hand crafted local quadruple pattern (LQPAT) is proposed for facial image recognition and retrieval. Most of the existing hand-crafted descriptors encodes only a limited number of pixels in the local neighbourhood. Under unconstrained environment the performance of these descriptors tends to degrade drastically. The major problem in increasing the local neighbourhood is that, it also increases the feature length of the descriptor. The proposed descriptor try to overcome these problems by defining an efficient encoding structure with optimal feature length. The proposed descriptor encodes relations amongst the neighbours in quadruple space. Two micro patterns are computed from the local relationships to form the descriptor. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand crafted descriptors on bench mark databases namely; Caltech-face, LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under uncontrolled variations in pose, illumination, background and expressions.
* arXiv admin note: substantial text overlap with arXiv:2201.00504, arXiv:2201.00511
Centre Symmetric Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022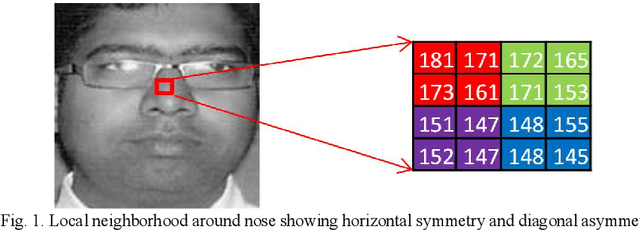



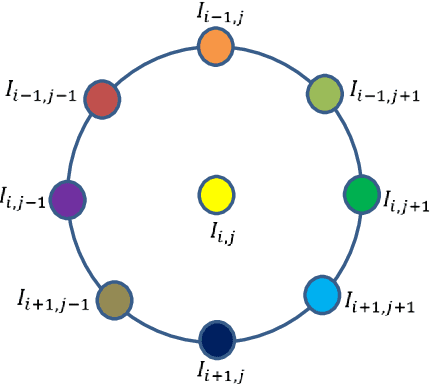
Facial features are defined as the local relationships that exist amongst the pixels of a facial image. Hand-crafted descriptors identify the relationships of the pixels in the local neighbourhood defined by the kernel. Kernel is a two dimensional matrix which is moved across the facial image. Distinctive information captured by the kernel with limited number of pixel achieves satisfactory recognition and retrieval accuracies on facial images taken under constrained environment (controlled variations in light, pose, expressions, and background). To achieve similar accuracies under unconstrained environment local neighbourhood has to be increased, in order to encode more pixels. Increasing local neighbourhood also increases the feature length of the descriptor. In this paper we propose a hand-crafted descriptor namely Centre Symmetric Quadruple Pattern (CSQP), which is structurally symmetric and encodes the facial asymmetry in quadruple space. The proposed descriptor efficiently encodes larger neighbourhood with optimal number of binary bits. It has been shown using average entropy, computed over feature images encoded with the proposed descriptor, that the CSQP captures more meaningful information as compared to state of the art descriptors. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand-crafted descriptors (CSLBP, CSLTP, LDP, LBP, SLBP and LDGP) on bench mark databases namely; LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under controlled as well as uncontrolled variations in pose, illumination, background and expressions.
