 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Informed Memory Generation for Self-Improving Agent Systems
Mar 11, 2026LLM-powered agents face a persistent challenge: learning from their execution experiences to improve future performance. While agents can successfully complete many tasks, they often repeat inefficient patterns, fail to recover from similar errors, and miss opportunities to apply successful strategies from past executions. We present a novel framework for automatically extracting actionable learnings from agent execution trajectories and utilizing them to improve future performance through contextual memory retrieval. Our approach comprises four components: (1) a Trajectory Intelligence Extractor that performs semantic analysis of agent reasoning patterns, (2) a Decision Attribution Analyzer that identifies which decisions and reasoning steps led to failures, recoveries, or inefficiencies, (3) a Contextual Learning Generator that produces three types of guidance -- strategy tips from successful patterns, recovery tips from failure handling, and optimization tips from inefficient but successful executions, and (4) an Adaptive Memory Retrieval System that injects relevant learnings into agent prompts based on multi-dimensional similarity. Unlike existing memory systems that store generic conversational facts, our framework understands execution patterns, extracts structured learnings with provenance, and retrieves guidance tailored to specific task contexts. Evaluation on the AppWorld benchmark demonstrates consistent improvements, with up to 14.3 percentage point gains in scenario goal completion on held-out tasks and particularly strong benefits on complex tasks (28.5~pp scenario goal improvement, a 149\% relative increase).
VOILA: Value-of-Information Guided Fidelity Selection for Cost-Aware Multimodal Question Answering
Feb 03, 2026Despite significant costs from retrieving and processing high-fidelity visual inputs, most multimodal vision-language systems operate at fixed fidelity levels. We introduce VOILA, a framework for Value-Of-Information-driven adaptive fidelity selection in Visual Question Answering (VQA) that optimizes what information to retrieve before model execution. Given a query, VOILA uses a two-stage pipeline: a gradient-boosted regressor estimates correctness likelihood at each fidelity from question features alone, then an isotonic calibrator refines these probabilities for reliable decision-making. The system selects the minimum-cost fidelity maximizing expected utility given predicted accuracy and retrieval costs. We evaluate VOILA across three deployment scenarios using five datasets (VQA-v2, GQA, TextVQA, LoCoMo, FloodNet) and six Vision-Language Models (VLMs) with 7B-235B parameters. VOILA consistently achieves 50-60% cost reductions while retaining 90-95% of full-resolution accuracy across diverse query types and model architectures, demonstrating that pre-retrieval fidelity selection is vital to optimize multimodal inference under resource constraints.
An Explainable AI based approach for Monitoring Animal Health
Aug 13, 2025Monitoring cattle health and optimizing yield are key challenges faced by dairy farmers due to difficulties in tracking all animals on the farm. This work aims to showcase modern data-driven farming practices based on explainable machine learning(ML) methods that explain the activity and behaviour of dairy cattle (cows). Continuous data collection of 3-axis accelerometer sensors and usage of robust ML methodologies and algorithms, provide farmers and researchers with actionable information on cattle activity, allowing farmers to make informed decisions and incorporate sustainable practices. This study utilizes Bluetooth-based Internet of Things (IoT) devices and 4G networks for seamless data transmission, immediate analysis, inference generation, and explains the models performance with explainability frameworks. Special emphasis is put on the pre-processing of the accelerometers time series data, including the extraction of statistical characteristics, signal processing techniques, and lag-based features using the sliding window technique. Various hyperparameter-optimized ML models are evaluated across varying window lengths for activity classification. The k-nearest neighbour Classifier achieved the best performance, with AUC of mean 0.98 and standard deviation of 0.0026 on the training set and 0.99 on testing set). In order to ensure transparency, Explainable AI based frameworks such as SHAP is used to interpret feature importance that can be understood and used by practitioners. A detailed comparison of the important features, along with the stability analysis of selected features, supports development of explainable and practical ML models for sustainable livestock management.
