 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNUBOT: Embedded Knowledge Graph With RASA Framework for Generating Semantic Intents Responses in Roman Urdu
Feb 20, 2021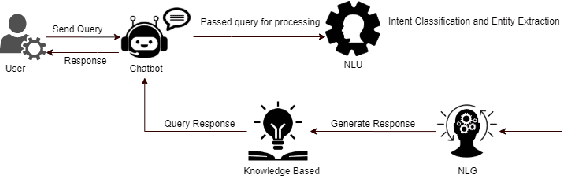
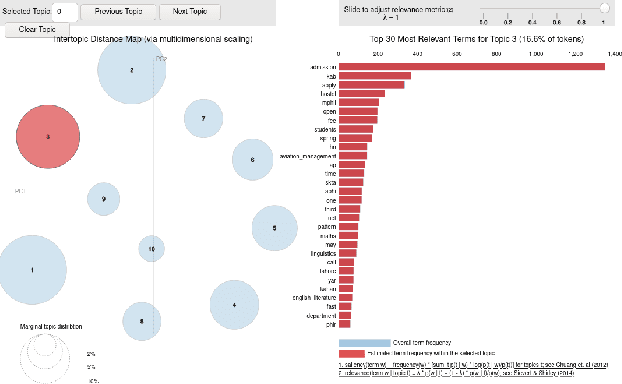
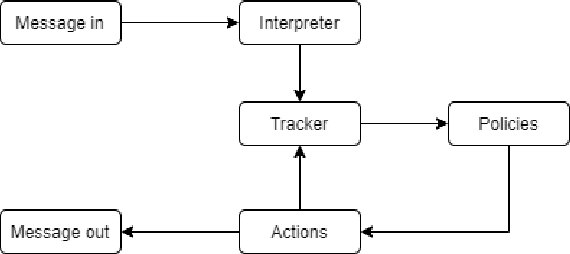
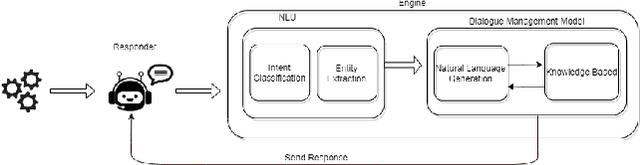
The understanding of the human language is quantified by identifying intents and entities. Even though classification methods that rely on labeled information are often used for the comprehension of language understanding, it is incredibly time consuming and tedious process to generate high propensity supervised datasets. In this paper, we present the generation of accurate intents for the corresponding Roman Urdu unstructured data and integrate this corpus in RASA NLU module for intent classification. We embed knowledge graph with RASA Framework to maintain the dialog history for semantic based natural language mechanism for chatbot communication. We compare results of our work with existing linguistic systems combined with semantic technologies. Minimum accuracy of intents generation is 64 percent of confidence and in the response generation part minimum accuracy is 82.1 percent and maximum accuracy gain is 96.7 percent. All the scores refers to log precision, recall, and f1 measure for each intents once summarized for all. Furthermore, it creates a confusion matrix represents that which intents are ambiguously recognized by approach.