 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert-Guided Explainable Few-Shot Learning with Active Sample Selection for Medical Image Analysis
Jan 02, 2026Medical image analysis faces two critical challenges: scarcity of labeled data and lack of model interpretability, both hindering clinical AI deployment. Few-shot learning (FSL) addresses data limitations but lacks transparency in predictions. Active learning (AL) methods optimize data acquisition but overlook interpretability of acquired samples. We propose a dual-framework solution: Expert-Guided Explainable Few-Shot Learning (EGxFSL) and Explainability-Guided AL (xGAL). EGxFSL integrates radiologist-defined regions-of-interest as spatial supervision via Grad-CAM-based Dice loss, jointly optimized with prototypical classification for interpretable few-shot learning. xGAL introduces iterative sample acquisition prioritizing both predictive uncertainty and attention misalignment, creating a closed-loop framework where explainability guides training and sample selection synergistically. On the BraTS (MRI), VinDr-CXR (chest X-ray), and SIIM-COVID-19 (chest X-ray) datasets, we achieve accuracies of 92\%, 76\%, and 62\%, respectively, consistently outperforming non-guided baselines across all datasets. Under severe data constraints, xGAL achieves 76\% accuracy with only 680 samples versus 57\% for random sampling. Grad-CAM visualizations demonstrate guided models focus on diagnostically relevant regions, with generalization validated on breast ultrasound confirming cross-modality applicability.
Explainability-Guided Defense: Attribution-Aware Model Refinement Against Adversarial Data Attacks
Jan 02, 2026The growing reliance on deep learning models in safety-critical domains such as healthcare and autonomous navigation underscores the need for defenses that are both robust to adversarial perturbations and transparent in their decision-making. In this paper, we identify a connection between interpretability and robustness that can be directly leveraged during training. Specifically, we observe that spurious, unstable, or semantically irrelevant features identified through Local Interpretable Model-Agnostic Explanations (LIME) contribute disproportionately to adversarial vulnerability. Building on this insight, we introduce an attribution-guided refinement framework that transforms LIME from a passive diagnostic into an active training signal. Our method systematically suppresses spurious features using feature masking, sensitivity-aware regularization, and adversarial augmentation in a closed-loop refinement pipeline. This approach does not require additional datasets or model architectures and integrates seamlessly into standard adversarial training. Theoretically, we derive an attribution-aware lower bound on adversarial distortion that formalizes the link between explanation alignment and robustness. Empirical evaluations on CIFAR-10, CIFAR-10-C, and CIFAR-100 demonstrate substantial improvements in adversarial robustness and out-of-distribution generalization.
I Detect What I Don't Know: Incremental Anomaly Learning with Stochastic Weight Averaging-Gaussian for Oracle-Free Medical Imaging
Nov 11, 2025Unknown anomaly detection in medical imaging remains a fundamental challenge due to the scarcity of labeled anomalies and the high cost of expert supervision. We introduce an unsupervised, oracle-free framework that incrementally expands a trusted set of normal samples without any anomaly labels. Starting from a small, verified seed of normal images, our method alternates between lightweight adapter updates and uncertainty-gated sample admission. A frozen pretrained vision backbone is augmented with tiny convolutional adapters, ensuring rapid domain adaptation with negligible computational overhead. Extracted embeddings are stored in a compact coreset enabling efficient k-nearest neighbor anomaly (k-NN) scoring. Safety during incremental expansion is enforced by dual probabilistic gates, a sample is admitted into the normal memory only if its distance to the existing coreset lies within a calibrated z-score threshold, and its SWAG-based epistemic uncertainty remains below a seed-calibrated bound. This mechanism prevents drift and false inclusions without relying on generative reconstruction or replay buffers. Empirically, our system steadily refines the notion of normality as unlabeled data arrive, producing substantial gains over baselines. On COVID-CXR, ROC-AUC improves from 0.9489 to 0.9982 (F1: 0.8048 to 0.9746); on Pneumonia CXR, ROC-AUC rises from 0.6834 to 0.8968; and on Brain MRI ND-5, ROC-AUC increases from 0.6041 to 0.7269 and PR-AUC from 0.7539 to 0.8211. These results highlight the effectiveness and efficiency of the proposed framework for real-world, label-scarce medical imaging applications.
