 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox for Mask and Mask for Box: weak losses for multi-task partially supervised learning
Nov 26, 2024Object detection and semantic segmentation are both scene understanding tasks yet they differ in data structure and information level. Object detection requires box coordinates for object instances while semantic segmentation requires pixel-wise class labels. Making use of one task's information to train the other would be beneficial for multi-task partially supervised learning where each training example is annotated only for a single task, having the potential to expand training sets with different-task datasets. This paper studies various weak losses for partially annotated data in combination with existing supervised losses. We propose Box-for-Mask and Mask-for-Box strategies, and their combination BoMBo, to distil necessary information from one task annotations to train the other. Ablation studies and experimental results on VOC and COCO datasets show favorable results for the proposed idea. Source code and data splits can be found at https://github.com/lhoangan/multas.
Leveraging knowledge distillation for partial multi-task learning from multiple remote sensing datasets
May 24, 2024Partial multi-task learning where training examples are annotated for one of the target tasks is a promising idea in remote sensing as it allows combining datasets annotated for different tasks and predicting more tasks with fewer network parameters. The na\"ive approach to partial multi-task learning is sub-optimal due to the lack of all-task annotations for learning joint representations. This paper proposes using knowledge distillation to replace the need of ground truths for the alternate task and enhance the performance of such approach. Experiments conducted on the public ISPRS 2D Semantic Labeling Contest dataset show the effectiveness of the proposed idea on partial multi-task learning for semantic tasks including object detection and semantic segmentation in aerial images.
Leveraging feature communication in federated learning for remote sensing image classification
Mar 20, 2024In the realm of Federated Learning (FL) applied to remote sensing image classification, this study introduces and assesses several innovative communication strategies. Our exploration includes feature-centric communication, pseudo-weight amalgamation, and a combined method utilizing both weights and features. Experiments conducted on two public scene classification datasets unveil the effectiveness of these strategies, showcasing accelerated convergence, heightened privacy, and reduced network information exchange. This research provides valuable insights into the implications of feature-centric communication in FL, offering potential applications tailored for remote sensing scenarios.
Data exploitation: multi-task learning of object detection and semantic segmentation on partially annotated data
Nov 07, 2023Multi-task partially annotated data where each data point is annotated for only a single task are potentially helpful for data scarcity if a network can leverage the inter-task relationship. In this paper, we study the joint learning of object detection and semantic segmentation, the two most popular vision problems, from multi-task data with partial annotations. Extensive experiments are performed to evaluate each task performance and explore their complementarity when a multi-task network cannot optimize both tasks simultaneously. We propose employing knowledge distillation to leverage joint-task optimization. The experimental results show favorable results for multi-task learning and knowledge distillation over single-task learning and even full supervision scenario. All code and data splits are available at https://github.com/lhoangan/multas
Self-Training and Multi-Task Learning for Limited Data: Evaluation Study on Object Detection
Sep 12, 2023Self-training allows a network to learn from the predictions of a more complicated model, thus often requires well-trained teacher models and mixture of teacher-student data while multi-task learning jointly optimizes different targets to learn salient interrelationship and requires multi-task annotations for each training example. These frameworks, despite being particularly data demanding have potentials for data exploitation if such assumptions can be relaxed. In this paper, we compare self-training object detection under the deficiency of teacher training data where students are trained on unseen examples by the teacher, and multi-task learning with partially annotated data, i.e. single-task annotation per training example. Both scenarios have their own limitation but potentially helpful with limited annotated data. Experimental results show the improvement of performance when using a weak teacher with unseen data for training a multi-task student. Despite the limited setup we believe the experimental results show the potential of multi-task knowledge distillation and self-training, which could be beneficial for future study. Source code is at https://lhoangan.github.io/multas.
Knowledge Distillation for Object Detection: from generic to remote sensing datasets
Jul 18, 2023



