 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelection of CMIP6 Models for Regional Precipitation Projection and Climate Change Assessment in the Jhelum and Chenab River Basins
Feb 13, 2026Effective water resource management depends on accurate projections of flows in water channels. For projected climate data, use of different General Circulation Models (GCM) simulates contrasting results. This study shows selection of GCM for the latest generation CMIP6 for hydroclimate change impact studies. Envelope based method was used for the selection, which includes components based on machine learning techniques, allowing the selection of GCMs without the need for in-situ reference data. According to our knowledge, for the first time, such a comparison was performed for the CMIP6 Shared Socioeconomic Pathway (SSP) scenarios data. In addition, the effect of climate change under SSP scenarios was studied, along with the calculation of extreme indices. Finally, GCMs were compared to quantify spatiotemporal differences between CMIP5 and CMIP6 data. Results provide NorESM2 LM, FGOALS g3 as selected models for the Jhelum and Chenab River. Highly vulnerable regions under the effect of climate change were highlighted through spatial maps, which included parts of Punjab, Jammu, and Kashmir. Upon comparison of CMIP5 and CMIP6, no discernible difference was found between the RCP and SSP scenarios precipitation projections. In the future, more detailed statistical comparisons could further reinforce the proposition.
Multi Class Depression Detection Through Tweets using Artificial Intelligence
Apr 19, 2024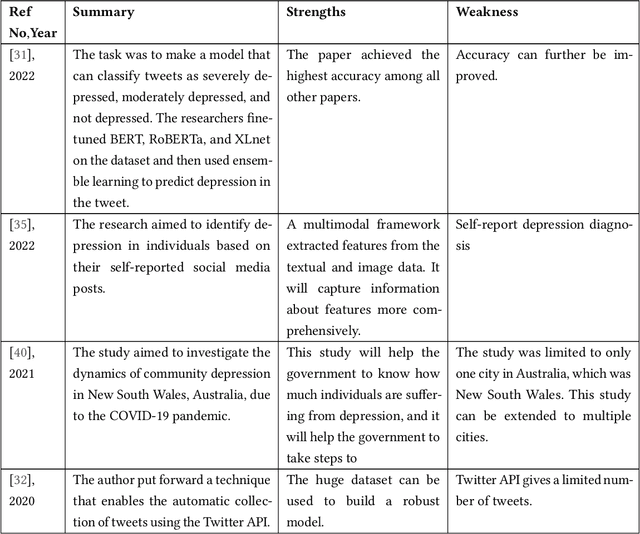

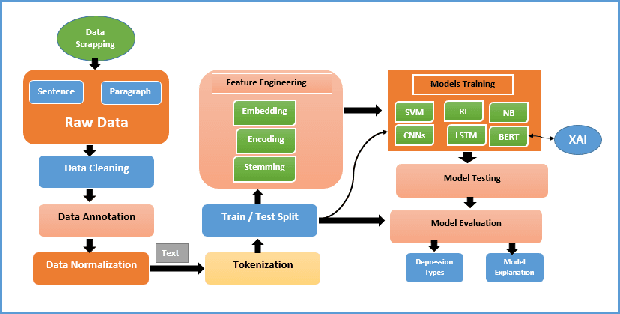
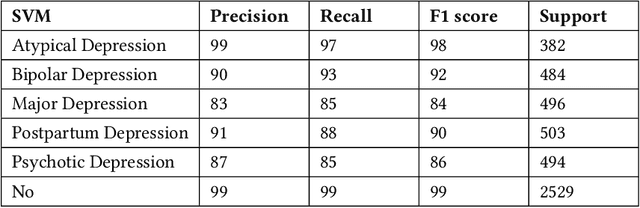
Depression is a significant issue nowadays. As per the World Health Organization (WHO), in 2023, over 280 million individuals are grappling with depression. This is a huge number; if not taken seriously, these numbers will increase rapidly. About 4.89 billion individuals are social media users. People express their feelings and emotions on platforms like Twitter, Facebook, Reddit, Instagram, etc. These platforms contain valuable information which can be used for research purposes. Considerable research has been conducted across various social media platforms. However, certain limitations persist in these endeavors. Particularly, previous studies were only focused on detecting depression and the intensity of depression in tweets. Also, there existed inaccuracies in dataset labeling. In this research work, five types of depression (Bipolar, major, psychotic, atypical, and postpartum) were predicted using tweets from the Twitter database based on lexicon labeling. Explainable AI was used to provide reasoning by highlighting the parts of tweets that represent type of depression. Bidirectional Encoder Representations from Transformers (BERT) was used for feature extraction and training. Machine learning and deep learning methodologies were used to train the model. The BERT model presented the most promising results, achieving an overall accuracy of 0.96.
Estimation of Physical Parameters of Waveforms With Neural Networks
Dec 05, 2023

