 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
Jun 21, 2024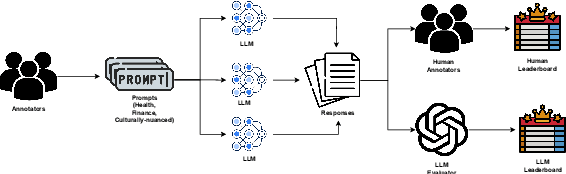
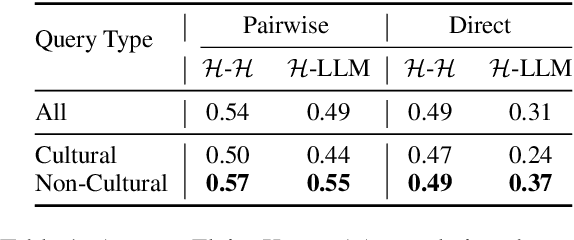
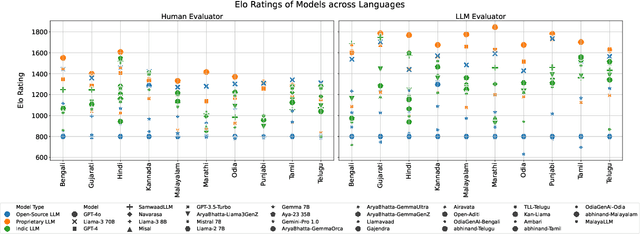
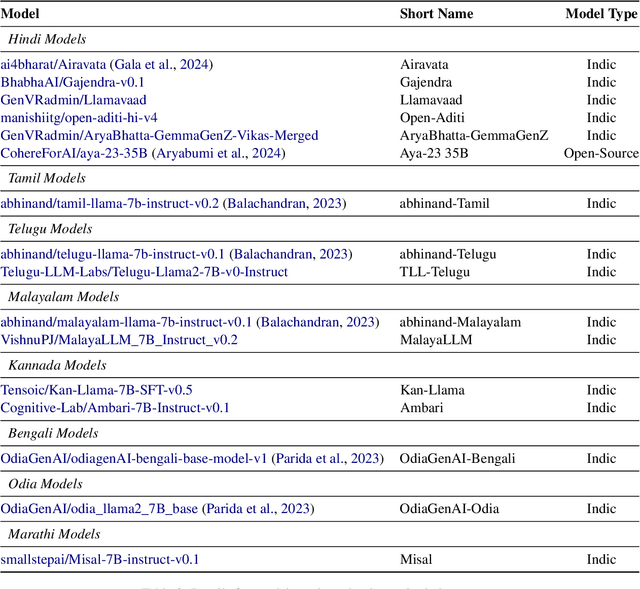
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024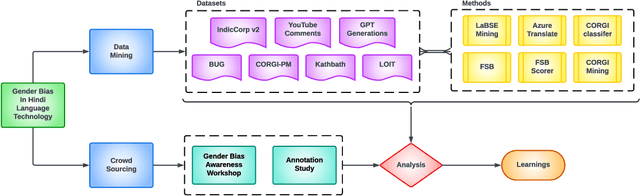

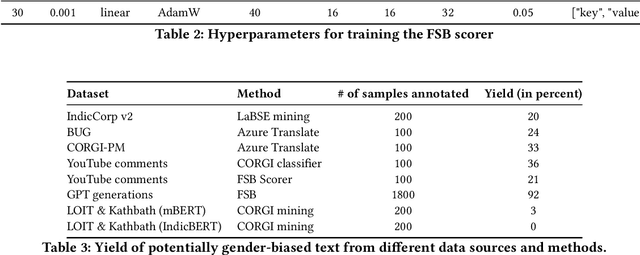
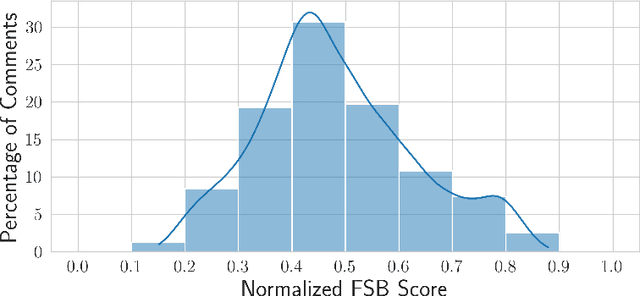
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
MunTTS: A Text-to-Speech System for Mundari
Jan 28, 2024



We present MunTTS, an end-to-end text-to-speech (TTS) system specifically for Mundari, a low-resource Indian language of the Austo-Asiatic family. Our work addresses the gap in linguistic technology for underrepresented languages by collecting and processing data to build a speech synthesis system. We begin our study by gathering a substantial dataset of Mundari text and speech and train end-to-end speech models. We also delve into the methods used for training our models, ensuring they are efficient and effective despite the data constraints. We evaluate our system with native speakers and objective metrics, demonstrating its potential as a tool for preserving and promoting the Mundari language in the digital age.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
MinUn: Accurate ML Inference on Microcontrollers
Oct 29, 2022



