 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-Resolution Landscape Dataset for Concept-Based XAI With Application to Species Distribution Models
Apr 14, 2026Mapping the spatial distribution of species is essential for conservation policy and invasive species management. Species distribution models (SDMs) are the primary tools for this task, serving two purposes: achieving robust predictive performance while providing ecological insights into the driving factors of distribution. However, the increasing complexity of deep learning SDMs has made extracting these insights more challenging. To reconcile these objectives, we propose the first implementation of concept-based Explainable AI (XAI) for SDMs. We leverage the Robust TCAV (Testing with Concept Activation Vectors) methodology to quantify the influence of landscape concepts on model predictions. To enable this, we provide a new open-access landscape concept dataset derived from high-resolution multispectral and LiDAR drone imagery. It includes 653 patches across 15 distinct landscape concepts and 1,450 random reference patches, designed to suit a wide range of species. We demonstrate this approach through a case study of two aquatic insects, Plecoptera and Trichoptera, using two Convolutional Neural Networks and one Vision Transformer. Results show that concept-based XAI helps validate SDMs against expert knowledge while uncovering novel associations that generate new ecological hypotheses. Robust TCAV also provides landscape-level information, useful for policy-making and land management. Code and datasets are publicly available.
Plant detection from ultra high resolution remote sensing images: A Semantic Segmentation approach based on fuzzy loss
Aug 31, 2024



In this study, we tackle the challenge of identifying plant species from ultra high resolution (UHR) remote sensing images. Our approach involves introducing an RGB remote sensing dataset, characterized by millimeter-level spatial resolution, meticulously curated through several field expeditions across a mountainous region in France covering various landscapes. The task of plant species identification is framed as a semantic segmentation problem for its practical and efficient implementation across vast geographical areas. However, when dealing with segmentation masks, we confront instances where distinguishing boundaries between plant species and their background is challenging. We tackle this issue by introducing a fuzzy loss within the segmentation model. Instead of utilizing one-hot encoded ground truth (GT), our model incorporates Gaussian filter refined GT, introducing stochasticity during training. First experimental results obtained on both our UHR dataset and a public dataset are presented, showing the relevance of the proposed methodology, as well as the need for future improvement.
3DMASC: Accessible, explainable 3D point clouds classification. Application to Bi-spectral Topo-bathymetric lidar data
Jan 15, 2024Three-dimensional data have become increasingly present in earth observation over the last decades. However, many 3D surveys are still underexploited due to the lack of accessible and explainable automatic classification methods, for example, new topo-bathymetric lidar data. In this work, we introduce explainable machine learning for 3D data classification using Multiple Attributes, Scales, and Clouds under 3DMASC, a new workflow. This workflow introduces multi-cloud classification through dual-cloud features, encrypting local spectral and geometrical ratios and differences. 3DMASC uses classical multi-scale descriptors adapted to all types of 3D point clouds and new ones based on their spatial variations. In this paper, we present the performances of 3DMASC for multi-class classification of topo-bathymetric lidar data in coastal and fluvial environments. We show how multivariate and embedded feature selection allows the building of optimized predictor sets of reduced complexity, and we identify features particularly relevant for coastal and riverine scene descriptions. Our results show the importance of dual-cloud features, lidar return-based attributes averaged over specific scales, and of statistics of dimensionality-based and spectral features. Additionally, they indicate that small to medium spherical neighbourhood diameters (<7 m) are sufficient to build effective classifiers, namely when combined with distance-to-ground or distance-to-water-surface features. Without using optional RGB information, and with a maximum of 37 descriptors, we obtain classification accuracies between 91 % for complex multi-class tasks and 98 % for lower-level processing using models trained on less than 2000 samples per class. Comparisons with classical point cloud classification methods show that 3DMASC features have a significantly improved descriptive power. Our contributions are made available through a plugin in the CloudCompare software, allowing non-specialist users to create classifiers for any type of 3D data characterized by 1 or 2 point clouds (airborne or terrestrial lidar, structure from motion), and two labelled topo-bathymetric lidar datasets, available on https://opentopography.org/.
