 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Super-Resolution Methods via Incremental Residual Learning
Paper and Code



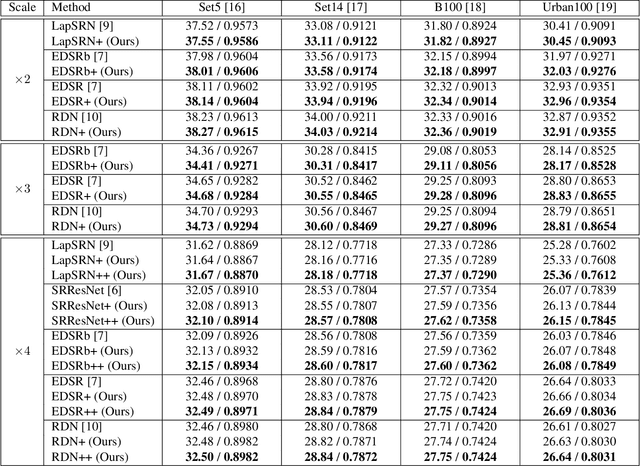
Recently, deep Convolutional Neural Networks (CNNs) have shown promising performance in accurate reconstruction of high resolution (HR) image, given its low resolution (LR) counter-part. However, recent state-of-the-art methods operate primarily on LR image for memory efficiency, but we show that it comes at the cost of performance. Furthermore, because spatial dimensions of input and output of such networks do not match, it's not possible to learn residuals in image space; we show that learning residuals in image space leads to performance enhancement. To this end, we propose a novel Incremental Residual Learning (IRL) framework to solve the above mentioned issues. In IRL, a set of branches i.e arbitrary image-to-image networks are trained sequentially where each branch takes spatially upsampled higher dimensional feature maps as input and predicts the residuals of all previous branches combined. We plug recent state of the art methods as base networks in IRL framework and demonstrate the consistent performance enhancement through extensive experiments on public benchmark datasets to set a new state of the art for super-resolution. Compared to the base networks our method incurs no extra memory overhead as only one branch is trained at a time. Furthermore, as our method is trained to learned residuals, complete set of branches are trained in only 20% of time relative to base network.