 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning based Speech Affect Recognition in Urdu
Paper and Code
Mar 05, 2021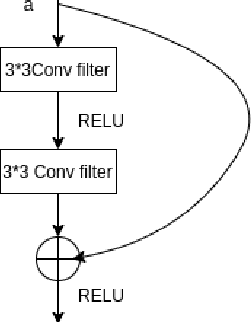

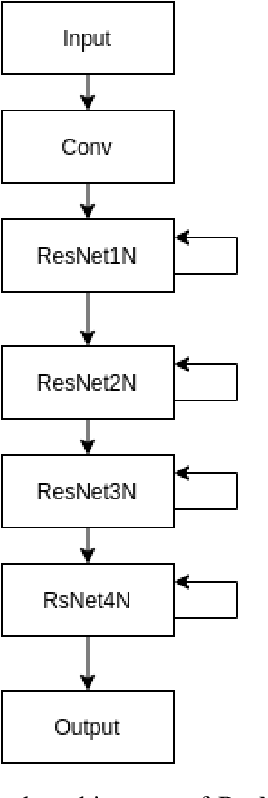
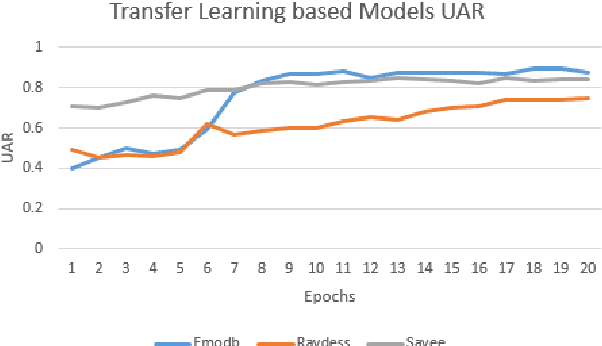
It has been established that Speech Affect Recognition for low resource languages is a difficult task. Here we present a Transfer learning based Speech Affect Recognition approach in which: we pre-train a model for high resource language affect recognition task and fine tune the parameters for low resource language using Deep Residual Network. Here we use standard four data sets to demonstrate that transfer learning can solve the problem of data scarcity for Affect Recognition task. We demonstrate that our approach is efficient by achieving 74.7 percent UAR on RAVDESS as source and Urdu data set as a target. Through an ablation study, we have identified that pre-trained model adds most of the features information, improvement in results and solves less data issues. Using this knowledge, we have also experimented on SAVEE and EMO-DB data set by setting Urdu as target language where only 400 utterances of data is available. This approach achieves high Unweighted Average Recall (UAR) when compared with existing algorithms.