Local Gradient Hexa Pattern: A Descriptor for Face Recognition and Retrieval
Jan 03, 2022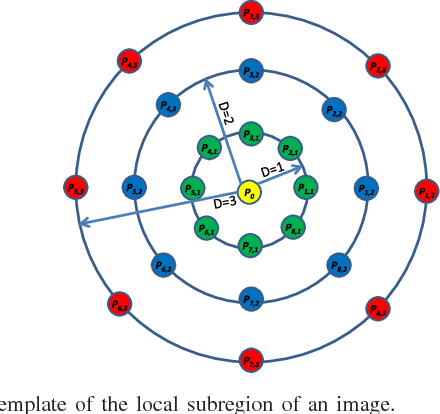
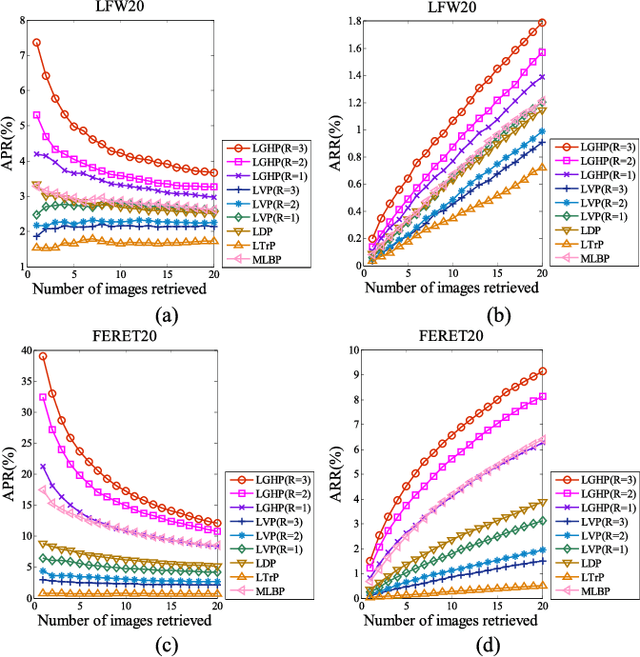
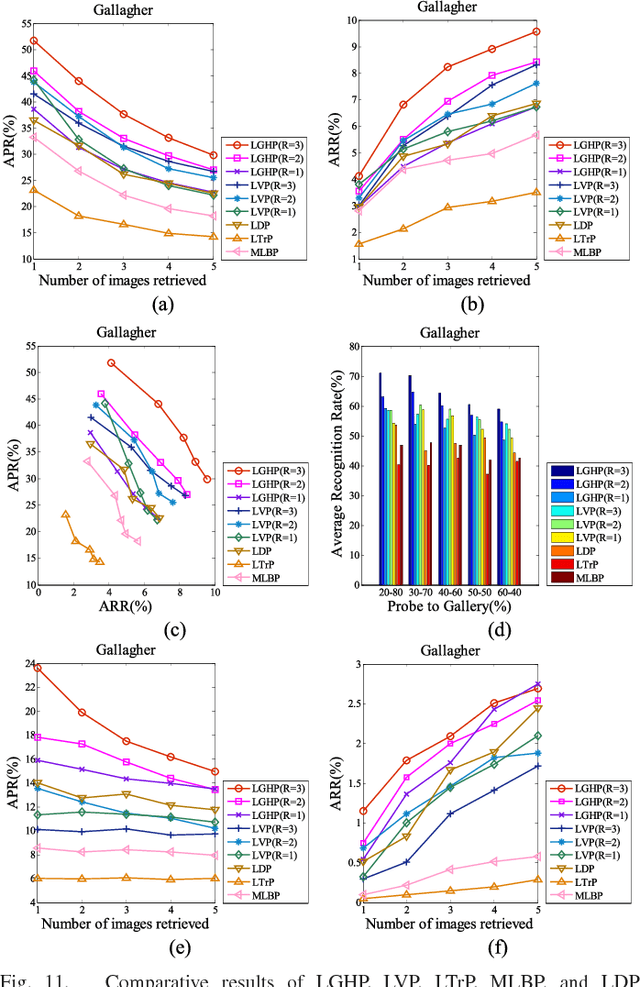
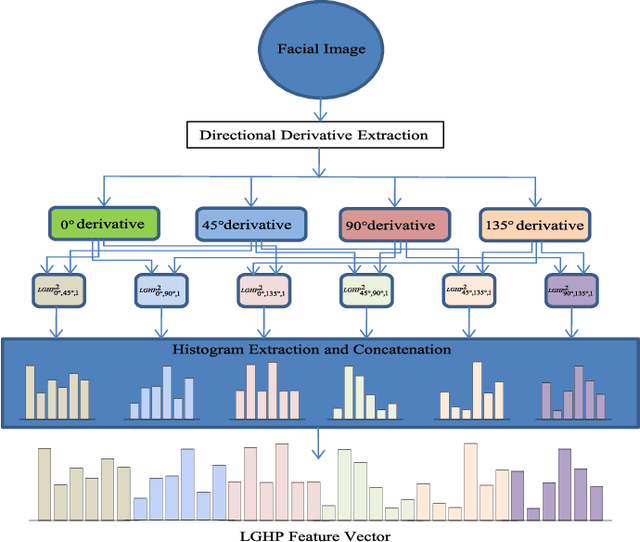
Local descriptors used in face recognition are robust in a sense that these descriptors perform well in varying pose, illumination and lighting conditions. Accuracy of these descriptors depends on the precision of mapping the relationship that exists in the local neighborhood of a facial image into microstructures. In this paper a local gradient hexa pattern (LGHP) is proposed that identifies the relationship amongst the reference pixel and its neighboring pixels at different distances across different derivative directions. Discriminative information exists in the local neighborhood as well as in different derivative directions. Proposed descriptor effectively transforms these relationships into binary micropatterns discriminating interclass facial images with optimal precision. Recognition and retrieval performance of the proposed descriptor has been compared with state-of-the-art descriptors namely LDP and LVP over the most challenging and benchmark facial image databases, i.e. Cropped Extended Yale-B, CMU-PIE, color-FERET, and LFW. The proposed descriptor has better recognition as well as retrieval rates compared to state-of-the-art descriptors.
