 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning based Speech Affect Recognition in Urdu
Mar 05, 2021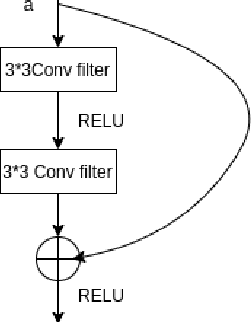

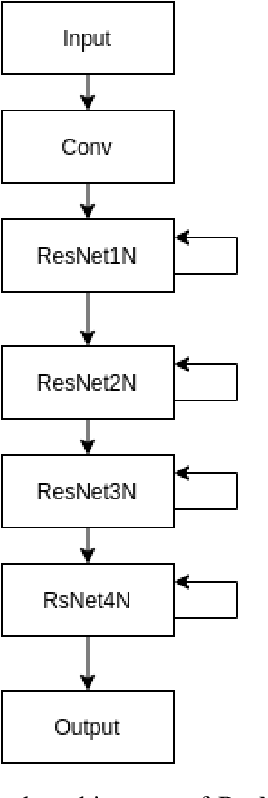
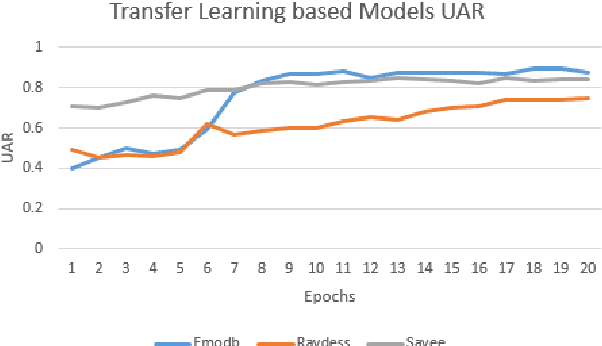
It has been established that Speech Affect Recognition for low resource languages is a difficult task. Here we present a Transfer learning based Speech Affect Recognition approach in which: we pre-train a model for high resource language affect recognition task and fine tune the parameters for low resource language using Deep Residual Network. Here we use standard four data sets to demonstrate that transfer learning can solve the problem of data scarcity for Affect Recognition task. We demonstrate that our approach is efficient by achieving 74.7 percent UAR on RAVDESS as source and Urdu data set as a target. Through an ablation study, we have identified that pre-trained model adds most of the features information, improvement in results and solves less data issues. Using this knowledge, we have also experimented on SAVEE and EMO-DB data set by setting Urdu as target language where only 400 utterances of data is available. This approach achieves high Unweighted Average Recall (UAR) when compared with existing algorithms.
An Attention Based Neural Network for Code Switching Detection: English & Roman Urdu
Mar 03, 2021
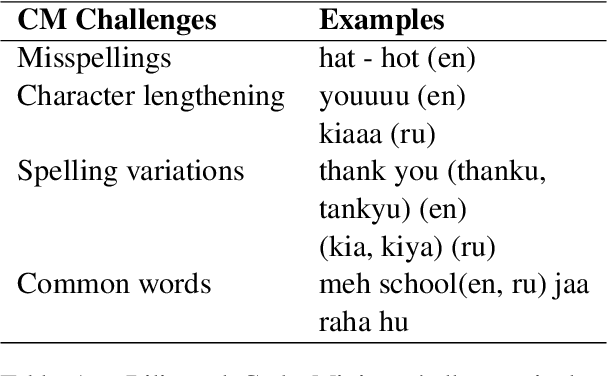
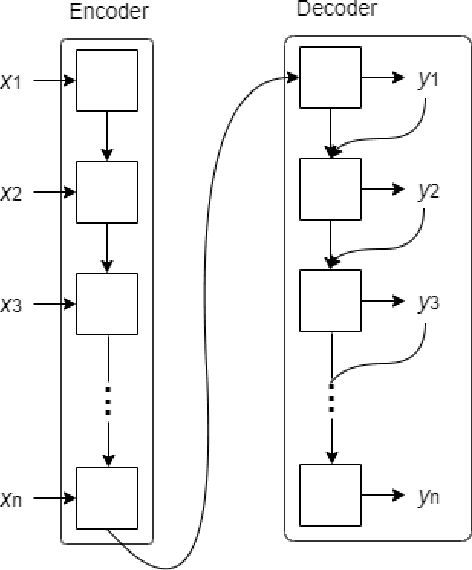