Estimation of Physical Parameters of Waveforms With Neural Networks
Dec 05, 2023
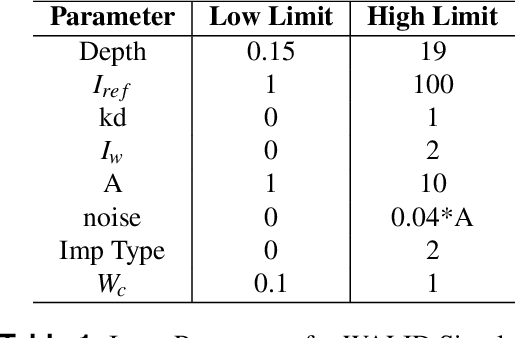

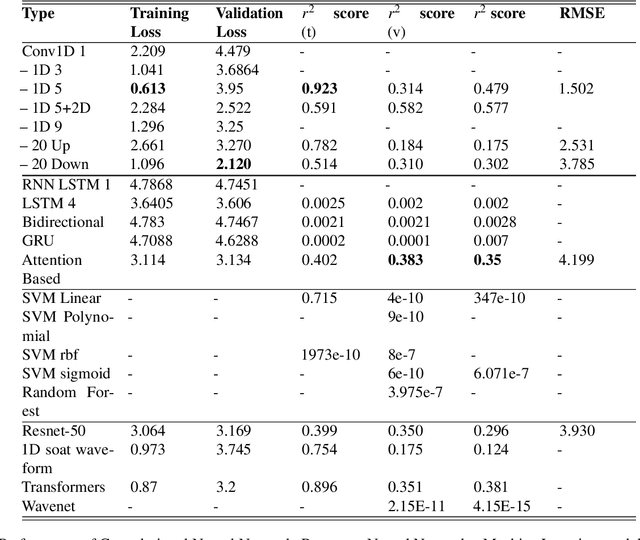
Light Detection and Ranging (LiDAR) are fast emerging sensors in the field of Earth Observation. It is a remote sensing technology that utilizes laser beams to measure distances and create detailed three-dimensional representations of objects and environments. The potential of Full Waveform LiDAR is much greater than just height estimation and 3D reconstruction only. Overall shape of signal provides important information about properties of water body. However, the shape of FWL is unexplored as most LiDAR software work on point cloud by utilizing the maximum value within the waveform. Existing techniques in the field of LiDAR data analysis include depth estimation through inverse modeling and regression of logarithmic intensity and depth for approximating the attenuation coefficient. However, these methods suffer from limitations in accuracy. Depth estimation through inverse modeling provides only approximate values and does not account for variations in surface properties, while the regression approach for the attenuation coefficient is only able to generalize a value through several data points which lacks precision and may lead to significant errors in estimation. Additionally, there is currently no established modeling method available for predicting bottom reflectance. This research proposed a novel solution based on neural networks for parameter estimation in LIDAR data analysis. By leveraging the power of neural networks, the proposed solution successfully learned the inversion model, was able to do prediction of parameters such as depth, attenuation coefficient, and bottom reflectance. Performance of model was validated by testing it on real LiDAR data. In future, more data availability would enable more accuracy and reliability of such models.
DC3DCD: unsupervised learning for multiclass 3D point cloud change detection
May 09, 2023
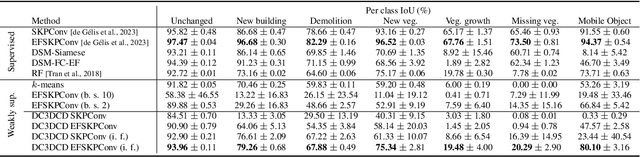
In a constant evolving world, change detection is of prime importance to keep updated maps. To better sense areas with complex geometry (urban areas in particular), considering 3D data appears to be an interesting alternative to classical 2D images. In this context, 3D point clouds (PCs) obtained by LiDAR or photogrammetry are very interesting. While recent studies showed the considerable benefit of using deep learning-based methods to detect and characterize changes into raw 3D PCs, these studies rely on large annotated training data to obtain accurate results. The collection of these annotations are tricky and time-consuming. The availability of unsupervised or weakly supervised approaches is then of prime interest. In this paper, we propose an unsupervised method, called DeepCluster 3D Change Detection (DC3DCD), to detect and categorize multiclass changes at point level. We classify our approach in the unsupervised family given the fact that we extract in a completely unsupervised way a number of clusters associated with potential changes. Let us precise that in the end of the process, the user has only to assign a label to each of these clusters to derive the final change map. Our method builds upon the DeepCluster approach, originally designed for image classification, to handle complex raw 3D PCs and perform change segmentation task. An assessment of the method on both simulated and real public dataset is provided. The proposed method allows to outperform fully-supervised traditional machine learning algorithm and to be competitive with fully-supervised deep learning networks applied on rasterization of 3D PCs with a mean of IoU over classes of change of 57.06% and 66.69% for the simulated and the real datasets, respectively.
