 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging ChatGPT's Multimodal Vision Capabilities to Rank Satellite Images by Poverty Level: Advancing Tools for Social Science Research
Jan 24, 2025This paper investigates the novel application of Large Language Models (LLMs) with vision capabilities to analyze satellite imagery for village-level poverty prediction. Although LLMs were originally designed for natural language understanding, their adaptability to multimodal tasks, including geospatial analysis, has opened new frontiers in data-driven research. By leveraging advancements in vision-enabled LLMs, we assess their ability to provide interpretable, scalable, and reliable insights into human poverty from satellite images. Using a pairwise comparison approach, we demonstrate that ChatGPT can rank satellite images based on poverty levels with accuracy comparable to domain experts. These findings highlight both the promise and the limitations of LLMs in socioeconomic research, providing a foundation for their integration into poverty assessment workflows. This study contributes to the ongoing exploration of unconventional data sources for welfare analysis and opens pathways for cost-effective, large-scale poverty monitoring.
Learning to Learn without Forgetting using Attention
Aug 06, 2024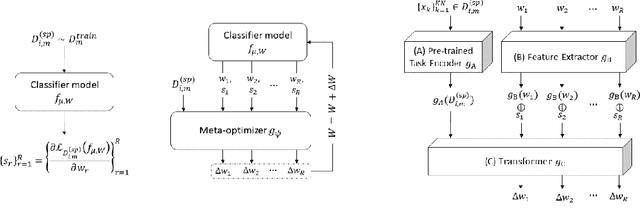

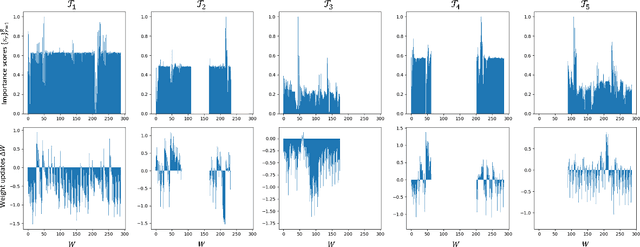
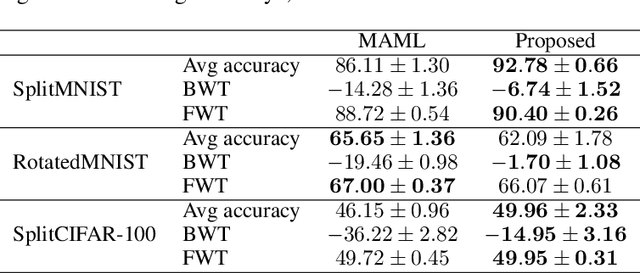
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
CoxSE: Exploring the Potential of Self-Explaining Neural Networks with Cox Proportional Hazards Model for Survival Analysis
Jul 18, 2024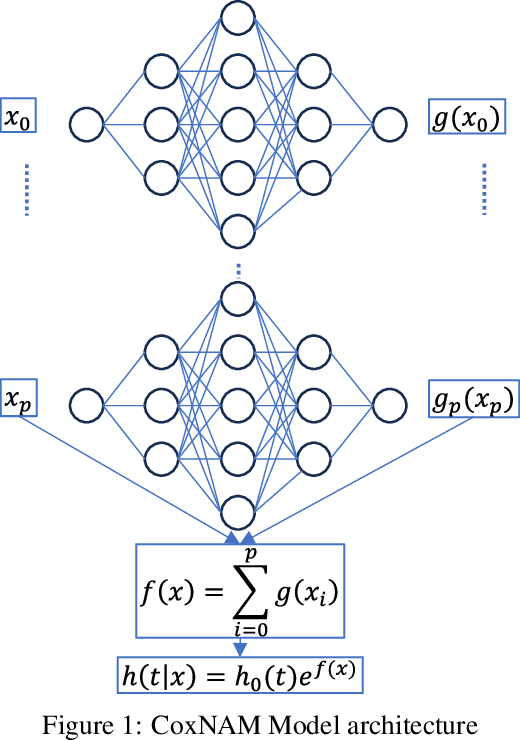



The Cox Proportional Hazards (CPH) model has long been the preferred survival model for its explainability. However, to increase its predictive power beyond its linear log-risk, it was extended to utilize deep neural networks sacrificing its explainability. In this work, we explore the potential of self-explaining neural networks (SENN) for survival analysis. we propose a new locally explainable Cox proportional hazards model, named CoxSE, by estimating a locally-linear log-hazard function using the SENN. We also propose a modification to the Neural additive (NAM) models hybrid with SENN, named CoxSENAM, which enables the control of the stability and consistency of the generated explanations. Several experiments using synthetic and real datasets have been performed comparing with a NAM-based model, DeepSurv model explained with SHAP, and a linear CPH model. The results show that, unlike the NAM-based model, the SENN-based model can provide more stable and consistent explanations while maintaining the same expressiveness power of the black-box model. The results also show that, due to their structural design, NAM-based models demonstrated better robustness to non-informative features. Among these models, the hybrid model exhibited the best robustness.
