 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning based Speech Affect Recognition in Urdu
Mar 05, 2021

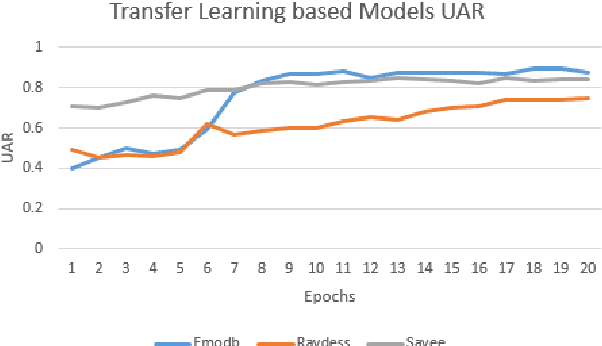
It has been established that Speech Affect Recognition for low resource languages is a difficult task. Here we present a Transfer learning based Speech Affect Recognition approach in which: we pre-train a model for high resource language affect recognition task and fine tune the parameters for low resource language using Deep Residual Network. Here we use standard four data sets to demonstrate that transfer learning can solve the problem of data scarcity for Affect Recognition task. We demonstrate that our approach is efficient by achieving 74.7 percent UAR on RAVDESS as source and Urdu data set as a target. Through an ablation study, we have identified that pre-trained model adds most of the features information, improvement in results and solves less data issues. Using this knowledge, we have also experimented on SAVEE and EMO-DB data set by setting Urdu as target language where only 400 utterances of data is available. This approach achieves high Unweighted Average Recall (UAR) when compared with existing algorithms.
Transfer learning from High-Resource to Low-Resource Language Improves Speech Affect Recognition Classification Accuracy
Mar 04, 2021

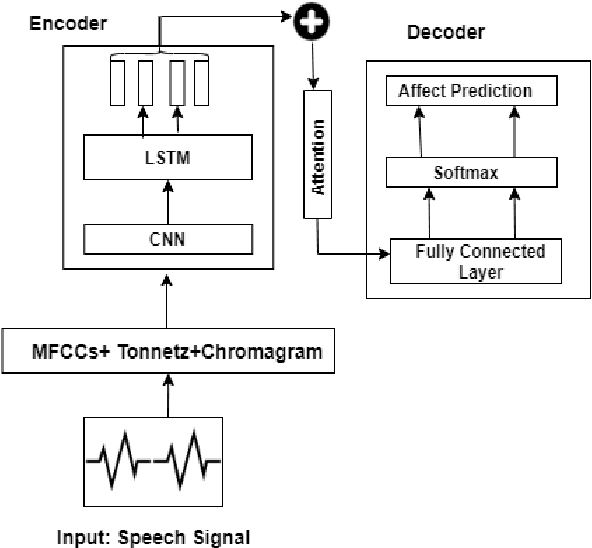
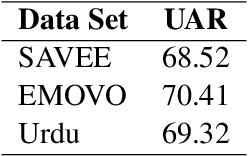
Speech Affect Recognition is a problem of extracting emotional affects from audio data. Low resource languages corpora are rear and affect recognition is a difficult task in cross-corpus settings. We present an approach in which the model is trained on high resource language and fine-tune to recognize affects in low resource language. We train the model in same corpus setting on SAVEE, EMOVO, Urdu, and IEMOCAP by achieving baseline accuracy of 60.45, 68.05, 80.34, and 56.58 percent respectively. For capturing the diversity of affects in languages cross-corpus evaluations are discussed in detail. We find that accuracy improves by adding the domain target data into the training data. Finally, we show that performance is improved for low resource language speech affect recognition by achieving the UAR OF 69.32 and 68.2 for Urdu and Italian speech affects.