R-Theta Local Neighborhood Pattern for Unconstrained Facial Image Recognition and Retrieval
Jan 03, 2022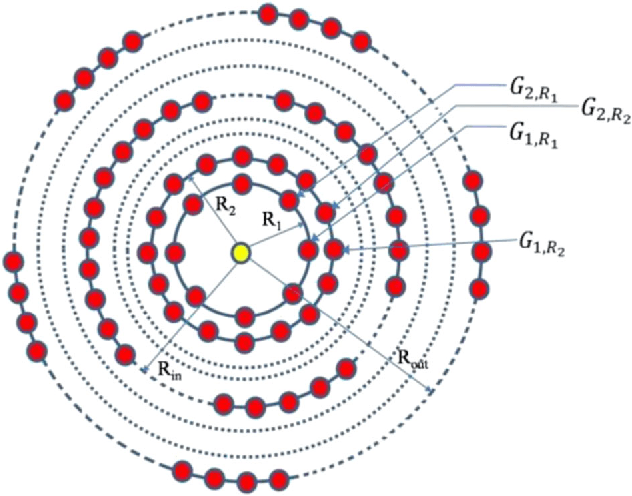



In this paper R-Theta Local Neighborhood Pattern (RTLNP) is proposed for facial image retrieval. RTLNP exploits relationships amongst the pixels in local neighborhood of the reference pixel at different angular and radial widths. The proposed encoding scheme divides the local neighborhood into sectors of equal angular width. These sectors are again divided into subsectors of two radial widths. Average grayscales values of these two subsectors are encoded to generate the micropatterns. Performance of the proposed descriptor has been evaluated and results are compared with the state of the art descriptors e.g. LBP, LTP, CSLBP, CSLTP, Sobel-LBP, LTCoP, LMeP, LDP, LTrP, MBLBP, BRINT and SLBP. The most challenging facial constrained and unconstrained databases, namely; AT&T, CARIA-Face-V5-Cropped, LFW, and Color FERET have been used for showing the efficiency of the proposed descriptor. Proposed descriptor is also tested on near infrared (NIR) face databases; CASIA NIR-VIS 2.0 and PolyU-NIRFD to explore its potential with respect to NIR facial images. Better retrieval rates of RTLNP as compared to the existing state of the art descriptors show the effectiveness of the descriptor
A Novel Local Binary Pattern Based Blind Feature Image Steganography
Jan 16, 2021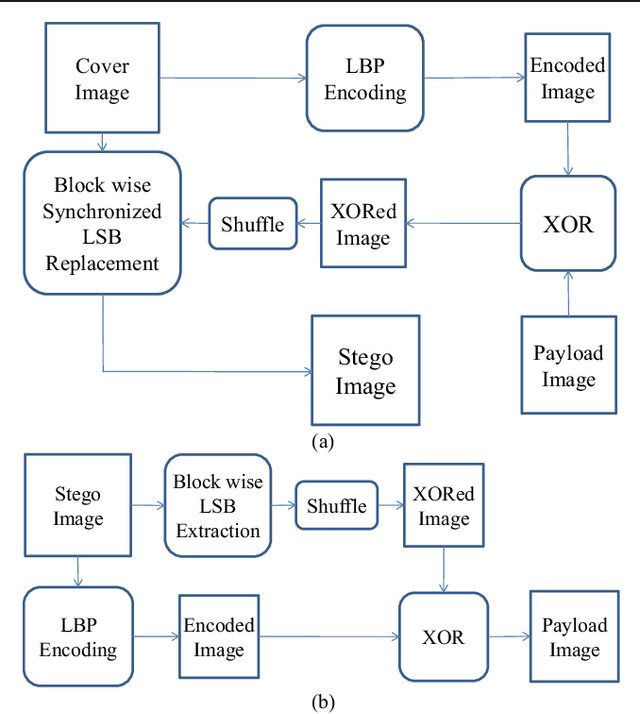
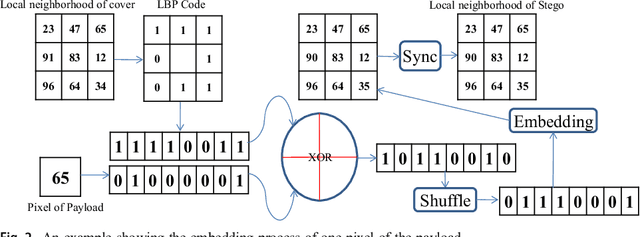
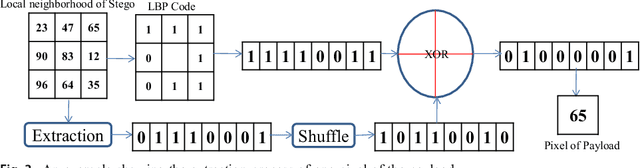
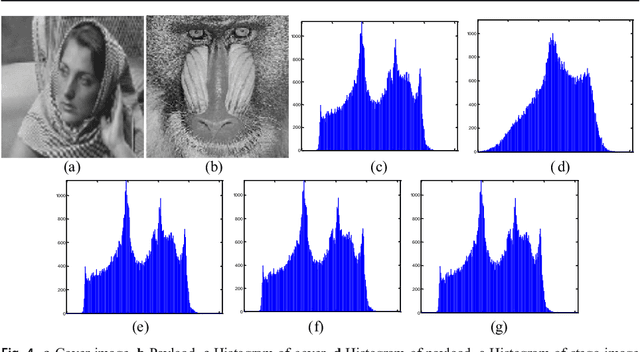
Steganography methods in general terms tend to embed more and more secret bits in the cover images. Most of these methods are designed to embed secret information in such a way that the change in the visual quality of the resulting stego image is not detectable. There exists some methods which preserve the global structure of the cover after embedding. However, the embedding capacity of these methods is very less. In this paper a novel feature based blind image