Personalized Federated Learning with Contextual Modulation and Meta-Learning
Dec 23, 2023Federated learning has emerged as a promising approach for training machine learning models on decentralized data sources while preserving data privacy. However, challenges such as communication bottlenecks, heterogeneity of client devices, and non-i.i.d. data distribution pose significant obstacles to achieving optimal model performance. We propose a novel framework that combines federated learning with meta-learning techniques to enhance both efficiency and generalization capabilities. Our approach introduces a federated modulator that learns contextual information from data batches and uses this knowledge to generate modulation parameters. These parameters dynamically adjust the activations of a base model, which operates using a MAML-based approach for model personalization. Experimental results across diverse datasets highlight the improvements in convergence speed and model performance compared to existing federated learning approaches. These findings highlight the potential of incorporating contextual information and meta-learning techniques into federated learning, paving the way for advancements in distributed machine learning paradigms.
Towards Explaining Satellite Based Poverty Predictions with Convolutional Neural Networks
Dec 01, 2023Deep convolutional neural networks (CNNs) have been shown to predict poverty and development indicators from satellite images with surprising accuracy. This paper presents a first attempt at analyzing the CNNs responses in detail and explaining the basis for the predictions. The CNN model, while trained on relatively low resolution day- and night-time satellite images, is able to outperform human subjects who look at high-resolution images in ranking the Wealth Index categories. Multiple explainability experiments performed on the model indicate the importance of the sizes of the objects, pixel colors in the image, and provide a visualization of the importance of different structures in input images. A visualization is also provided of type images that maximize the network prediction of Wealth Index, which provides clues on what the CNN prediction is based on.
Advances and Challenges in Meta-Learning: A Technical Review
Jul 10, 2023Meta-learning empowers learning systems with the ability to acquire knowledge from multiple tasks, enabling faster adaptation and generalization to new tasks. This review provides a comprehensive technical overview of meta-learning, emphasizing its importance in real-world applications where data may be scarce or expensive to obtain. The paper covers the state-of-the-art meta-learning approaches and explores the relationship between meta-learning and multi-task learning, transfer learning, domain adaptation and generalization, self-supervised learning, personalized federated learning, and continual learning. By highlighting the synergies between these topics and the field of meta-learning, the paper demonstrates how advancements in one area can benefit the field as a whole, while avoiding unnecessary duplication of efforts. Additionally, the paper delves into advanced meta-learning topics such as learning from complex multi-modal task distributions, unsupervised meta-learning, learning to efficiently adapt to data distribution shifts, and continual meta-learning. Lastly, the paper highlights open problems and challenges for future research in the field. By synthesizing the latest research developments, this paper provides a thorough understanding of meta-learning and its potential impact on various machine learning applications. We believe that this technical overview will contribute to the advancement of meta-learning and its practical implications in addressing real-world problems.