Code-switching is a common phenomenon among people with diverse lingual background and is widely used on the internet for communication purposes. In this paper, we present a Recurrent Neural Network combined with the Attention Model for Language Identification in Code-Switched Data in English and low resource Roman Urdu. The attention model enables the architecture to learn the important features of the languages hence classifying the code switched data. We demonstrated our approach by comparing the results with state of the art models i.e. Hidden Markov Models, Conditional Random Field and Bidirectional LSTM. The models evaluation, using confusion matrix metrics, showed that the attention mechanism provides improved the precision and accuracy as compared to the other models.
RUBERT: A Bilingual Roman Urdu BERT Using Cross Lingual Transfer Learning
Feb 22, 2021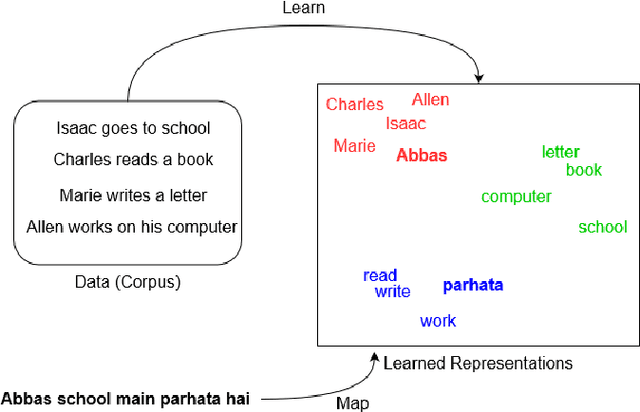
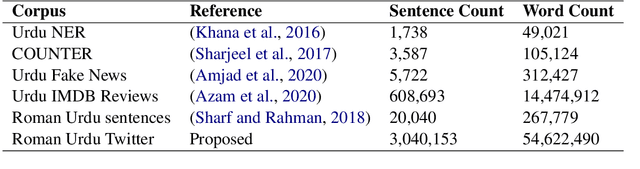
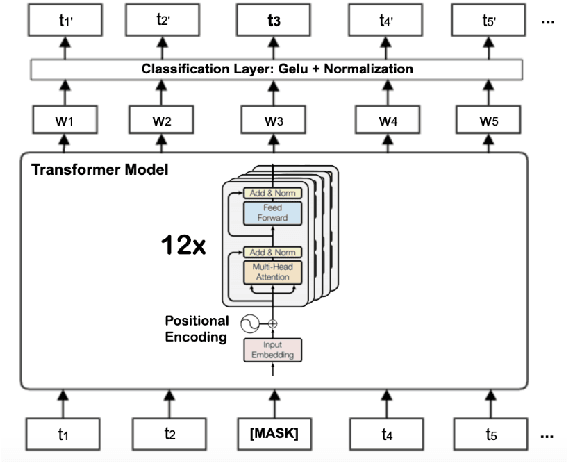

In recent studies, it has been shown that Multilingual language models underperform their monolingual counterparts. It is also a well-known fact that training and maintaining monolingual models for each language is a costly and time-consuming process. Roman Urdu is a resource-starved language used popularly on social media platforms and chat apps. In this research, we propose a novel dataset of scraped tweets containing 54M tokens and 3M sentences. Additionally, we also propose RUBERT a bilingual Roman Urdu model created by additional pretraining of English BERT. We compare its performance with a monolingual Roman Urdu BERT trained from scratch and a multilingual Roman Urdu BERT created by additional pretraining of Multilingual BERT. We show through our experiments that additional pretraining of the English BERT produces the most notable performance improvement.
Bilingual Language Modeling, A transfer learning technique for Roman Urdu
Feb 22, 2021


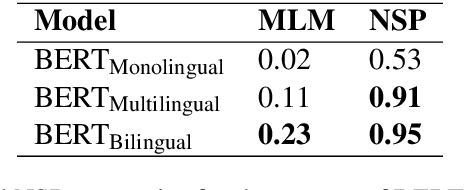
Pretrained language models are now of widespread use in Natural Language Processing. Despite their success, applying them to Low Resource languages is still a huge challenge. Although Multilingual models hold great promise, applying them to specific low-resource languages e.g. Roman Urdu can be excessive. In this paper, we show how the code-switching property of languages may be used to perform cross-lingual transfer learning from a corresponding high resource language. We also show how this transfer learning technique termed Bilingual Language Modeling can be used to produce better performing models for Roman Urdu. To enable training and experimentation, we also present a collection of novel corpora for Roman Urdu extracted from various sources and social networking sites, e.g. Twitter. We train Monolingual, Multilingual, and Bilingual models of Roman Urdu - the proposed bilingual model achieves 23% accuracy compared to the 2% and 11% of the monolingual and multilingual models respectively in the Masked Language Modeling (MLM) task.
Co-occurrences using Fasttext embeddings for word similarity tasks in Urdu
Feb 22, 2021