Leveraging Synthetic Data for Question Answering with Multilingual LLMs in the Agricultural Domain
Jul 22, 2025



Enabling farmers to access accurate agriculture-related information in their native languages in a timely manner is crucial for the success of the agriculture field. Although large language models (LLMs) can be used to implement Question Answering (QA) systems, simply using publicly available general-purpose LLMs in agriculture typically offer generic advisories, lacking precision in local and multilingual contexts due to insufficient domain-specific training and scarcity of high-quality, region-specific datasets. Our study addresses these limitations by generating multilingual synthetic agricultural datasets (English, Hindi, Punjabi) from agriculture-specific documents and fine-tuning language-specific LLMs. Our evaluation on curated multilingual datasets demonstrates significant improvements in factual accuracy, relevance, and agricultural consensus for the fine-tuned models compared to their baseline counterparts. These results highlight the efficacy of synthetic data-driven, language-specific fine-tuning as an effective strategy to improve the performance of LLMs in agriculture, especially in multilingual and low-resource settings. By enabling more accurate and localized agricultural advisory services, this study provides a meaningful step toward bridging the knowledge gap in AI-driven agricultural solutions for diverse linguistic communities.
FLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
Navigating the Fragrance space Via Graph Generative Models And Predicting Odors
Jan 30, 2025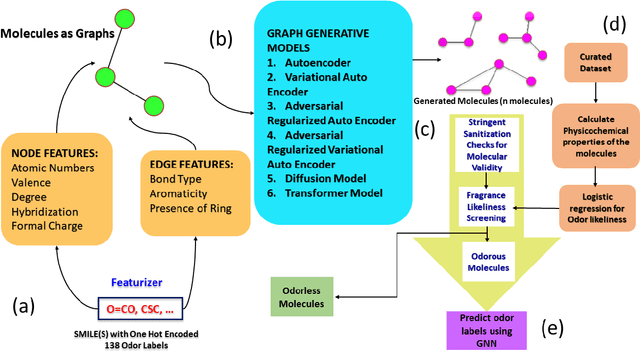


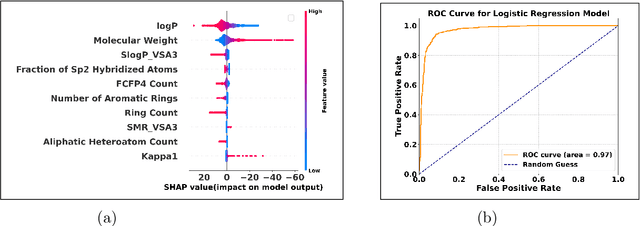
We explore a suite of generative modelling techniques to efficiently navigate and explore the complex landscapes of odor and the broader chemical space. Unlike traditional approaches, we not only generate molecules but also predict the odor likeliness with ROC AUC score of 0.97 and assign probable odor labels. We correlate odor likeliness with physicochemical features of molecules using machine learning techniques and leverage SHAP (SHapley Additive exPlanations) to demonstrate the interpretability of the function. The whole process involves four key stages: molecule generation, stringent sanitization checks for molecular validity, fragrance likeliness screening and odor prediction of the generated molecules. By making our code and trained models publicly accessible, we aim to facilitate broader adoption of our research across applications in fragrance discovery and olfactory research.
FaceFilterSense: A Filter-Resistant Face Recognition and Facial Attribute Analysis Framework
Apr 12, 2024



With the advent of social media, fun selfie filters have come into tremendous mainstream use affecting the functioning of facial biometric systems as well as image recognition systems. These filters vary from beautification filters and Augmented Reality (AR)-based filters to filters that modify facial landmarks. Hence, there is a need to assess the impact of such filters on the performance of existing face recognition systems. The limitation associated with existing solutions is that these solutions focus more on the beautification filters. However, the current AR-based filters and filters which distort facial key points are in vogue recently and make the faces highly unrecognizable even to the naked eye. Also, the filters considered are mostly obsolete with limited variations. To mitigate these limitations, we aim to perform a holistic impact analysis of the latest filters and propose an user recognition model with the filtered images. We have utilized a benchmark dataset for baseline images, and applied the latest filters over them to generate a beautified/filtered dataset. Next, we have introduced a model FaceFilterNet for beautified user recognition. In this framework, we also utilize our model to comment on various attributes of the person including age, gender, and ethnicity. In addition, we have also presented a filter-wise impact analysis on face recognition, age estimation, gender, and ethnicity prediction. The proposed method affirms the efficacy of our dataset with an accuracy of 87.25% and an optimal accuracy for facial attribute analysis.