Deep Unsupervised Learning for 3D ALS Point Clouds Change Detection
May 05, 2023


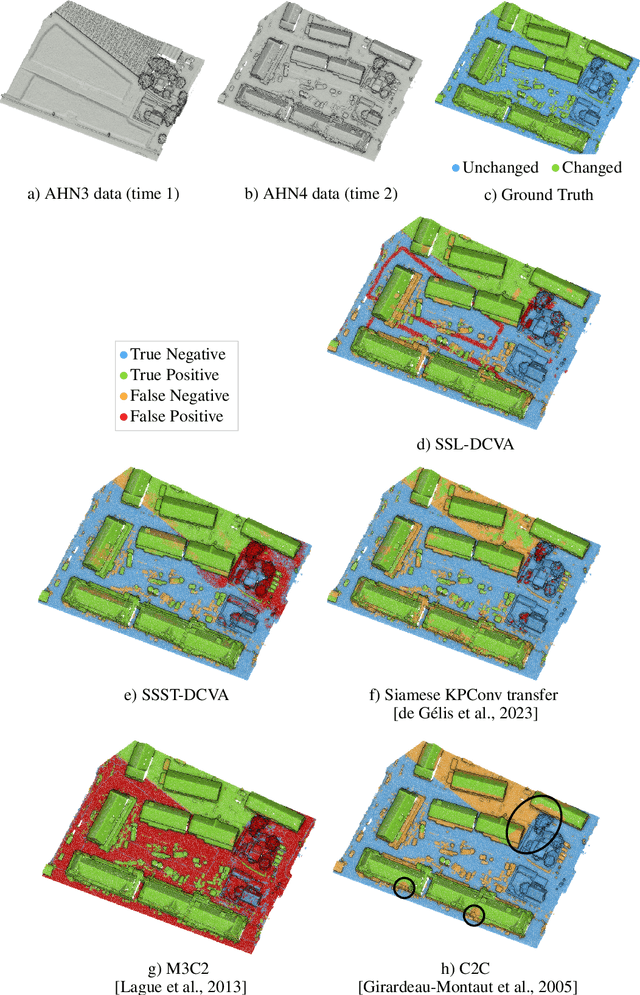
Change detection from traditional optical images has limited capability to model the changes in the height or shape of objects. Change detection using 3D point cloud aerial LiDAR survey data can fill this gap by providing critical depth information. While most existing machine learning based 3D point cloud change detection methods are supervised, they severely depend on the availability of annotated training data, which is in practice a critical point. To circumnavigate this dependence, we propose an unsupervised 3D point cloud change detection method mainly based on self-supervised learning using deep clustering and contrastive learning. The proposed method also relies on an adaptation of deep change vector analysis to 3D point cloud via nearest point comparison. Experiments conducted on a publicly available real dataset show that the proposed method obtains higher performance in comparison to the traditional unsupervised methods, with a gain of about 9% in mean accuracy (to reach more than 85%). Thus, it appears to be a relevant choice in scenario where prior knowledge (labels) is not ensured.
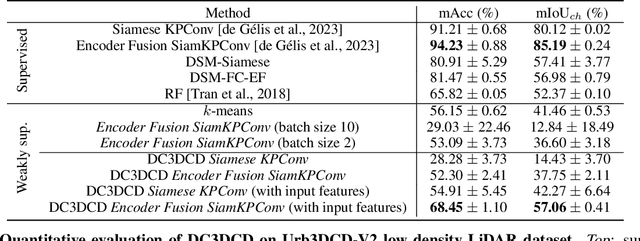
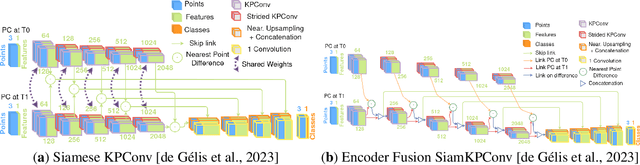
Change detection needs change information: improving deep 3D point cloud change detection
Apr 25, 2023



Change detection is an important task to rapidly identify modified areas, in particular when multi-temporal data are concerned. In landscapes with complex geometry such as urban environment, vertical information turn out to be a very useful knowledge not only to highlight changes but also to classify them into different categories. In this paper, we focus on change segmentation directly using raw 3D point clouds (PCs), to avoid any loss of information due to rasterization processes. While deep learning has recently proved its effectiveness for this particular task by encoding the information through Siamese networks, we investigate here the idea of also using change information in early steps of deep networks. To do this, we first propose to provide the Siamese KPConv State-of-The-Art (SoTA) network with hand-crafted features and especially a change-related one. This improves the mean of Intersection over Union (IoU) over classes of change by 4.70\%. Considering that the major improvement was obtained thanks to the change-related feature, we propose three new architectures to address 3D PCs change segmentation: OneConvFusion, Triplet KPConv, and Encoder Fusion SiamKPConv. All the three networks take into account change information in early steps and outperform SoTA methods. In particular, the last network, entitled Encoder Fusion SiamKPConv, overtakes SoTA with more than 5% of mean of IoU over classes of change emphasizing the value of having the network focus on change information for change detection task.
