 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Class Depression Detection Through Tweets using Artificial Intelligence
Apr 19, 2024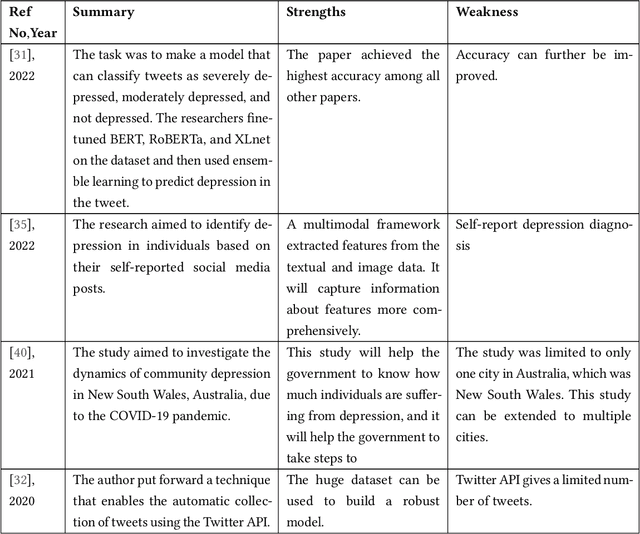

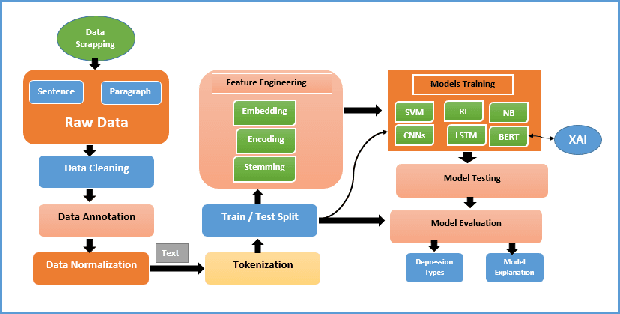
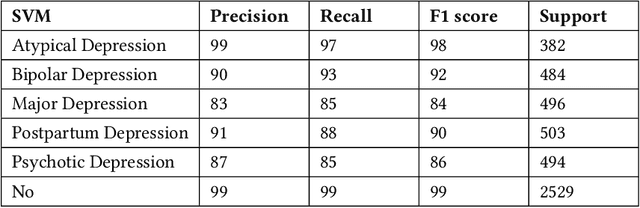
Depression is a significant issue nowadays. As per the World Health Organization (WHO), in 2023, over 280 million individuals are grappling with depression. This is a huge number; if not taken seriously, these numbers will increase rapidly. About 4.89 billion individuals are social media users. People express their feelings and emotions on platforms like Twitter, Facebook, Reddit, Instagram, etc. These platforms contain valuable information which can be used for research purposes. Considerable research has been conducted across various social media platforms. However, certain limitations persist in these endeavors. Particularly, previous studies were only focused on detecting depression and the intensity of depression in tweets. Also, there existed inaccuracies in dataset labeling. In this research work, five types of depression (Bipolar, major, psychotic, atypical, and postpartum) were predicted using tweets from the Twitter database based on lexicon labeling. Explainable AI was used to provide reasoning by highlighting the parts of tweets that represent type of depression. Bidirectional Encoder Representations from Transformers (BERT) was used for feature extraction and training. Machine learning and deep learning methodologies were used to train the model. The BERT model presented the most promising results, achieving an overall accuracy of 0.96.
Emoji Prediction using Transformer Models
Jul 16, 2023In recent years, the use of emojis in social media has increased dramatically, making them an important element in understanding online communication. However, predicting the meaning of emojis in a given text is a challenging task due to their ambiguous nature. In this study, we propose a transformer-based approach for emoji prediction using BERT, a widely-used pre-trained language model. We fine-tuned BERT on a large corpus of text containing both text and emojis to predict the most appropriate emoji for a given text. Our experimental results demonstrate that our approach outperforms several state-of-the-art models in predicting emojis with an accuracy of over 75 percent. This work has potential applications in natural language processing, sentiment analysis, and social media marketing.