HarmPot: An Annotation Framework for Evaluating Offline Harm Potential of Social Media Text
Mar 17, 2024
In this paper, we discuss the development of an annotation schema to build datasets for evaluating the offline harm potential of social media texts. We define "harm potential" as the potential for an online public post to cause real-world physical harm (i.e., violence). Understanding that real-world violence is often spurred by a web of triggers, often combining several online tactics and pre-existing intersectional fissures in the social milieu, to result in targeted physical violence, we do not focus on any single divisive aspect (i.e., caste, gender, religion, or other identities of the victim and perpetrators) nor do we focus on just hate speech or mis/dis-information. Rather, our understanding of the intersectional causes of such triggers focuses our attempt at measuring the harm potential of online content, irrespective of whether it is hateful or not. In this paper, we discuss the development of a framework/annotation schema that allows annotating the data with different aspects of the text including its socio-political grounding and intent of the speaker (as expressed through mood and modality) that together contribute to it being a trigger for offline harm. We also give a comparative analysis and mapping of our framework with some of the existing frameworks.
ProtoNER: Few shot Incremental Learning for Named Entity Recognition using Prototypical Networks
Oct 03, 2023

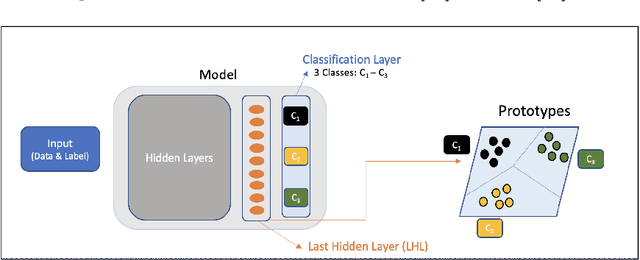
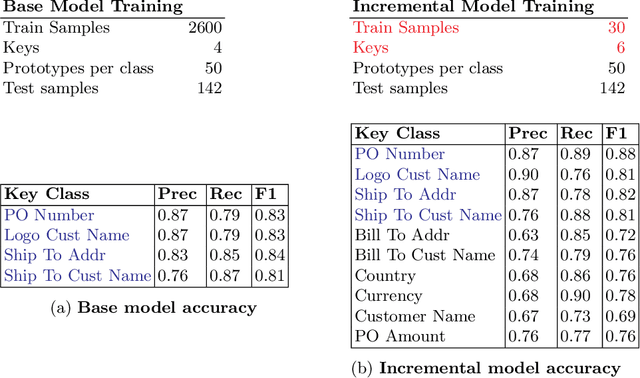
Key value pair (KVP) extraction or Named Entity Recognition(NER) from visually rich documents has been an active area of research in document understanding and data extraction domain. Several transformer based models such as LayoutLMv2, LayoutLMv3, and LiLT have emerged achieving state of the art results. However, addition of even a single new class to the existing model requires (a) re-annotation of entire training dataset to include this new class and (b) retraining the model again. Both of these issues really slow down the deployment of updated model. \\ We present \textbf{ProtoNER}: Prototypical Network based end-to-end KVP extraction model that allows addition of new classes to an existing model while requiring minimal number of newly annotated training samples. The key contributions of our model are: (1) No dependency on dataset used for initial training of the model, which alleviates the need to retain original training dataset for longer duration as well as data re-annotation which is very time consuming task, (2) No intermediate synthetic data generation which tends to add noise and results in model's performance degradation, and (3) Hybrid loss function which allows model to retain knowledge about older classes as well as learn about newly added classes.\\ Experimental results show that ProtoNER finetuned with just 30 samples is able to achieve similar results for the newly added classes as that of regular model finetuned with 2600 samples.