steganography technique is proposed, which preserves the LBP (Local binary pattern) feature of the cover with comparable embedding rates. Local binary pattern is a well known image descriptor used for image representation. The proposed scheme computes the local binary pattern to hide the bits of the secret image in such a way that the local relationship that exists in the cover are preserved in the resulting stego image. The performance of the proposed steganography method has been tested on several images of different types to show the robustness. State of the art LSB based steganography methods are compared with the proposed method to show the effectiveness of feature based image steganography
Color Channel Perturbation Attacks for Fooling Convolutional Neural Networks and A Defense Against Such Attacks
Dec 20, 2020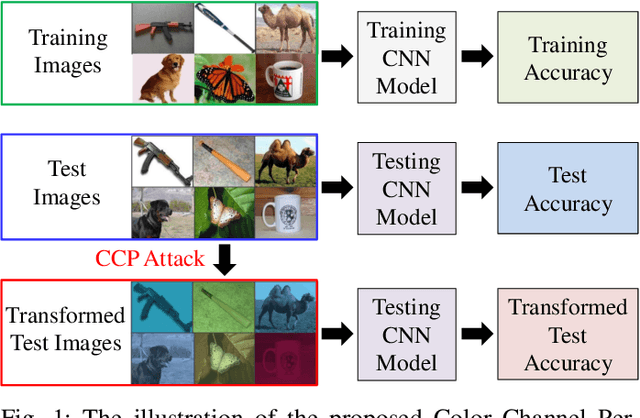



The Convolutional Neural Networks (CNNs) have emerged as a very powerful data dependent hierarchical feature extraction method. It is widely used in several computer vision problems. The CNNs learn the important visual features from training samples automatically. It is observed that the network overfits the training samples very easily. Several regularization methods have been proposed to avoid the overfitting. In spite of this, the network is sensitive to the color distribution within the images which is ignored by the existing approaches. In this paper, we discover the color robustness problem of CNN by proposing a Color Channel Perturbation (CCP) attack to fool the CNNs. In CCP attack new images are generated with new channels created by combining the original channels with the stochastic weights. Experiments were carried out over widely used CIFAR10, Caltech256 and TinyImageNet datasets in the image classification framework. The VGG, ResNet and DenseNet models are used to test the impact of the proposed attack. It is observed that the performance of the CNNs degrades drastically under the proposed CCP attack. Result show the effect of the proposed simple CCP attack