Knowledge distillation, a well-known model compression technique, is an active research area in both computer vision and remote sensing communities. In this paper, we evaluate in a remote sensing context various off-the-shelf object detection knowledge distillation methods which have been originally developed on generic computer vision datasets such as Pascal VOC. In particular, methods covering both logit mimicking and feature imitation approaches are applied for vehicle detection using the well-known benchmarks such as xView and VEDAI datasets. Extensive experiments are performed to compare the relative performance and interrelationships of the methods. Experimental results show high variations and confirm the importance of result aggregation and cross validation on remote sensing datasets.
Learning Digital Terrain Models from Point Clouds: ALS2DTM Dataset and Rasterization-based GAN
Jun 08, 2022
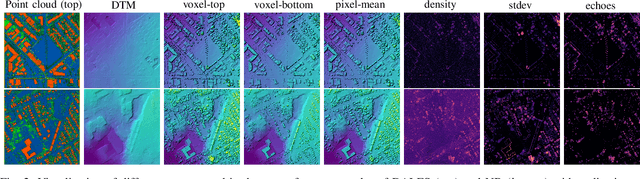
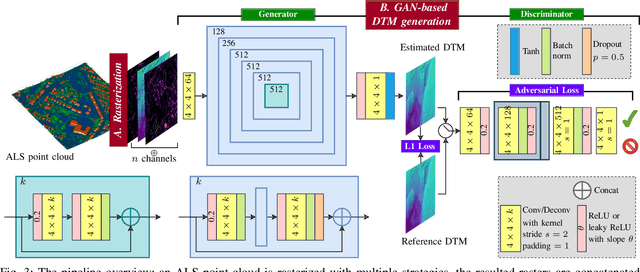
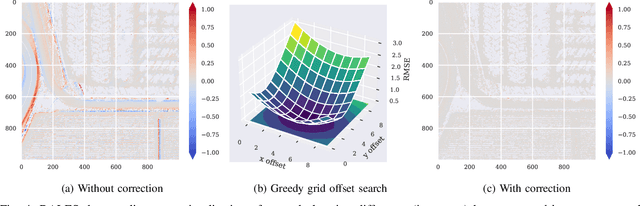
Despite the popularity of deep neural networks in various domains, the extraction of digital terrain models (DTMs) from airborne laser scanning (ALS) point clouds is still challenging. This might be due to the lack of dedicated large-scale annotated dataset and the data-structure discrepancy between point clouds and DTMs. To promote data-driven DTM extraction, this paper collects from open sources a large-scale dataset of ALS point clouds and corresponding DTMs with various urban, forested, and mountainous scenes. A baseline method is proposed as the first attempt to train a Deep neural network to extract digital Terrain models directly from ALS point clouds via Rasterization techniques, coined DeepTerRa. Extensive studies with well-established methods are performed to benchmark the dataset and analyze the challenges in learning to extract DTM from point clouds. The experimental results show the interest of the agnostic data-driven approach, with sub-metric error level compared to methods designed for DTM extraction. The data and source code is provided at https://lhoangan.github.io/deepterra/ for reproducibility and further similar research.
Detection of Degraded Acacia tree species using deep neural networks on uav drone imagery
Apr 14, 2022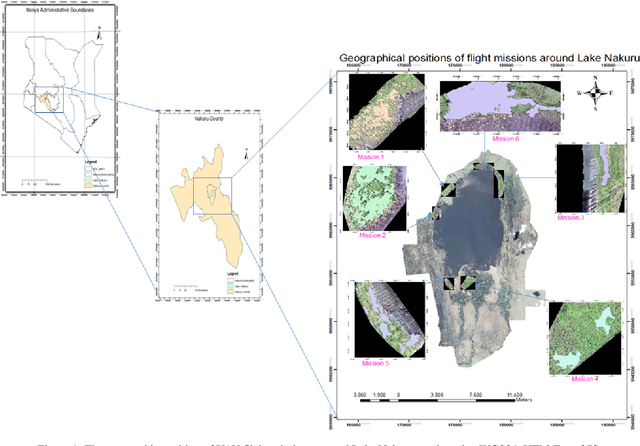


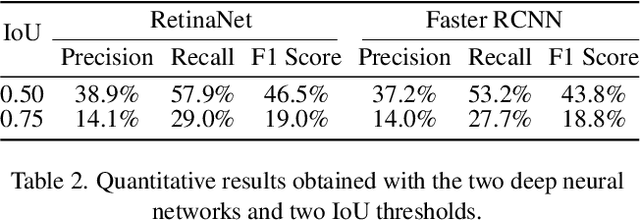
Deep-learning-based image classification and object detection has been applied successfully to tree monitoring. However, studies of tree crowns and fallen trees, especially on flood inundated areas, remain largely unexplored. Detection of degraded tree trunks on natural environments such as water, mudflats, and natural vegetated areas is challenging due to the mixed colour image backgrounds. In this paper, Unmanned Aerial Vehicles (UAVs), or drones, with embedded RGB cameras were used to capture the fallen Acacia Xanthophloea trees from six designated plots around Lake Nakuru, Kenya. Motivated by the need to detect fallen trees around the lake, two well-established deep neural networks, i.e. Faster Region-based Convolution Neural Network (Faster R-CNN) and Retina-Net were used for fallen tree detection. A total of 7,590 annotations of three classes on 256 x 256 image patches were used for this study. Experimental results show the relevance of deep learning in this context, with Retina-Net model achieving 38.9% precision and 57.9% recall.
CroCo: Cross-Modal Contrastive learning for localization of Earth Observation data
Apr 14, 2022

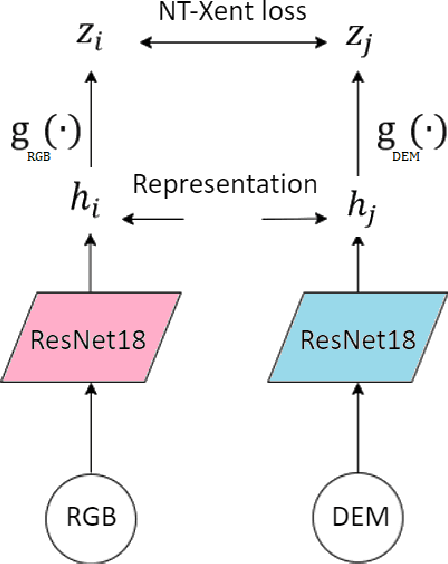
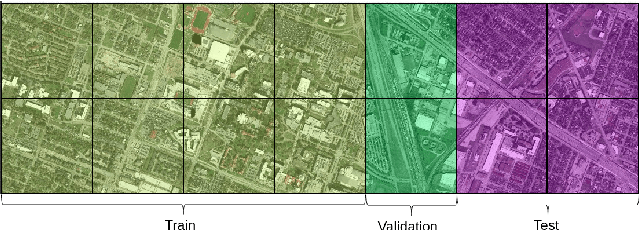
It is of interest to localize a ground-based LiDAR point cloud on remote sensing imagery. In this work, we tackle a subtask of this problem, i.e. to map a digital elevation model (DEM) rasterized from aerial LiDAR point cloud on the aerial imagery. We proposed a contrastive learning-based method that trains on DEM and high-resolution optical imagery and experiment the framework on different data sampling strategies and hyperparameters. In the best scenario, the Top-1 score of 0.71 and Top-5 score of 0.81 are obtained. The proposed method is promising for feature learning from RGB and DEM for localization and is potentially applicable to other data sources too. Source code will be released at https://github.com/wtseng530/AVLocalization.