 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Class Depression Detection Through Tweets using Artificial Intelligence
Apr 19, 2024

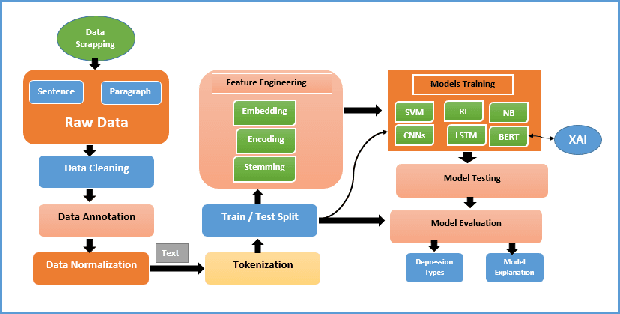
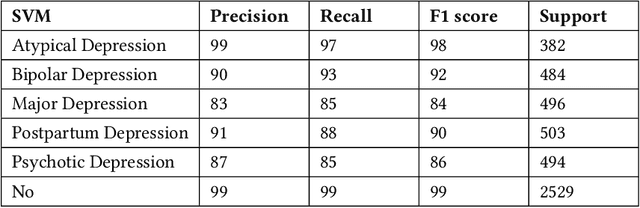
Depression is a significant issue nowadays. As per the World Health Organization (WHO), in 2023, over 280 million individuals are grappling with depression. This is a huge number; if not taken seriously, these numbers will increase rapidly. About 4.89 billion individuals are social media users. People express their feelings and emotions on platforms like Twitter, Facebook, Reddit, Instagram, etc. These platforms contain valuable information which can be used for research purposes. Considerable research has been conducted across various social media platforms. However, certain limitations persist in these endeavors. Particularly, previous studies were only focused on detecting depression and the intensity of depression in tweets. Also, there existed inaccuracies in dataset labeling. In this research work, five types of depression (Bipolar, major, psychotic, atypical, and postpartum) were predicted using tweets from the Twitter database based on lexicon labeling. Explainable AI was used to provide reasoning by highlighting the parts of tweets that represent type of depression. Bidirectional Encoder Representations from Transformers (BERT) was used for feature extraction and training. Machine learning and deep learning methodologies were used to train the model. The BERT model presented the most promising results, achieving an overall accuracy of 0.96.
Hierarchical Text Classification of Urdu News using Deep Neural Network
Jul 07, 2021



Digital text is increasing day by day on the internet. It is very challenging to classify a large and heterogeneous collection of data, which require improved information processing methods to organize text. To classify large size of corpus, one common approach is to use hierarchical text classification, which aims to classify textual data in a hierarchical structure. Several approaches have been proposed to tackle classification of text but most of the research has been done on English language. This paper proposes a deep learning model for hierarchical text classification of news in Urdu language - consisting of 51,325 sentences from 8 online news websites belonging to the following genres: Sports; Technology; and Entertainment. The objectives of this paper are twofold: (1) to develop a large human-annotated dataset of news in Urdu language for hierarchical text classification; and (2) to classify Urdu news hierarchically using our proposed model based on LSTM mechanism named as Hierarchical Multi-layer LSTMs (HMLSTM). Our model consists of two modules: Text Representing Layer, for obtaining text representation in which we use Word2vec embedding to transform the words to vector and Urdu Hierarchical LSTM Layer (UHLSTML) an end-to-end fully connected deep LSTMs network to perform automatic feature learning, we train one LSTM layer for each level of the class hierarchy. We have performed extensive experiments on our self created dataset named as Urdu News Dataset for Hierarchical Text Classification (UNDHTC). The result shows that our proposed method is very effective for hierarchical text classification and it outperforms baseline methods significantly and also achieved good results as compare to deep neural model.
Co-occurrences using Fasttext embeddings for word similarity tasks in Urdu
Feb 22, 2021