Learning Digital Terrain Models from Point Clouds: ALS2DTM Dataset and Rasterization-based GAN
Jun 08, 2022
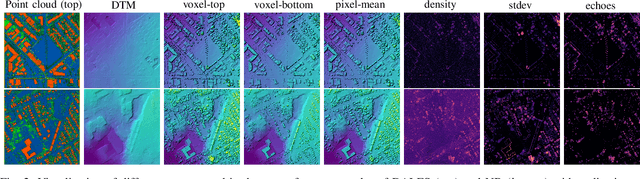
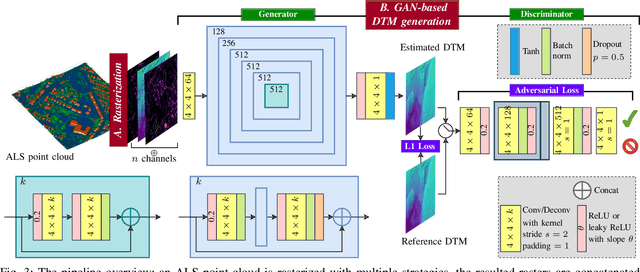
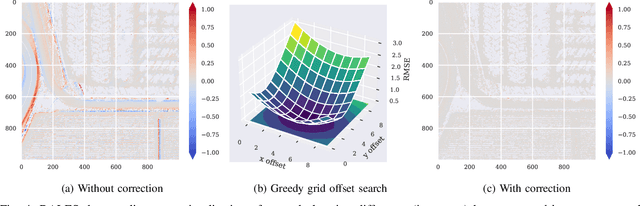
Despite the popularity of deep neural networks in various domains, the extraction of digital terrain models (DTMs) from airborne laser scanning (ALS) point clouds is still challenging. This might be due to the lack of dedicated large-scale annotated dataset and the data-structure discrepancy between point clouds and DTMs. To promote data-driven DTM extraction, this paper collects from open sources a large-scale dataset of ALS point clouds and corresponding DTMs with various urban, forested, and mountainous scenes. A baseline method is proposed as the first attempt to train a Deep neural network to extract digital Terrain models directly from ALS point clouds via Rasterization techniques, coined DeepTerRa. Extensive studies with well-established methods are performed to benchmark the dataset and analyze the challenges in learning to extract DTM from point clouds. The experimental results show the interest of the agnostic data-driven approach, with sub-metric error level compared to methods designed for DTM extraction. The data and source code is provided at https://lhoangan.github.io/deepterra/ for reproducibility and further similar research.
Convolutional Neural Network Modelling for MODIS Land Surface Temperature Super-Resolution
Apr 01, 2022



Nowadays, thermal infrared satellite remote sensors enable to extract very interesting information at large scale, in particular Land Surface Temperature (LST). However such data are limited in spatial and/or temporal resolutions which prevents from an analysis at fine scales. For example, MODIS satellite provides daily acquisitions with 1Km spatial resolutions which is not sufficient to deal with highly heterogeneous environments as agricultural parcels. Therefore, image super-resolution is a crucial task to better exploit MODIS LSTs. This issue is tackled in this paper. We introduce a deep learning-based algorithm, named Multi-residual U-Net, for super-resolution of MODIS LST single-images. Our proposed network is a modified version of U-Net architecture, which aims at super-resolving the input LST image from 1Km to 250m per pixel. The results show that our Multi-residual U-Net outperforms other state-of-the-art methods.
