 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoji Prediction using Transformer Models
Jul 16, 2023In recent years, the use of emojis in social media has increased dramatically, making them an important element in understanding online communication. However, predicting the meaning of emojis in a given text is a challenging task due to their ambiguous nature. In this study, we propose a transformer-based approach for emoji prediction using BERT, a widely-used pre-trained language model. We fine-tuned BERT on a large corpus of text containing both text and emojis to predict the most appropriate emoji for a given text. Our experimental results demonstrate that our approach outperforms several state-of-the-art models in predicting emojis with an accuracy of over 75 percent. This work has potential applications in natural language processing, sentiment analysis, and social media marketing.
Neural Machine Translation for Low-Resource Languages: A Survey
Jun 29, 2021
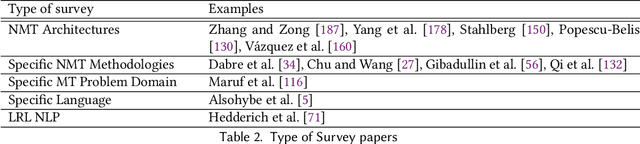
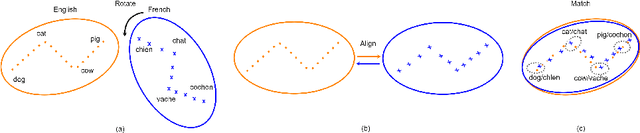
Neural Machine Translation (NMT) has seen a tremendous spurt of growth in less than ten years, and has already entered a mature phase. While considered as the most widely used solution for Machine Translation, its performance on low-resource language pairs still remains sub-optimal compared to the high-resource counterparts, due to the unavailability of large parallel corpora. Therefore, the implementation of NMT techniques for low-resource language pairs has been receiving the spotlight in the recent NMT research arena, thus leading to a substantial amount of research reported on this topic. This paper presents a detailed survey of research advancements in low-resource language NMT (LRL-NMT), along with a quantitative analysis aimed at identifying the most popular solutions. Based on our findings from reviewing previous work, this survey paper provides a set of guidelines to select the possible NMT technique for a given LRL data setting. It also presents a holistic view of the LRL-NMT research landscape and provides a list of recommendations to further enhance the research efforts on LRL-NMT.
Sequence to Sequence Networks for Roman-Urdu to Urdu Transliteration
Dec 08, 2017


Neural Machine Translation models have replaced the conventional phrase based statistical translation methods since the former takes a generic, scalable, data-driven approach rather than relying on manual, hand-crafted features. The neural machine translation system is based on one neural network that is composed of two parts, one that is responsible for input language sentence and other part that handles the desired output language sentence. This model based on encoder-decoder architecture also takes as input the distributed representations of the source language which enriches the learnt dependencies and gives a warm start to the network. In this work, we transform Roman-Urdu to Urdu transliteration into sequence to sequence learning problem. To this end, we make the following contributions. We create the first ever parallel corpora of Roman-Urdu to Urdu, create the first ever distributed representation of Roman-Urdu and present the first neural machine translation model that transliterates text from Roman-Urdu to Urdu language. Our model has achieved the state-of-the-art results using BLEU as the evaluation metric. Precisely, our model is able to correctly predict sentences up to length 10 while achieving BLEU score of 48.6 on the test set. We are hopeful that our model and our results shall serve as the baseline for further work in the domain of neural machine translation for Roman-Urdu to Urdu using distributed representation.