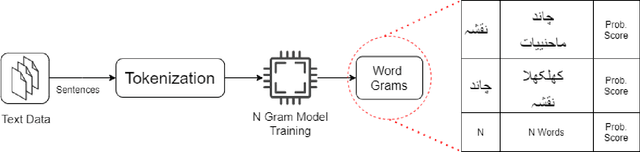
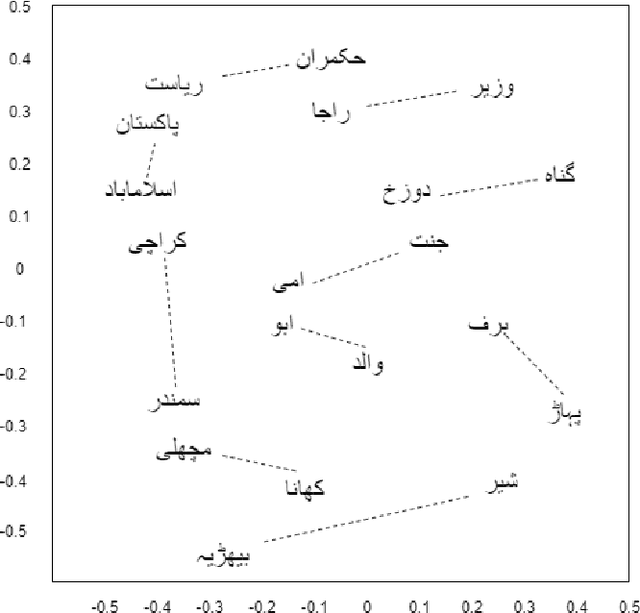
Urdu is a widely spoken language in South Asia. Though immoderate literature exists for the Urdu language still the data isn't enough to naturally process the language by NLP techniques. Very efficient language models exist for the English language, a high resource language, but Urdu and other under-resourced languages have been neglected for a long time. To create efficient language models for these languages we must have good word embedding models. For Urdu, we can only find word embeddings trained and developed using the skip-gram model. In this paper, we have built a corpus for Urdu by scraping and integrating data from various sources and compiled a vocabulary for the Urdu language. We also modify fasttext embeddings and N-Grams models to enable training them on our built corpus. We have used these trained embeddings for a word similarity task and compared the results with existing techniques.
NUBOT: Embedded Knowledge Graph With RASA Framework for Generating Semantic Intents Responses in Roman Urdu
Feb 20, 2021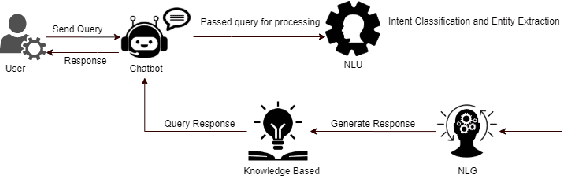
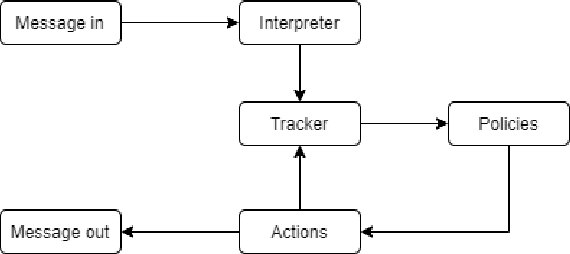
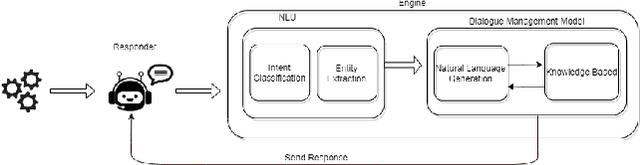
The understanding of the human language is quantified by identifying intents and entities. Even though classification methods that rely on labeled information are often used for the comprehension of language understanding, it is incredibly time consuming and tedious process to generate high propensity supervised datasets. In this paper, we present the generation of accurate intents for the corresponding Roman Urdu unstructured data and integrate this corpus in RASA NLU module for intent classification. We embed knowledge graph with RASA Framework to maintain the dialog history for semantic based natural language mechanism for chatbot communication. We compare results of our work with existing linguistic systems combined with semantic technologies. Minimum accuracy of intents generation is 64 percent of confidence and in the response generation part minimum accuracy is 82.1 percent and maximum accuracy gain is 96.7 percent. All the scores refers to log precision, recall, and f1 measure for each intents once summarized for all. Furthermore, it creates a confusion matrix represents that which intents are ambiguously recognized by approach.
A Diverse Clustering Particle Swarm Optimizer for Dynamic Environment: To Locate and Track Multiple Optima
May 19, 2020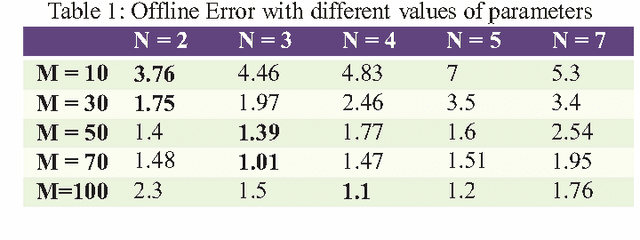
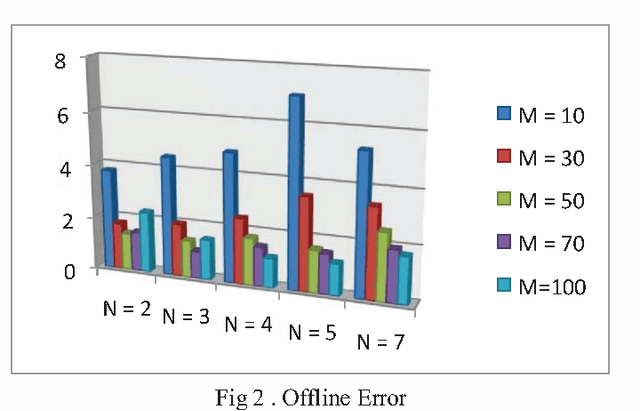
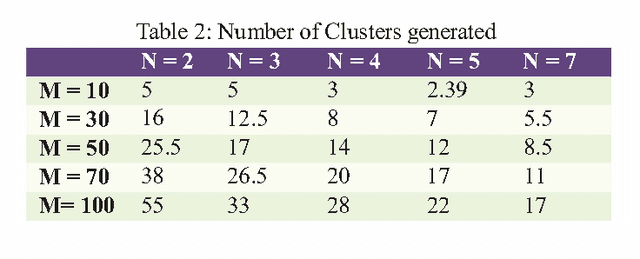
In real life, mostly problems are dynamic. Many algorithms have been proposed to handle the static problems, but these algorithms do not handle or poorly handle the dynamic environment problems. Although, many algorithms have been proposed to handle dynamic problems but still, there are some limitations or drawbacks in every algorithm regarding diversity of particles and tracking of already found optima. To overcome these limitations/drawbacks, we have proposed a new efficient algorithm to handle the dynamic environment effectively by tracking and locating multiple optima and by improving the diversity and convergence speed of algorithm. In this algorithm, a new method has been proposed which explore the undiscovered areas of search space to increase the diversity of algorithm. This algorithm also uses a method to effectively handle the overlapped and overcrowded particles. Branke has proposed moving peak benchmark which is commonly used MBP in literature. We also have performed different experiments on Moving Peak Benchmark. After comparing the experimental results with different state of art algorithms, it was seen that our algorithm performed more efficiently.