CoSwin: Convolution Enhanced Hierarchical Shifted Window Attention For Small-Scale Vision
Sep 10, 2025Vision Transformers (ViTs) have achieved impressive results in computer vision by leveraging self-attention to model long-range dependencies. However, their emphasis on global context often comes at the expense of local feature extraction in small datasets, particularly due to the lack of key inductive biases such as locality and translation equivariance. To mitigate this, we propose CoSwin, a novel feature-fusion architecture that augments the hierarchical shifted window attention with localized convolutional feature learning. Specifically, CoSwin integrates a learnable local feature enhancement module into each attention block, enabling the model to simultaneously capture fine-grained spatial details and global semantic structure. We evaluate CoSwin on multiple image classification benchmarks including CIFAR-10, CIFAR-100, MNIST, SVHN, and Tiny ImageNet. Our experimental results show consistent performance gains over state-of-the-art convolutional and transformer-based models. Notably, CoSwin achieves improvements of 2.17% on CIFAR-10, 4.92% on CIFAR-100, 0.10% on MNIST, 0.26% on SVHN, and 4.47% on Tiny ImageNet over the baseline Swin Transformer. These improvements underscore the effectiveness of local-global feature fusion in enhancing the generalization and robustness of transformers for small-scale vision. Code and pretrained weights available at https://github.com/puskal-khadka/coswin
Ecologically Valid Benchmarking and Adaptive Attention: Scalable Marine Bioacoustic Monitoring
Sep 04, 2025



Underwater Passive Acoustic Monitoring (UPAM) provides rich spatiotemporal data for long-term ecological analysis, but intrinsic noise and complex signal dependencies hinder model stability and generalization. Multilayered windowing has improved target sound localization, yet variability from shifting ambient noise, diverse propagation effects, and mixed biological and anthropogenic sources demands robust architectures and rigorous evaluation. We introduce GetNetUPAM, a hierarchical nested cross-validation framework designed to quantify model stability under ecologically realistic variability. Data are partitioned into distinct site-year segments, preserving recording heterogeneity and ensuring each validation fold reflects a unique environmental subset, reducing overfitting to localized noise and sensor artifacts. Site-year blocking enforces evaluation against genuine environmental diversity, while standard cross-validation on random subsets measures generalization across UPAM's full signal distribution, a dimension absent from current benchmarks. Using GetNetUPAM as the evaluation backbone, we propose the Adaptive Resolution Pooling and Attention Network (ARPA-N), a neural architecture for irregular spectrogram dimensions. Adaptive pooling with spatial attention extends the receptive field, capturing global context without excessive parameters. Under GetNetUPAM, ARPA-N achieves a 14.4% gain in average precision over DenseNet baselines and a log2-scale order-of-magnitude drop in variability across all metrics, enabling consistent detection across site-year folds and advancing scalable, accurate bioacoustic monitoring.
Bi-cephalic self-attended model to classify Parkinson's disease patients with freezing of gait
Jul 28, 2025Parkinson Disease (PD) often results in motor and cognitive impairments, including gait dysfunction, particularly in patients with freezing of gait (FOG). Current detection methods are either subjective or reliant on specialized gait analysis tools. This study aims to develop an objective, data-driven, and multi-modal classification model to detect gait dysfunction in PD patients using resting-state EEG signals combined with demographic and clinical variables. We utilized a dataset of 124 participants: 42 PD patients with FOG (PDFOG+), 41 without FOG (PDFOG-), and 41 age-matched healthy controls. Features extracted from resting-state EEG and descriptive variables (age, education, disease duration) were used to train a novel Bi-cephalic Self-Attention Model (BiSAM). We tested three modalities: signal-only, descriptive-only, and multi-modal, across different EEG channel subsets (BiSAM-63, -16, -8, and -4). Signal-only and descriptive-only models showed limited performance, achieving a maximum accuracy of 55% and 68%, respectively. In contrast, the multi-modal models significantly outperformed both, with BiSAM-8 and BiSAM-4 achieving the highest classification accuracy of 88%. These results demonstrate the value of integrating EEG with objective descriptive features for robust PDFOG+ detection. This study introduces a multi-modal, attention-based architecture that objectively classifies PDFOG+ using minimal EEG channels and descriptive variables. This approach offers a scalable and efficient alternative to traditional assessments, with potential applications in routine clinical monitoring and early diagnosis of PD-related gait dysfunction.
FocusNet: Transformer-enhanced Polyp Segmentation with Local and Pooling Attention
Apr 18, 2025Colonoscopy is vital in the early diagnosis of colorectal polyps. Regular screenings can effectively prevent benign polyps from progressing to CRC. While deep learning has made impressive strides in polyp segmentation, most existing models are trained on single-modality and single-center data, making them less effective in real-world clinical environments. To overcome these limitations, we propose FocusNet, a Transformer-enhanced focus attention network designed to improve polyp segmentation. FocusNet incorporates three essential modules: the Cross-semantic Interaction Decoder Module (CIDM) for generating coarse segmentation maps, the Detail Enhancement Module (DEM) for refining shallow features, and the Focus Attention Module (FAM), to balance local detail and global context through local and pooling attention mechanisms. We evaluate our model on PolypDB, a newly introduced dataset with multi-modality and multi-center data for building more reliable segmentation methods. Extensive experiments showed that FocusNet consistently outperforms existing state-of-the-art approaches with a high dice coefficients of 82.47% on the BLI modality, 88.46% on FICE, 92.04% on LCI, 82.09% on the NBI and 93.42% on WLI modality, demonstrating its accuracy and robustness across five different modalities. The source code for FocusNet is available at https://github.com/JunZengz/FocusNet.