Running machine learning inference on tiny devices, known as TinyML, is an emerging research area. This task requires generating inference code that uses memory frugally, a task that standard ML frameworks are ill-suited for. A deployment framework for TinyML must be a) parametric in the number representation to take advantage of the emerging representations like posits, b) carefully assign high-precision to a few tensors so that most tensors can be kept in low-precision while still maintaining model accuracy, and c) avoid memory fragmentation. We describe MinUn, the first TinyML framework that holistically addresses these issues to generate efficient code for ARM microcontrollers (e.g., Arduino Uno, Due and STM32H747) that outperforms the prior TinyML frameworks.
Annotated Speech Corpus for Low Resource Indian Languages: Awadhi, Bhojpuri, Braj and Magahi
Jun 26, 2022
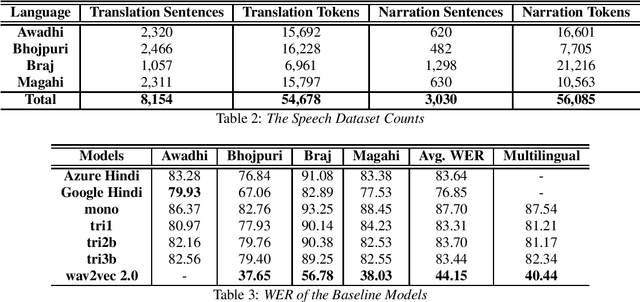
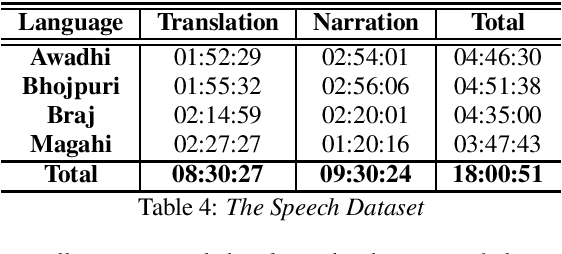
In this paper we discuss an in-progress work on the development of a speech corpus for four low-resource Indo-Aryan languages -- Awadhi, Bhojpuri, Braj and Magahi using the field methods of linguistic data collection. The total size of the corpus currently stands at approximately 18 hours (approx. 4-5 hours each language) and it is transcribed and annotated with grammatical information such as part-of-speech tags, morphological features and Universal dependency relationships. We discuss our methodology for data collection in these languages, most of which was done in the middle of the COVID-19 pandemic, with one of the aims being to generate some additional income for low-income groups speaking these languages. In the paper, we also discuss the results of the baseline experiments for automatic speech recognition system in these languages.
