 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Super-Resolution Methods via Incremental Residual Learning
Aug 21, 2018


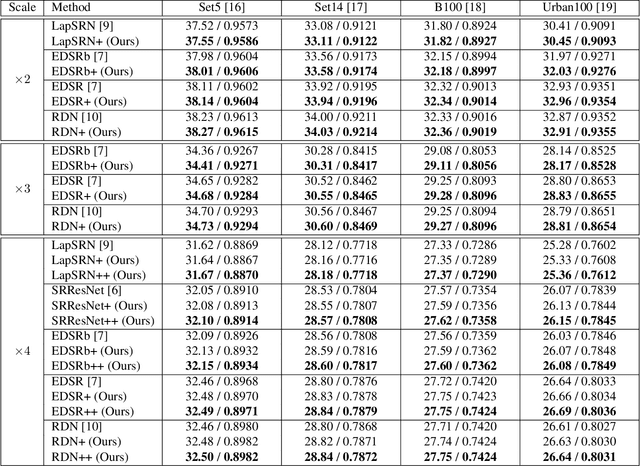
Recently, deep Convolutional Neural Networks (CNNs) have shown promising performance in accurate reconstruction of high resolution (HR) image, given its low resolution (LR) counter-part. However, recent state-of-the-art methods operate primarily on LR image for memory efficiency, but we show that it comes at the cost of performance. Furthermore, because spatial dimensions of input and output of such networks do not match, it's not possible to learn residuals in image space; we show that learning residuals in image space leads to performance enhancement. To this end, we propose a novel Incremental Residual Learning (IRL) framework to solve the above mentioned issues. In IRL, a set of branches i.e arbitrary image-to-image networks are trained sequentially where each branch takes spatially upsampled higher dimensional feature maps as input and predicts the residuals of all previous branches combined. We plug recent state of the art methods as base networks in IRL framework and demonstrate the consistent performance enhancement through extensive experiments on public benchmark datasets to set a new state of the art for super-resolution. Compared to the base networks our method incurs no extra memory overhead as only one branch is trained at a time. Furthermore, as our method is trained to learned residuals, complete set of branches are trained in only 20% of time relative to base network.
Sequence to Sequence Networks for Roman-Urdu to Urdu Transliteration
Dec 08, 2017


Neural Machine Translation models have replaced the conventional phrase based statistical translation methods since the former takes a generic, scalable, data-driven approach rather than relying on manual, hand-crafted features. The neural machine translation system is based on one neural network that is composed of two parts, one that is responsible for input language sentence and other part that handles the desired output language sentence. This model based on encoder-decoder architecture also takes as input the distributed representations of the source language which enriches the learnt dependencies and gives a warm start to the network. In this work, we transform Roman-Urdu to Urdu transliteration into sequence to sequence learning problem. To this end, we make the following contributions. We create the first ever parallel corpora of Roman-Urdu to Urdu, create the first ever distributed representation of Roman-Urdu and present the first neural machine translation model that transliterates text from Roman-Urdu to Urdu language. Our model has achieved the state-of-the-art results using BLEU as the evaluation metric. Precisely, our model is able to correctly predict sentences up to length 10 while achieving BLEU score of 48.6 on the test set. We are hopeful that our model and our results shall serve as the baseline for further work in the domain of neural machine translation for Roman-Urdu to Urdu using distributed representation.
End-to-end Trained CNN Encode-Decoder Networks for Image Steganography
Nov 20, 2017
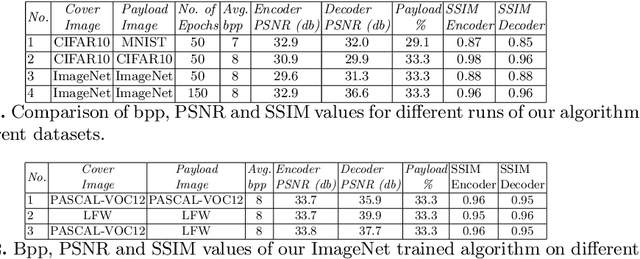

All the existing image steganography methods use manually crafted features to hide binary payloads into cover images. This leads to small payload capacity and image distortion. Here we propose a convolutional neural network based encoder-decoder architecture for embedding of images as payload. To this end, we make following three major contributions: (i) we propose a deep learning based generic encoder-decoder architecture for image steganography; (ii) we introduce a new loss function that ensures joint end-to-end training of encoder-decoder networks; (iii) we perform extensive empirical evaluation of proposed architecture on a range of challenging publicly available datasets (MNIST, CIFAR10, PASCAL-VOC12, ImageNet, LFW) and report state-of-the-art payload capacity at high PSNR and SSIM values.
Recovering Homography from Camera Captured Documents using Convolutional Neural Networks
Sep 11, 2017


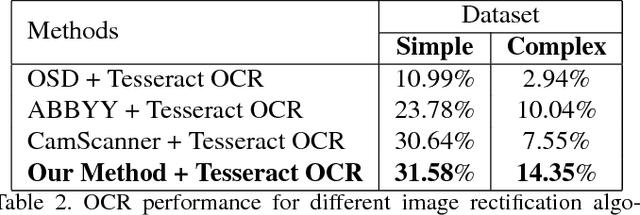
Removing perspective distortion from hand held camera captured document images is one of the primitive tasks in document analysis, but unfortunately, no such method exists that can reliably remove the perspective distortion from document images automatically. In this paper, we propose a convolutional neural network based method for recovering homography from hand-held camera captured documents. Our proposed method works independent of document's underlying content and is trained end-to-end in a fully automatic way. Specifically, this paper makes following three contributions: Firstly, we introduce a large scale synthetic dataset for recovering homography from documents images captured under different geometric and photometric transformations; secondly, we show that a generic convolutional neural network based architecture can be successfully used for regressing the corners positions of documents captured under wild settings; thirdly, we show that L1 loss can be reliably used for corners regression. Our proposed method gives state-of-the-art performance on the tested datasets, and has potential to become an integral part of document analysis pipeline.