 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning from High-Resource to Low-Resource Language Improves Speech Affect Recognition Classification Accuracy
Paper and Code
Mar 04, 2021

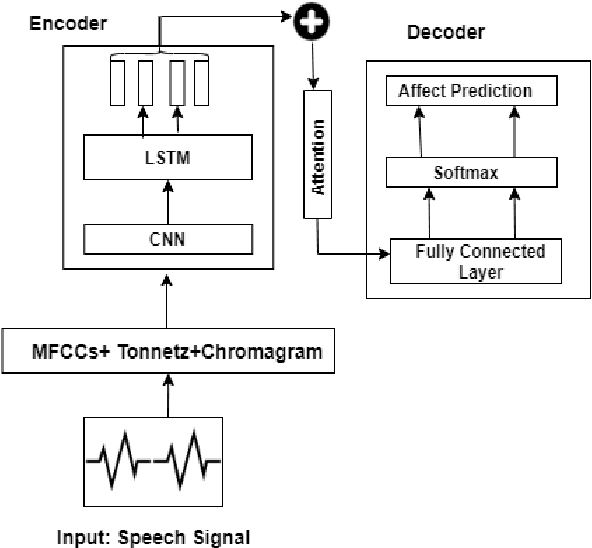
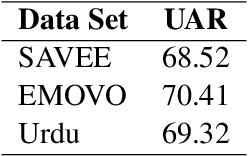
Speech Affect Recognition is a problem of extracting emotional affects from audio data. Low resource languages corpora are rear and affect recognition is a difficult task in cross-corpus settings. We present an approach in which the model is trained on high resource language and fine-tune to recognize affects in low resource language. We train the model in same corpus setting on SAVEE, EMOVO, Urdu, and IEMOCAP by achieving baseline accuracy of 60.45, 68.05, 80.34, and 56.58 percent respectively. For capturing the diversity of affects in languages cross-corpus evaluations are discussed in detail. We find that accuracy improves by adding the domain target data into the training data. Finally, we show that performance is improved for low resource language speech affect recognition by achieving the UAR OF 69.32 and 68.2 for Urdu and Italian speech affects.