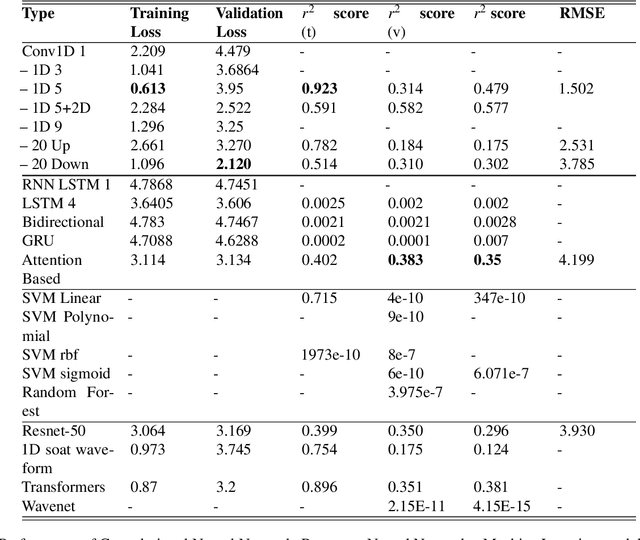
Light Detection and Ranging (LiDAR) are fast emerging sensors in the field of Earth Observation. It is a remote sensing technology that utilizes laser beams to measure distances and create detailed three-dimensional representations of objects and environments. The potential of Full Waveform LiDAR is much greater than just height estimation and 3D reconstruction only. Overall shape of signal provides important information about properties of water body. However, the shape of FWL is unexplored as most LiDAR software work on point cloud by utilizing the maximum value within the waveform. Existing techniques in the field of LiDAR data analysis include depth estimation through inverse modeling and regression of logarithmic intensity and depth for approximating the attenuation coefficient. However, these methods suffer from limitations in accuracy. Depth estimation through inverse modeling provides only approximate values and does not account for variations in surface properties, while the regression approach for the attenuation coefficient is only able to generalize a value through several data points which lacks precision and may lead to significant errors in estimation. Additionally, there is currently no established modeling method available for predicting bottom reflectance. This research proposed a novel solution based on neural networks for parameter estimation in LIDAR data analysis. By leveraging the power of neural networks, the proposed solution successfully learned the inversion model, was able to do prediction of parameters such as depth, attenuation coefficient, and bottom reflectance. Performance of model was validated by testing it on real LiDAR data. In future, more data availability would enable more accuracy and reliability of such models.
Data Fusion for Multi-Task Learning of Building Extraction and Height Estimation
Aug 05, 2023
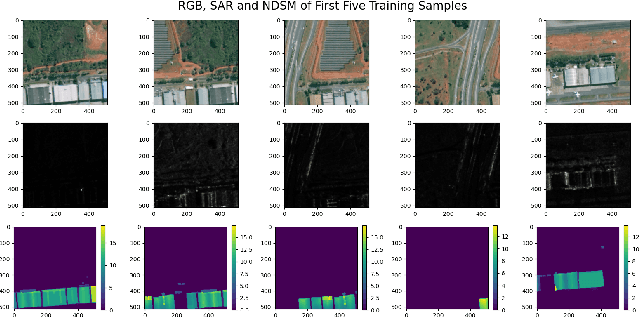

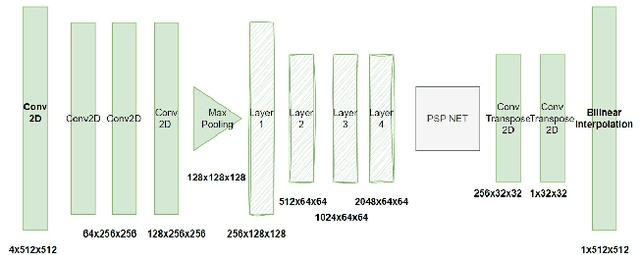
In accordance with the urban reconstruction problem proposed by the DFC23 Track 2 Contest, this paper attempts a multitask-learning method of building extraction and height estimation using both optical and radar satellite imagery. Contrary to the initial goal of multitask learning which could potentially give a superior solution by reusing features and forming implicit constraints between multiple tasks, this paper reports the individual implementation of the building extraction and height estimation under constraints. The baseline results for the building extraction and the height estimation significantly increased after designed experiments.
Emoji Prediction using Transformer Models
Jul 16, 2023In recent years, the use of emojis in social media has increased dramatically, making them an important element in understanding online communication. However, predicting the meaning of emojis in a given text is a challenging task due to their ambiguous nature. In this study, we propose a transformer-based approach for emoji prediction using BERT, a widely-used pre-trained language model. We fine-tuned BERT on a large corpus of text containing both text and emojis to predict the most appropriate emoji for a given text. Our experimental results demonstrate that our approach outperforms several state-of-the-art models in predicting emojis with an accuracy of over 75 percent. This work has potential applications in natural language processing, sentiment analysis, and social media marketing.