L2GNet: Optimal Local-to-Global Representation of Anatomical Structures for Generalized Medical Image Segmentation
Feb 06, 2025



Continuous Latent Space (CLS) and Discrete Latent Space (DLS) models, like AttnUNet and VQUNet, have excelled in medical image segmentation. In contrast, Synergistic Continuous and Discrete Latent Space (CDLS) models show promise in handling fine and coarse-grained information. However, they struggle with modeling long-range dependencies. CLS or CDLS-based models, such as TransUNet or SynergyNet are adept at capturing long-range dependencies. Since they rely heavily on feature pooling or aggregation using self-attention, they may capture dependencies among redundant regions. This hinders comprehension of anatomical structure content, poses challenges in modeling intra-class and inter-class dependencies, increases false negatives and compromises generalization. Addressing these issues, we propose L2GNet, which learns global dependencies by relating discrete codes obtained from DLS using optimal transport and aligning codes on a trainable reference. L2GNet achieves discriminative on-the-fly representation learning without an additional weight matrix in self-attention models, making it computationally efficient for medical applications. Extensive experiments on multi-organ segmentation and cardiac datasets demonstrate L2GNet's superiority over state-of-the-art methods, including the CDLS method SynergyNet, offering an novel approach to enhance deep learning models' performance in medical image analysis.
Non-Uniform Illumination Attack for Fooling Convolutional Neural Networks
Sep 05, 2024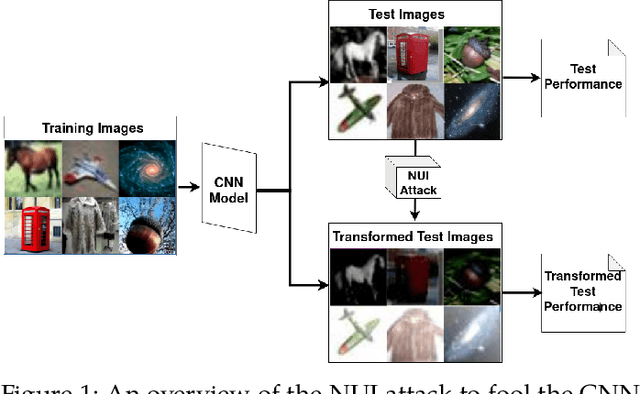
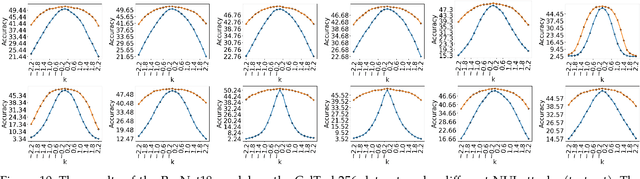
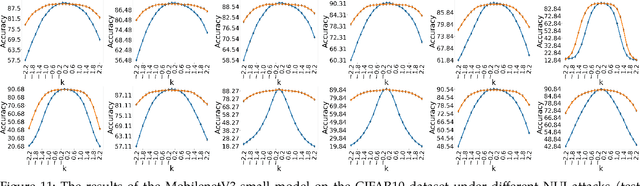
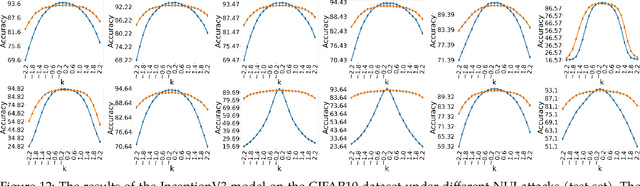
Convolutional Neural Networks (CNNs) have made remarkable strides; however, they remain susceptible to vulnerabilities, particularly in the face of minor image perturbations that humans can easily recognize. This weakness, often termed as 'attacks', underscores the limited robustness of CNNs and the need for research into fortifying their resistance against such manipulations. This study introduces a novel Non-Uniform Illumination (NUI) attack technique, where images are subtly altered using varying NUI masks. Extensive experiments are conducted on widely-accepted datasets including CIFAR10, TinyImageNet, and CalTech256, focusing on image classification with 12 different NUI attack models. The resilience of VGG, ResNet, MobilenetV3-small and InceptionV3 models against NUI attacks are evaluated. Our results show a substantial decline in the CNN models' classification accuracy when subjected to NUI attacks, indicating their vulnerability under non-uniform illumination. To mitigate this, a defense strategy is proposed, including NUI-attacked images, generated through the new NUI transformation, into the training set. The results demonstrate a significant enhancement in CNN model performance when confronted with perturbed images affected by NUI attacks. This strategy seeks to bolster CNN models' resilience against NUI attacks.
Enabling clustering algorithms to detect clusters of varying densities through scale-invariant data preprocessing
Jan 21, 2024In this paper, we show that preprocessing data using a variant of rank transformation called 'Average Rank over an Ensemble of Sub-samples (ARES)' makes clustering algorithms robust to data representation and enable them to detect varying density clusters. Our empirical results, obtained using three most widely used clustering algorithms-namely KMeans, DBSCAN, and DP (Density Peak)-across a wide range of real-world datasets, show that clustering after ARES transformation produces better and more consistent results.