A deep neural network for multi-species fish detection using multiple acoustic cameras
Sep 22, 2021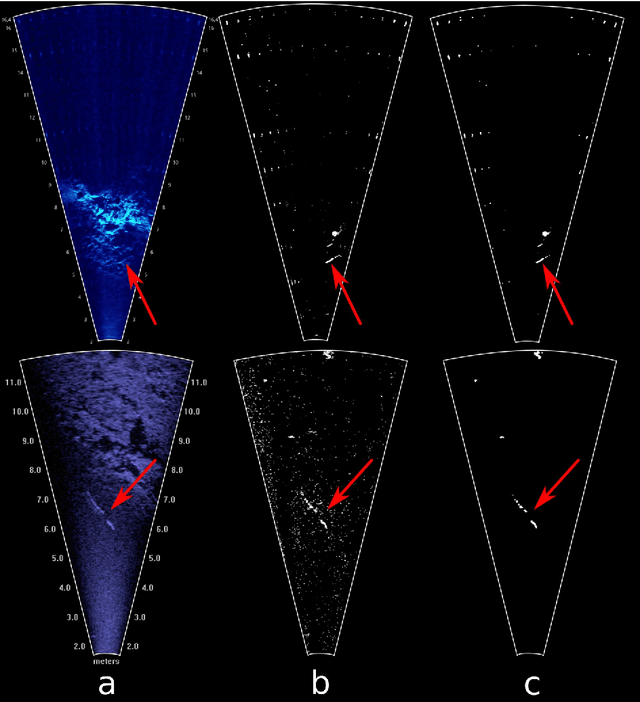
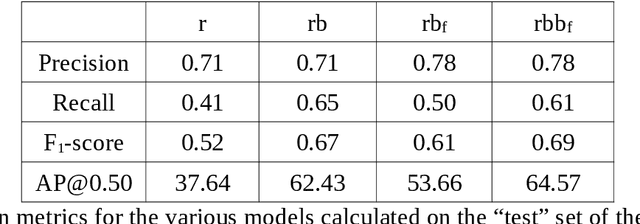
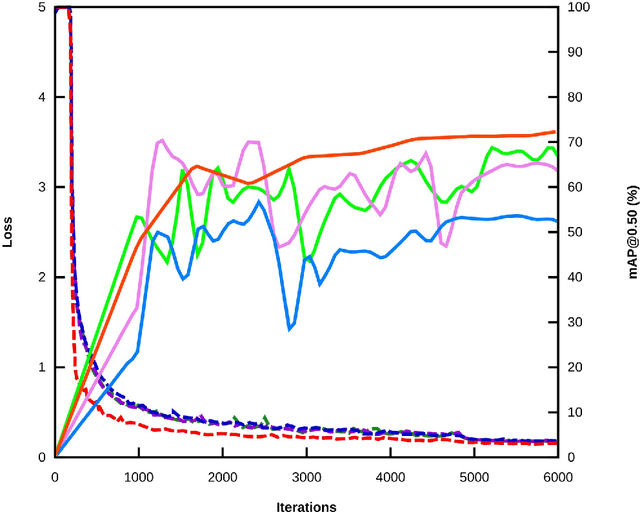
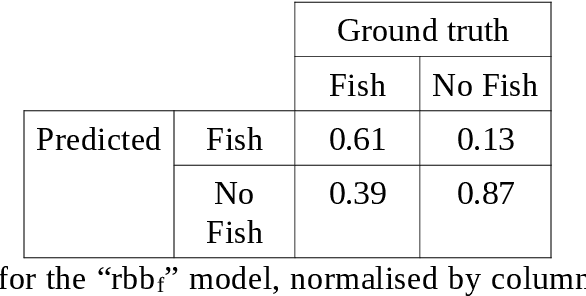
Underwater acoustic cameras are high potential devices for many applications in ecology, notably for fisheries management and monitoring. However how to extract such data into high value information without a time-consuming entire dataset reading by an operator is still a challenge. Moreover the analysis of acoustic imaging, due to its low signal-to-noise ratio, is a perfect training ground for experimenting with new approaches, especially concerning Deep Learning techniques. We present hereby a novel approach that takes advantage of both CNN (Convolutional Neural Network) and classical CV (Computer Vision) techniques, able to detect a generic class ''fish'' in acoustic video streams. The pipeline pre-treats the acoustic images to extract 2 features, in order to localise the signals and improve the detection performances. To ensure the performances from an ecological point of view, we propose also a two-step validation, one to validate the results of the trainings and one to test the method on a real-world scenario. The YOLOv3-based model was trained with data of fish from multiple species recorded by the two common acoustic cameras, DIDSON and ARIS, including species of high ecological interest, as Atlantic salmon or European eels. The model we developed provides satisfying results detecting almost 80% of fish and minimizing the false positive rate, however the model is much less efficient for eel detections on ARIS videos. The first CNN pipeline for fish monitoring exploiting video data from two models of acoustic cameras satisfies most of the required features. Many challenges are still present, such as the automation of fish species identification through a multiclass model. 1 However the results point a new solution for dealing with complex data, such as sonar data, which can also be reapplied in other cases where the signal-to-noise ratio is a challenge.