 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUBERT: A Bilingual Roman Urdu BERT Using Cross Lingual Transfer Learning
Paper and Code
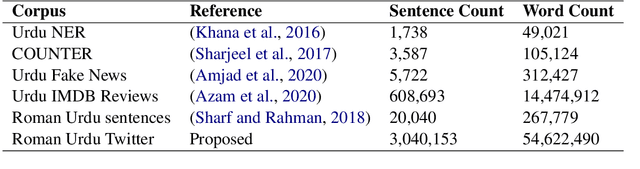
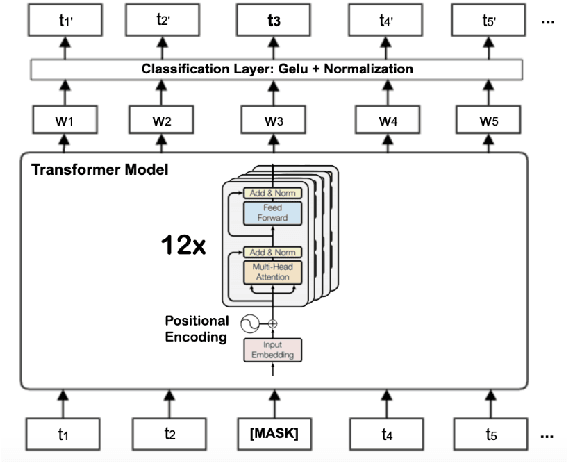

In recent studies, it has been shown that Multilingual language models underperform their monolingual counterparts. It is also a well-known fact that training and maintaining monolingual models for each language is a costly and time-consuming process. Roman Urdu is a resource-starved language used popularly on social media platforms and chat apps. In this research, we propose a novel dataset of scraped tweets containing 54M tokens and 3M sentences. Additionally, we also propose RUBERT a bilingual Roman Urdu model created by additional pretraining of English BERT. We compare its performance with a monolingual Roman Urdu BERT trained from scratch and a multilingual Roman Urdu BERT created by additional pretraining of Multilingual BERT. We show through our experiments that additional pretraining of the English BERT produces the most notable performance improvement.