 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWSD: Wild Selfie Dataset for Face Recognition in Selfie Images
Feb 14, 2023



With the rise of handy smart phones in the recent years, the trend of capturing selfie images is observed. Hence efficient approaches are required to be developed for recognising faces in selfie images. Due to the short distance between the camera and face in selfie images, and the different visual effects offered by the selfie apps, face recognition becomes more challenging with existing approaches. A dataset is needed to be developed to encourage the study to recognize faces in selfie images. In order to alleviate this problem and to facilitate the research on selfie face images, we develop a challenging Wild Selfie Dataset (WSD) where the images are captured from the selfie cameras of different smart phones, unlike existing datasets where most of the images are captured in controlled environment. The WSD dataset contains 45,424 images from 42 individuals (i.e., 24 female and 18 male subjects), which are divided into 40,862 training and 4,562 test images. The average number of images per subject is 1,082 with minimum and maximum number of images for any subject are 518 and 2,634, respectively. The proposed dataset consists of several challenges, including but not limited to augmented reality filtering, mirrored images, occlusion, illumination, scale, expressions, view-point, aspect ratio, blur, partial faces, rotation, and alignment. We compare the proposed dataset with existing benchmark datasets in terms of different characteristics. The complexity of WSD dataset is also observed experimentally, where the performance of the existing state-of-the-art face recognition methods is poor on WSD dataset, compared to the existing datasets. Hence, the proposed WSD dataset opens up new challenges in the area of face recognition and can be beneficial to the community to study the specific challenges related to selfie images and develop improved methods for face recognition in selfie images.
AnimePose: Multi-person 3D pose estimation and animation
Feb 06, 2020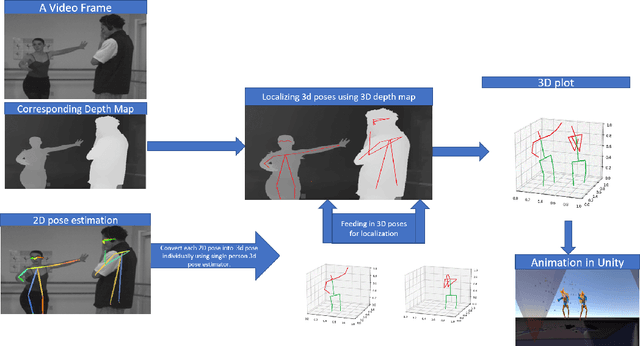



3D animation of humans in action is quite challenging as it involves using a huge setup with several motion trackers all over the person's body to track the movements of every limb. This is time-consuming and may cause the person discomfort in wearing exoskeleton body suits with motion sensors. In this work, we present a trivial yet effective solution to generate 3D animation of multiple persons from a 2D video using deep learning. Although significant improvement has been achieved recently in 3D human pose estimation, most of the prior works work well in case of single person pose estimation and multi-person pose estimation is still a challenging problem. In this work, we firstly propose a supervised multi-person 3D pose estimation and animation framework namely AnimePose for a given input RGB video sequence. The pipeline of the proposed system consists of various modules: i) Person detection and segmentation, ii) Depth Map estimation, iii) Lifting 2D to 3D information for person localization iv) Person trajectory prediction and human pose tracking. Our proposed system produces comparable results on previous state-of-the-art 3D multi-person pose estimation methods on publicly available datasets MuCo-3DHP and MuPoTS-3D datasets and it also outperforms previous state-of-the-art human pose tracking methods by a significant margin of 11.7% performance gain on MOTA score on Posetrack 2018 dataset.