 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention Based Neural Network for Code Switching Detection: English & Roman Urdu
Mar 03, 2021
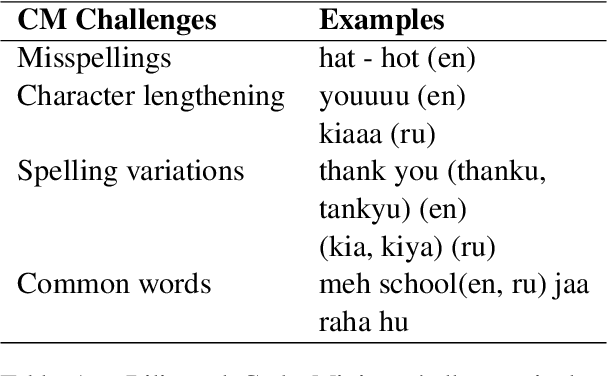
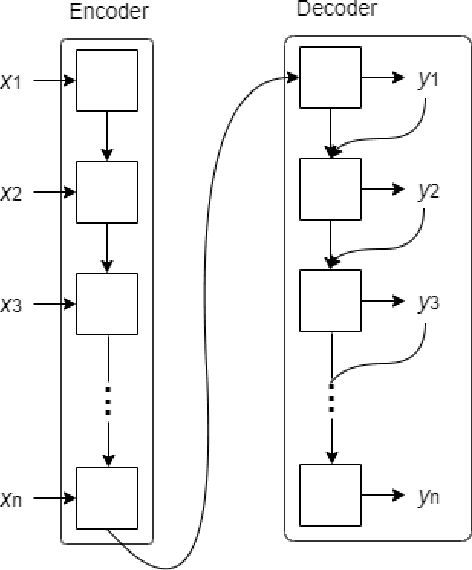

Code-switching is a common phenomenon among people with diverse lingual background and is widely used on the internet for communication purposes. In this paper, we present a Recurrent Neural Network combined with the Attention Model for Language Identification in Code-Switched Data in English and low resource Roman Urdu. The attention model enables the architecture to learn the important features of the languages hence classifying the code switched data. We demonstrated our approach by comparing the results with state of the art models i.e. Hidden Markov Models, Conditional Random Field and Bidirectional LSTM. The models evaluation, using confusion matrix metrics, showed that the attention mechanism provides improved the precision and accuracy as compared to the other models.
Co-occurrences using Fasttext embeddings for word similarity tasks in Urdu
Feb 22, 2021

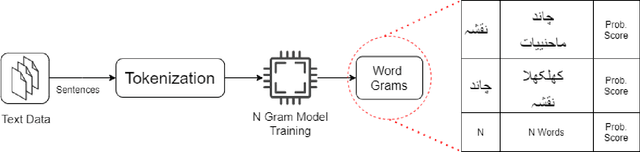
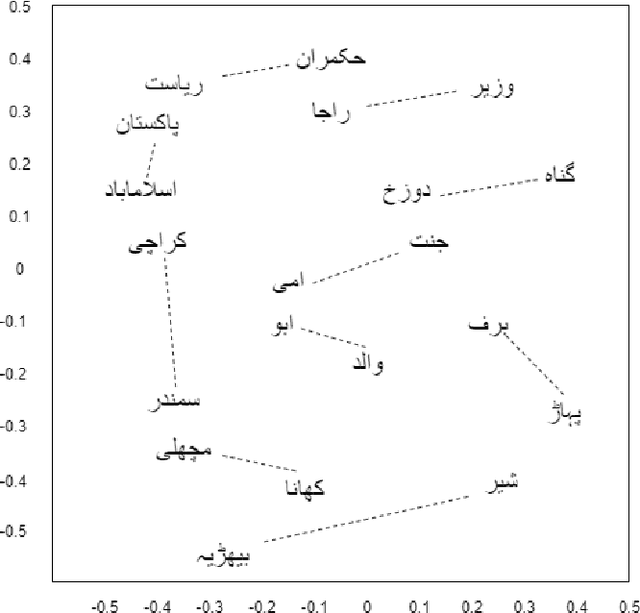
Urdu is a widely spoken language in South Asia. Though immoderate literature exists for the Urdu language still the data isn't enough to naturally process the language by NLP techniques. Very efficient language models exist for the English language, a high resource language, but Urdu and other under-resourced languages have been neglected for a long time. To create efficient language models for these languages we must have good word embedding models. For Urdu, we can only find word embeddings trained and developed using the skip-gram model. In this paper, we have built a corpus for Urdu by scraping and integrating data from various sources and compiled a vocabulary for the Urdu language. We also modify fasttext embeddings and N-Grams models to enable training them on our built corpus. We have used these trained embeddings for a word similarity task and compared the results with existing techniques.