 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn without Forgetting using Attention
Paper and Code
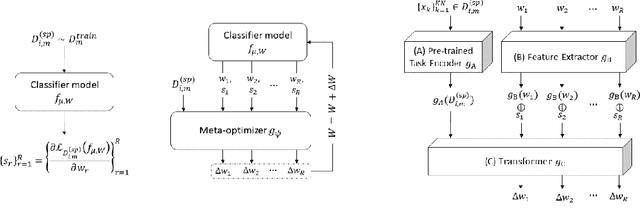

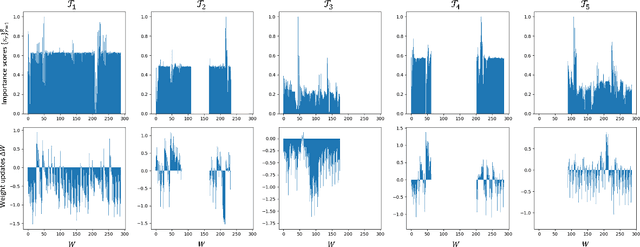
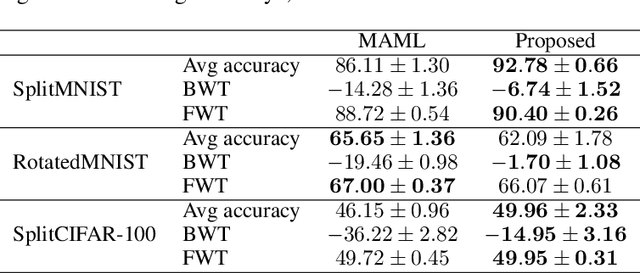
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.