 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUBERT: A Bilingual Roman Urdu BERT Using Cross Lingual Transfer Learning
Feb 22, 2021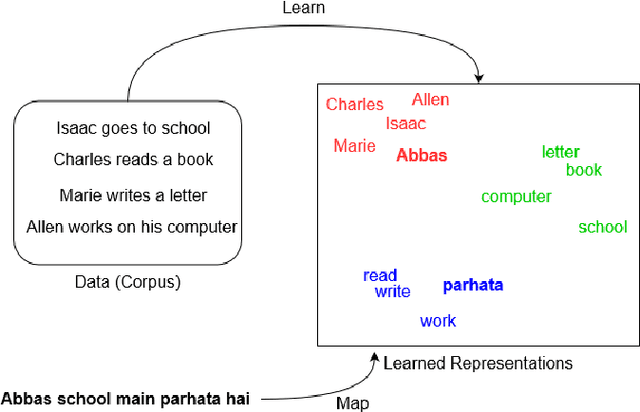

In recent studies, it has been shown that Multilingual language models underperform their monolingual counterparts. It is also a well-known fact that training and maintaining monolingual models for each language is a costly and time-consuming process. Roman Urdu is a resource-starved language used popularly on social media platforms and chat apps. In this research, we propose a novel dataset of scraped tweets containing 54M tokens and 3M sentences. Additionally, we also propose RUBERT a bilingual Roman Urdu model created by additional pretraining of English BERT. We compare its performance with a monolingual Roman Urdu BERT trained from scratch and a multilingual Roman Urdu BERT created by additional pretraining of Multilingual BERT. We show through our experiments that additional pretraining of the English BERT produces the most notable performance improvement.
Bilingual Language Modeling, A transfer learning technique for Roman Urdu
Feb 22, 2021


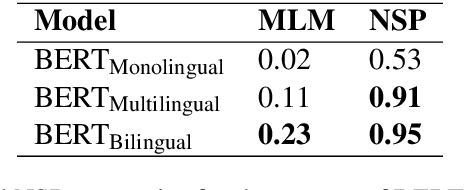
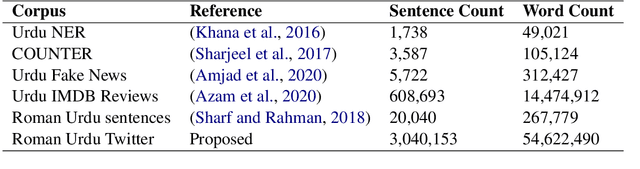
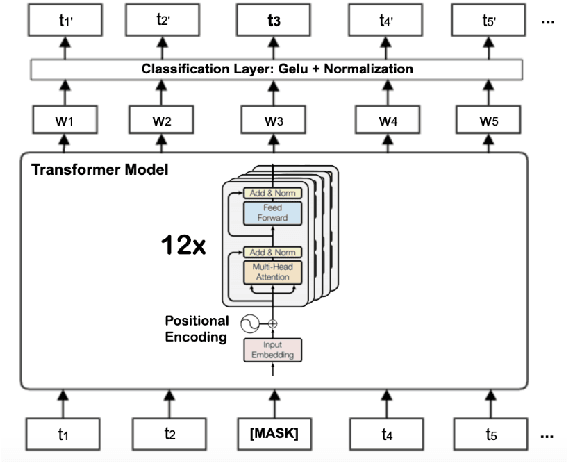
Pretrained language models are now of widespread use in Natural Language Processing. Despite their success, applying them to Low Resource languages is still a huge challenge. Although Multilingual models hold great promise, applying them to specific low-resource languages e.g. Roman Urdu can be excessive. In this paper, we show how the code-switching property of languages may be used to perform cross-lingual transfer learning from a corresponding high resource language. We also show how this transfer learning technique termed Bilingual Language Modeling can be used to produce better performing models for Roman Urdu. To enable training and experimentation, we also present a collection of novel corpora for Roman Urdu extracted from various sources and social networking sites, e.g. Twitter. We train Monolingual, Multilingual, and Bilingual models of Roman Urdu - the proposed bilingual model achieves 23% accuracy compared to the 2% and 11% of the monolingual and multilingual models respectively in the Masked Language Modeling (MLM) task.
Co-occurrences using Fasttext embeddings for word similarity tasks in Urdu
Feb 22, 2021

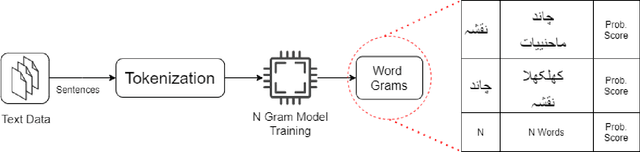
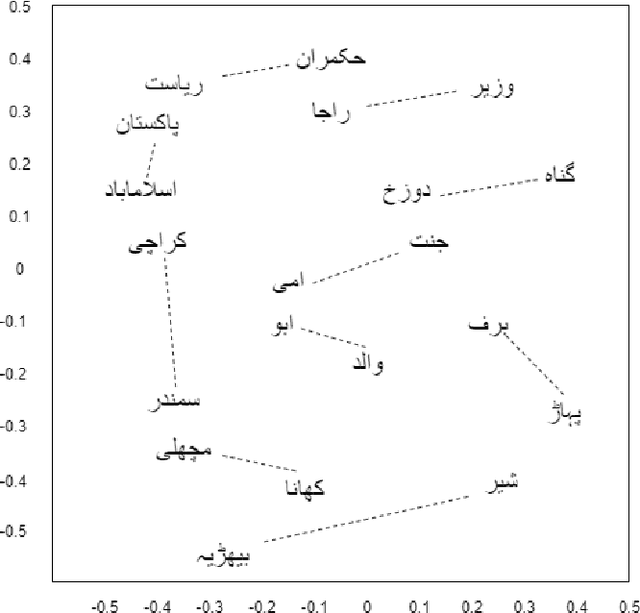
Urdu is a widely spoken language in South Asia. Though immoderate literature exists for the Urdu language still the data isn't enough to naturally process the language by NLP techniques. Very efficient language models exist for the English language, a high resource language, but Urdu and other under-resourced languages have been neglected for a long time. To create efficient language models for these languages we must have good word embedding models. For Urdu, we can only find word embeddings trained and developed using the skip-gram model. In this paper, we have built a corpus for Urdu by scraping and integrating data from various sources and compiled a vocabulary for the Urdu language. We also modify fasttext embeddings and N-Grams models to enable training them on our built corpus. We have used these trained embeddings for a word similarity task and compared the results with existing techniques.
Few Shot Learning for Information Verification
Feb 22, 2021
Information verification is quite a challenging task, this is because many times verifying a claim can require picking pieces of information from multiple pieces of evidence which can have a hierarchy of complex semantic relations. Previously a lot of researchers have mainly focused on simply concatenating multiple evidence sentences to accept or reject claims. These approaches are limited as evidence can contain hierarchical information and dependencies. In this research, we aim to verify facts based on evidence selected from a list of articles taken from Wikipedia. Pretrained language models such as XLNET are used to generate meaningful representations and graph-based attention and convolutions are used in such a way that the system requires little additional training to learn to verify facts.