 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotated Speech Corpus for Low Resource Indian Languages: Awadhi, Bhojpuri, Braj and Magahi
Jun 26, 2022
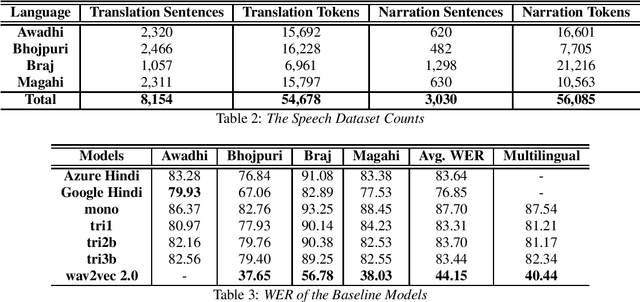
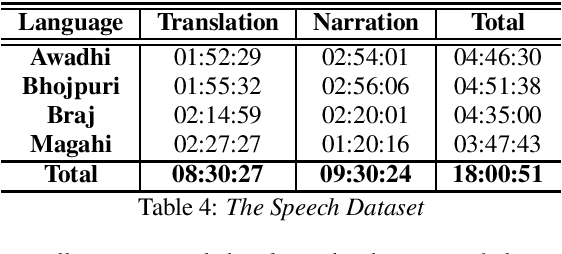
In this paper we discuss an in-progress work on the development of a speech corpus for four low-resource Indo-Aryan languages -- Awadhi, Bhojpuri, Braj and Magahi using the field methods of linguistic data collection. The total size of the corpus currently stands at approximately 18 hours (approx. 4-5 hours each language) and it is transcribed and annotated with grammatical information such as part-of-speech tags, morphological features and Universal dependency relationships. We discuss our methodology for data collection in these languages, most of which was done in the middle of the COVID-19 pandemic, with one of the aims being to generate some additional income for low-income groups speaking these languages. In the paper, we also discuss the results of the baseline experiments for automatic speech recognition system in these languages.
Demo of the Linguistic Field Data Management and Analysis System -- LiFE
Mar 22, 2022In the proposed demo, we will present a new software - Linguistic Field Data Management and Analysis System - LiFE (https://github.com/kmi-linguistics/life) - an open-source, web-based linguistic data management and analysis application that allows for systematic storage, management, sharing and usage of linguistic data collected from the field. The application allows users to store lexical items, sentences, paragraphs, audio-visual content with rich glossing / annotation; generate interactive and print dictionaries; and also train and use natural language processing tools and models for various purposes using this data. Since its a web-based application, it also allows for seamless collaboration among multiple persons and sharing the data, models, etc with each other. The system uses the Python-based Flask framework and MongoDB in the backend and HTML, CSS and Javascript at the frontend. The interface allows creation of multiple projects that could be shared with the other users. At the backend, the application stores the data in RDF format so as to allow its release as Linked Data over the web using semantic web technologies - as of now it makes use of the OntoLex-Lemon for storing the lexical data and Ligt for storing the interlinear glossed text and then internally linking it to the other linked lexicons and databases such as DBpedia and WordNet. Furthermore it provides support for training the NLP systems using scikit-learn and HuggingFace Transformers libraries as well as make use of any model trained using these libraries - while the user interface itself provides limited options for tuning the system, an externally-trained model could be easily incorporated within the application; similarly the dataset itself could be easily exported into a standard machine-readable format like JSON or CSV that could be consumed by other programs and pipelines.