over the robustness of the CNN trained model. The results are also compared with existing CNN fooling approaches to evaluate the accuracy drop. We also propose a primary defense mechanism to this problem by augmenting the training dataset with the proposed CCP attack. The state-of-the-art performance using the proposed solution in terms of the CNN robustness under CCP attack is observed in the experiments. The code is made publicly available at \url{https://github.com/jayendrakantipudi/Color-Channel-Perturbation-Attack}.
diffGrad: An Optimization Method for Convolutional Neural Networks
Sep 12, 2019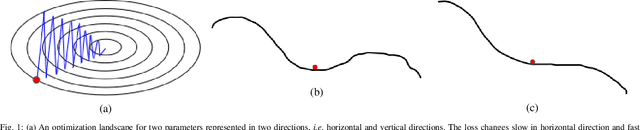
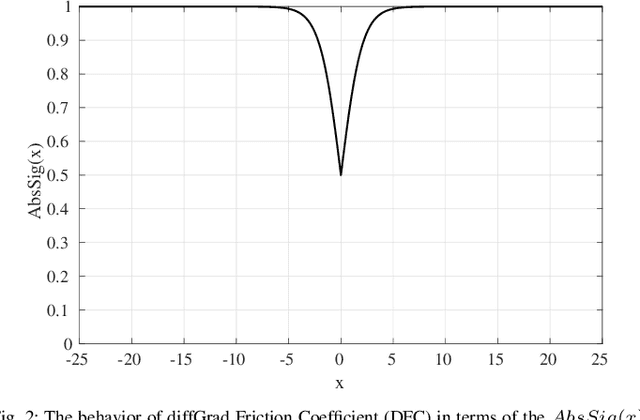
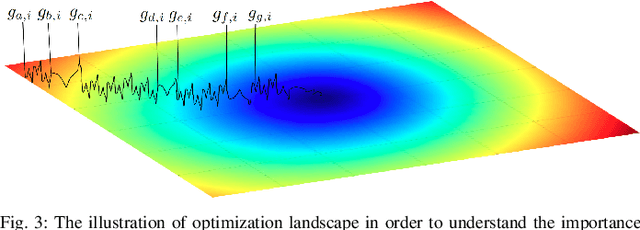
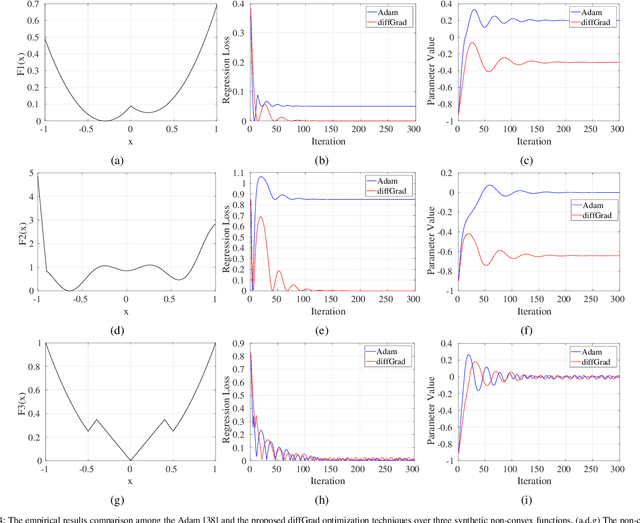
Stochastic Gradient Decent (SGD) is one of the core techniques behind the success of deep neural networks. The gradient provides information on the direction in which function has the steepest rate of change. The main problem with basic SGD is to change by equal sized steps for all parameters, irrespective of gradient behavior. Hence, an efficient way of deep network optimization is to make adaptive step sizes for each parameter. Recently, several attempts have been made to improve gradient descent methods such as AdaGrad, AdaDelta, RMSProp and Adam. These methods rely on the square roots of exponential moving averages of squared past gradients. Thus, these methods do not take the advantage of local change in gradients. In this paper, a novel optimizer is proposed based on the difference between the present and the immediate past gradient (i.e., diffGrad). In the proposed diffGrad optimization technique, the step size is adjusted for each parameter in such a way that it should have a larger step size for faster gradient changing parameters and lower step size for lower gradient changing parameters. The convergence analysis is done using the regret bound approach of online learning framework. Rigorous analysis is made in this paper over three synthetic complex non-convex