The Concordance Index decomposition: a measure for a deeper understanding of survival prediction models
Mar 02, 2022
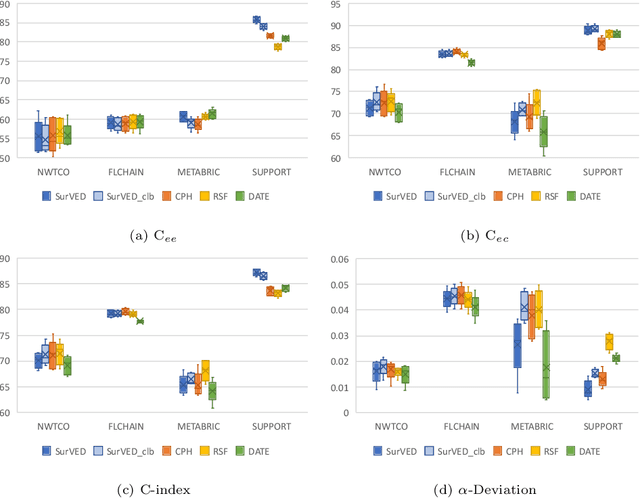
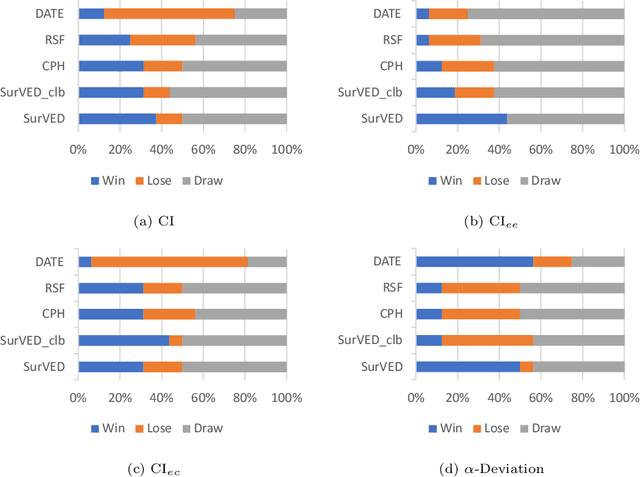

The Concordance Index (C-index) is a commonly used metric in Survival Analysis to evaluate how good a prediction model is. This paper proposes a decomposition of the C-Index into a weighted harmonic mean of two quantities: one for ranking observed events versus other observed events, and the other for ranking observed events versus censored cases. This decomposition allows a more fine-grained analysis of the pros and cons of survival prediction methods. The utility of the decomposition is demonstrated using three benchmark survival analysis models (Cox Proportional Hazard, Random Survival Forest, and Deep Adversarial Time-to-Event Network) together with a new variational generative neural-network-based method (SurVED), which is also proposed in this paper. The demonstration is done on four publicly available datasets with varying censoring levels. The analysis with the C-index decomposition shows that all methods essentially perform equally well when the censoring level is high because of the dominance of the term measuring the ranking of events versus censored cases. In contrast, some methods deteriorate when the censoring level decreases because they do not rank the events versus other events well.
Transfer learning for Remaining Useful Life Prediction Based on Consensus Self-Organizing Models
Sep 30, 2019
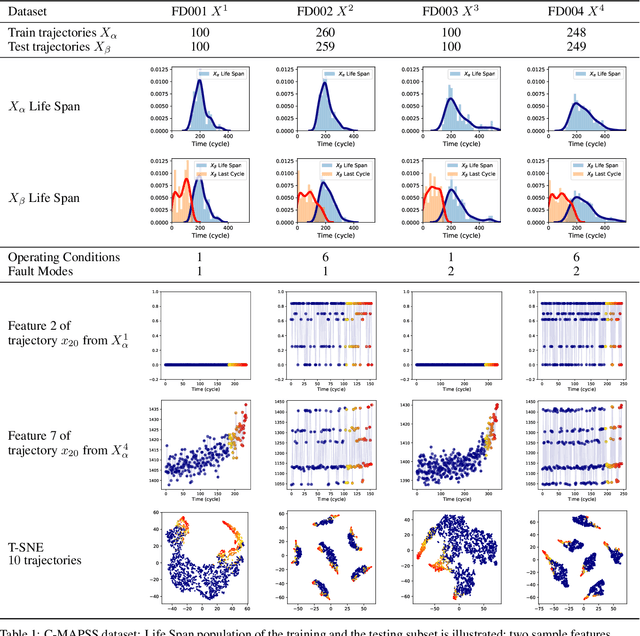
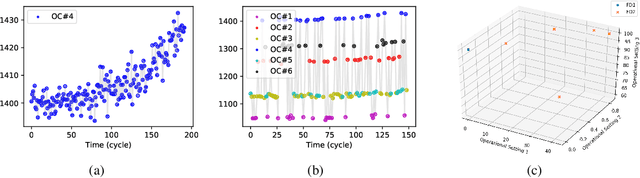

The traditional paradigm for developing machine prognostics usually relies on generalization from data acquired in experiments under controlled conditions prior to deployment of the equipment. Detecting or predicting failures and estimating machine health in this way assumes that future field data will have a very similar distribution to the experiment data. However, many complex machines operate under dynamic environmental conditions and are used in many different ways. This makes collecting comprehensive data very challenging, and the assumption that pre-deployment data and post-deployment data follow very similar distributions is unlikely to hold. Transfer Learning (TL) refers to methods for transferring knowledge learned in one setting (the source domain) to another setting (the target domain). In this work, we present a TL method for predicting Remaining Useful Life (RUL) of equipment, under the assumption that labels are available only for the source domain and not the target domain. This setting corresponds to generalizing from a limited number of run-to-failure experiments performed prior to deployment into making prognostics with data coming from deployed equipment that is being used under multiple new operating conditions and experiencing previously unseen faults. We employ a deviation detection method, Consensus Self-Organizing Models (COSMO), to create transferable features for building the RUL regression model. These features capture how different target equipment is in comparison to its peers. The efficiency of the proposed TL method is demonstrated using the NASA Turbofan Engine Degradation Simulation Data Set. Models using the COSMO transferable features show better performance than other methods on predicting RUL when the target domain is more complex than the source domain.