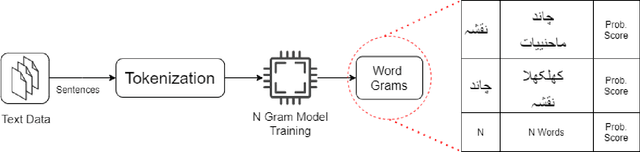
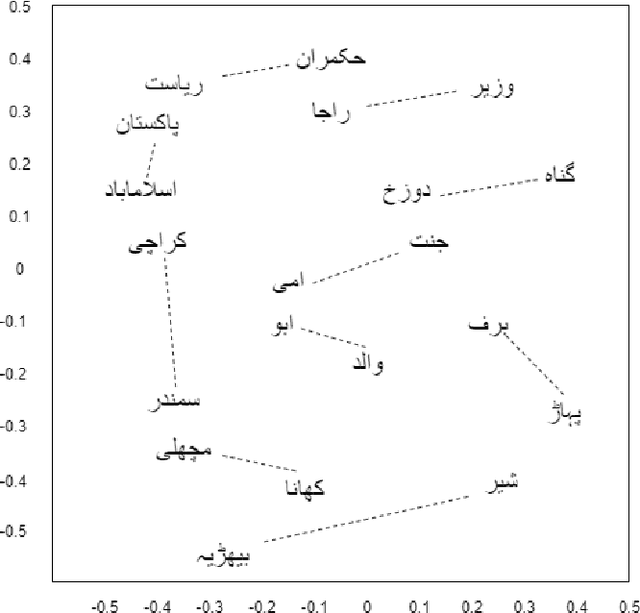
Urdu is a widely spoken language in South Asia. Though immoderate literature exists for the Urdu language still the data isn't enough to naturally process the language by NLP techniques. Very efficient language models exist for the English language, a high resource language, but Urdu and other under-resourced languages have been neglected for a long time. To create efficient language models for these languages we must have good word embedding models. For Urdu, we can only find word embeddings trained and developed using the skip-gram model. In this paper, we have built a corpus for Urdu by scraping and integrating data from various sources and compiled a vocabulary for the Urdu language. We also modify fasttext embeddings and N-Grams models to enable training them on our built corpus. We have used these trained embeddings for a word similarity task and compared the results with existing techniques.
NUBOT: Embedded Knowledge Graph With RASA Framework for Generating Semantic Intents Responses in Roman Urdu
Feb 20, 2021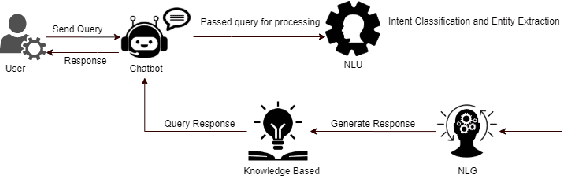
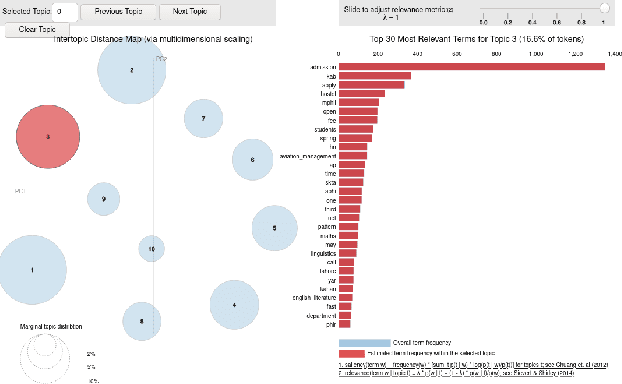
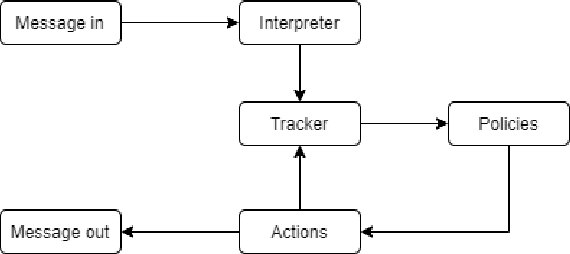
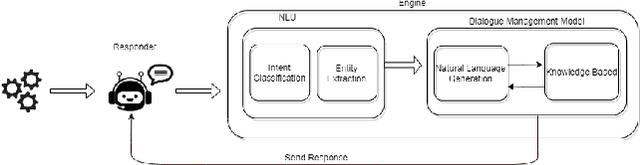
The understanding of the human language is quantified by identifying intents and entities. Even though classification methods that rely on labeled information are often used for the comprehension of language understanding, it is incredibly time consuming and tedious process to generate high propensity supervised datasets. In this paper, we present the generation of accurate intents for the corresponding Roman Urdu unstructured data and integrate this corpus in RASA NLU module for intent classification. We embed knowledge graph with RASA Framework to maintain the dialog history for semantic based natural language mechanism for chatbot communication. We compare results of our work with existing linguistic systems combined with semantic technologies. Minimum accuracy of intents generation is 64 percent of confidence and in the response generation part minimum accuracy is 82.1 percent and maximum accuracy gain is 96.7 percent. All the scores refers to log precision, recall, and f1 measure for each intents once summarized for all. Furthermore, it creates a confusion matrix represents that which intents are ambiguously recognized by approach.