 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSage-MT: A Multi-Turn Benchmark for Evaluating Agentic Time Series Reasoning
May 31, 2026Time series data inform critical decisions across many real-world domains. While large language model (LLM) agents can analyze data through natural language and tools, it remains unclear whether they can conduct reliable time series analysis across multi-turn conversations. Existing benchmarks focus on single-step tasks such as forecasting and anomaly detection, overlooking practical workflows where user goals evolve, agents must build on prior analyses, and conclusions emerge from accumulated evidence. In this work, we introduce TimeSage-MT, a multi-turn benchmark for agentic time series reasoning with 240 tasks and 2,680 dialogue turns across 8 real-world domains, spanning basic exploration to decision-oriented analysis. TimeSage-MT is built through a reproducible pipeline that converts real-world time series data into multi-turn conversations with verifiable answers. It provides a unified evaluation protocol and public leaderboard for comparing time series agentic systems. To demonstrate the benchmark's utility, we evaluate frontier LLMs alongside TimeSage, a novel structured agent equipped with a comprehensive time series skill library. The results show sharp performance drops on decision-oriented tasks, driven by failures in memory, uncertainty handling, and domain-based decision making. TimeSage-MT exposes critical gaps in current agentic reasoning and provides a rigorous foundation for future development.
Learning to Learn without Forgetting using Attention
Aug 06, 2024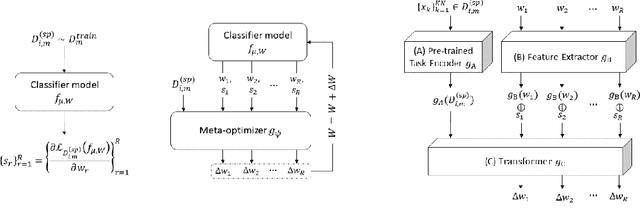

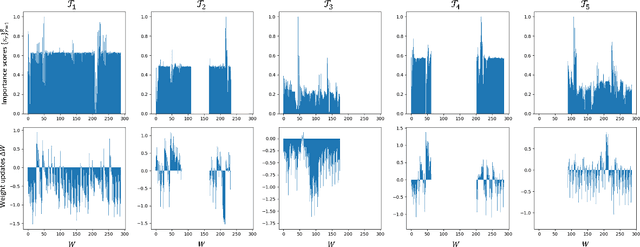
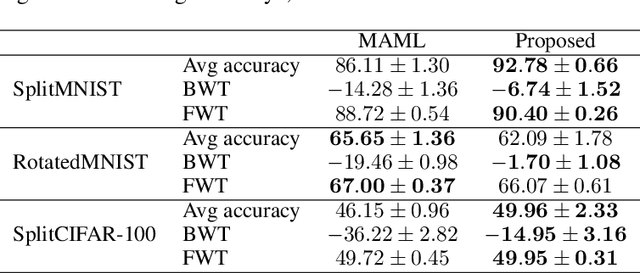
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Unsupervised Meta-Learning via In-Context Learning
May 25, 2024



Unsupervised meta-learning aims to learn feature representations from unsupervised datasets that can transfer to downstream tasks with limited labeled data. In this paper, we propose a novel approach to unsupervised meta-learning that leverages the generalization abilities of in-context learning observed in transformer architectures. Our method reframes meta-learning as a sequence modeling problem, enabling the transformer encoder to learn task context from support images and utilize it to predict query images. At the core of our approach lies the creation of diverse tasks generated using a combination of data augmentations and a mixing strategy that challenges the model during training while fostering generalization to unseen tasks at test time. Experimental results on benchmark datasets, including miniImageNet, CIFAR-fs, CUB, and Aircraft, showcase the superiority of our approach over existing unsupervised meta-learning baselines, establishing it as the new state-of-the-art in the field. Remarkably, our method achieves competitive results with supervised and self-supervised approaches, underscoring the efficacy of the model in leveraging generalization over memorization.
Personalized Federated Learning with Contextual Modulation and Meta-Learning
Dec 23, 2023Federated learning has emerged as a promising approach for training machine learning models on decentralized data sources while preserving data privacy. However, challenges such as communication bottlenecks, heterogeneity of client devices, and non-i.i.d. data distribution pose significant obstacles to achieving optimal model performance. We propose a novel framework that combines federated learning with meta-learning techniques to enhance both efficiency and generalization capabilities. Our approach introduces a federated modulator that learns contextual information from data batches and uses this knowledge to generate modulation parameters. These parameters dynamically adjust the activations of a base model, which operates using a MAML-based approach for model personalization. Experimental results across diverse datasets highlight the improvements in convergence speed and model performance compared to existing federated learning approaches. These findings highlight the potential of incorporating contextual information and meta-learning techniques into federated learning, paving the way for advancements in distributed machine learning paradigms.
Advances and Challenges in Meta-Learning: A Technical Review
Jul 10, 2023Meta-learning empowers learning systems with the ability to acquire knowledge from multiple tasks, enabling faster adaptation and generalization to new tasks. This review provides a comprehensive technical overview of meta-learning, emphasizing its importance in real-world applications where data may be scarce or expensive to obtain. The paper covers the state-of-the-art meta-learning approaches and explores the relationship between meta-learning and multi-task learning, transfer learning, domain adaptation and generalization, self-supervised learning, personalized federated learning, and continual learning. By highlighting the synergies between these topics and the field of meta-learning, the paper demonstrates how advancements in one area can benefit the field as a whole, while avoiding unnecessary duplication of efforts. Additionally, the paper delves into advanced meta-learning topics such as learning from complex multi-modal task distributions, unsupervised meta-learning, learning to efficiently adapt to data distribution shifts, and continual meta-learning. Lastly, the paper highlights open problems and challenges for future research in the field. By synthesizing the latest research developments, this paper provides a thorough understanding of meta-learning and its potential impact on various machine learning applications. We believe that this technical overview will contribute to the advancement of meta-learning and its practical implications in addressing real-world problems.