An Efficient Ensemble Explainable AI (XAI) Approach for Morphed Face Detection
Apr 23, 2023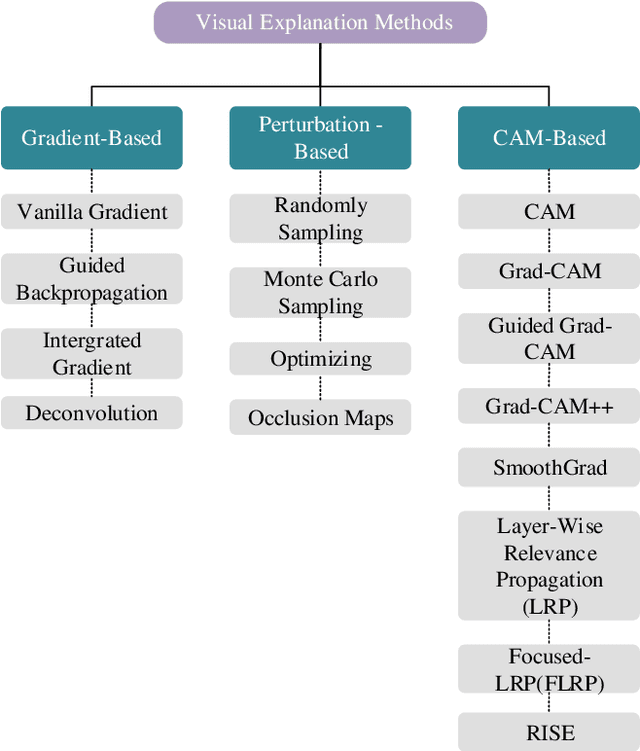

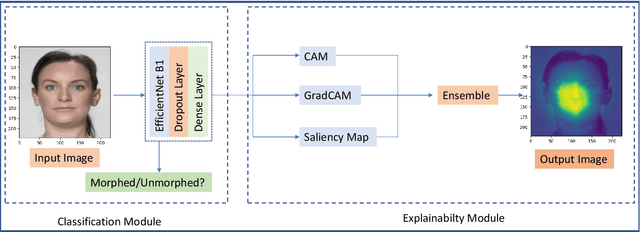
The extensive utilization of biometric authentication systems have emanated attackers / imposters to forge user identity based on morphed images. In this attack, a synthetic image is produced and merged with genuine. Next, the resultant image is user for authentication. Numerous deep neural convolutional architectures have been proposed in literature for face Morphing Attack Detection (MADs) to prevent such attacks and lessen the risks associated with them. Although, deep learning models achieved optimal results in terms of performance, it is difficult to understand and analyse these networks since they are black box/opaque in nature. As a consequence, incorrect judgments may be made. There is, however, a dearth of literature that explains decision-making methods of black box deep learning models for biometric Presentation Attack Detection (PADs) or MADs that can aid the biometric community to have trust in deep learning-based biometric systems for identification and authentication in various security applications such as border control, criminal database establishment etc. In this work, we present a novel visual explanation approach named Ensemble XAI integrating Saliency maps, Class Activation Maps (CAM) and Gradient-CAM (Grad-CAM) to provide a more comprehensive visual explanation for a deep learning prognostic model (EfficientNet-B1) that we have employed to predict whether the input presented to a biometric authentication system is morphed or genuine. The experimentations have been performed on three publicly available datasets namely Face Research Lab London Set, Wide Multi-Channel Presentation Attack (WMCA), and Makeup Induced Face Spoofing (MIFS). The experimental evaluations affirms that the resultant visual explanations highlight more fine-grained details of image features/areas focused by EfficientNet-B1 to reach decisions along with appropriate reasoning.