functions. The image categorization experiments are also conducted over the CIFAR10 and CIFAR100 datasets to observe the performance of diffGrad with respect to the state-of-the-art optimizers such as SGDM, AdaGrad, AdaDelta, RMSProp, AMSGrad, and Adam. The residual unit (ResNet) based Convolutional Neural Networks (CNN) architecture is used in the experiments. The experiments show that diffGrad outperforms the other optimizers. Also, we showed that diffGrad performs uniformly well on network using different activation functions. The source code is made publicly available at https://github.com/shivram1987/diffGrad.
Average Biased ReLU Based CNN Descriptor for Improved Face Retrieval
Apr 02, 2018
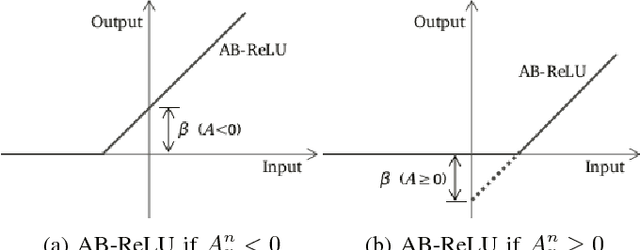
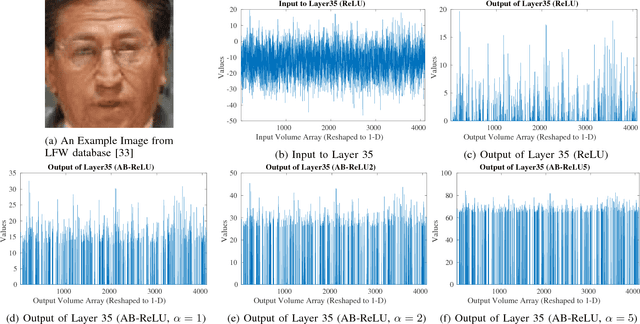

The convolutional neural networks (CNN) like AlexNet, GoogleNet, VGGNet, etc. have been proven as the very discriminative feature descriptor for many computer vision problems. The trained CNN model over one dataset performs reasonably well over another dataset of similar type and outperforms the hand-designed feature descriptor. The Rectified Linear Unit (ReLU) layer discards some information in order to introduce the non-linearity. In this paper, it is proposed that the discriminative ability of deep image representation using trained model can be improved by Average Biased ReLU (AB-ReLU) at last few layers. Basically, AB-ReLU improves the discriminative ability by two ways: 1) it also exploits some of the discriminative and discarded negative information of ReLU and 2) it kills the irrelevant and positive information used by ReLU. The VGGFace model already trained in MatConvNet over the VGG-Face dataset is used as the feature descriptor for face retrieval over other face datasets. The proposed approach is tested over six challenging unconstrained and robust face datasets like PubFig, LFW, PaSC, AR, etc. in retrieval framework. It is observed that AB-ReLU is consistently performed better than ReLU using VGGFace pretrained model over face datasets.