Aksharantar: Towards building open transliteration tools for the next billion users
May 06, 2022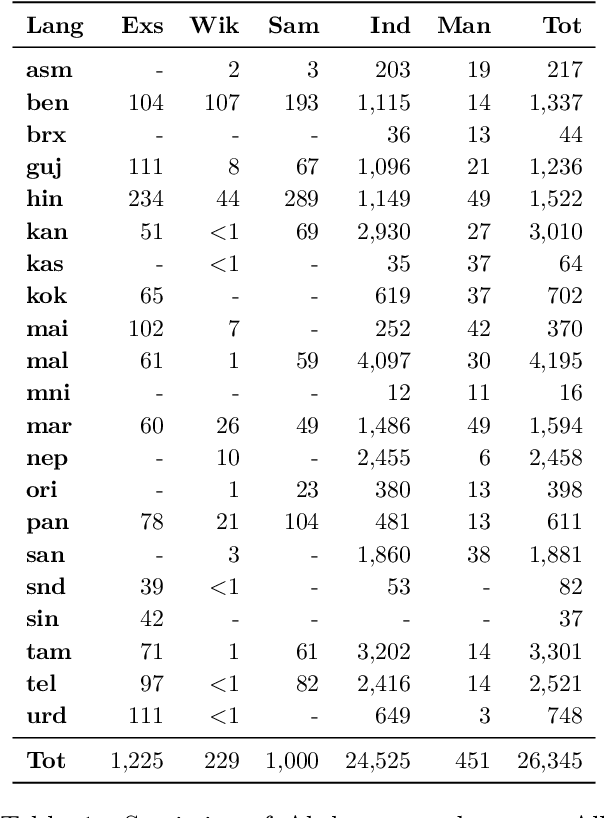


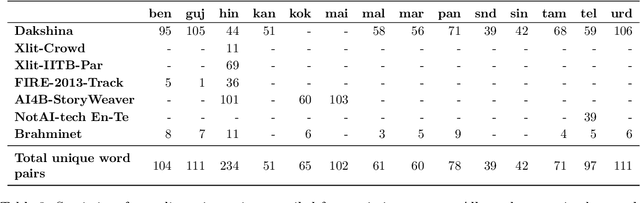
We introduce Aksharantar, the largest publicly available transliteration dataset for 21 Indic languages containing 26 million transliteration pairs. We build this dataset by mining transliteration pairs from large monolingual and parallel corpora, as well as collecting transliterations from human annotators to ensure diversity of words and representation of low-resource languages. We introduce a new, large, diverse testset for Indic language transliteration containing 103k words pairs spanning 19 languages that enables fine-grained analysis of transliteration models. We train the IndicXlit model on the Aksharantar training set. IndicXlit is a single transformer-based multilingual transliteration model for roman to Indic script conversion supporting 21 Indic languages. It achieves state-of-the art results on the Dakshina testset, and establishes strong baselines on the Aksharantar testset released along with this work. All the datasets and models are publicly available at https://indicnlp.ai4bharat.org/aksharantar. We hope the availability of these large-scale, open resources will spur innovation for Indic language transliteration and downstream applications.
MAFIA: Machine Learning Acceleration on FPGAs for IoT Applications
Jul 08, 2021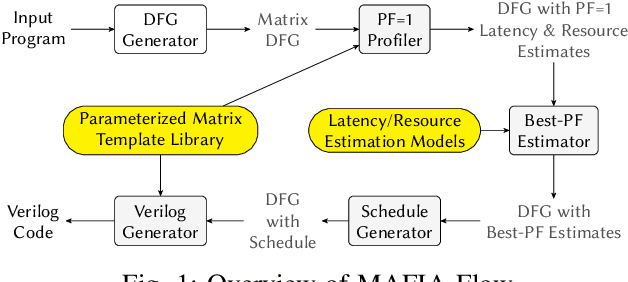
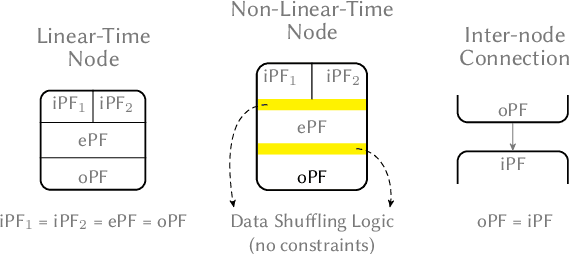
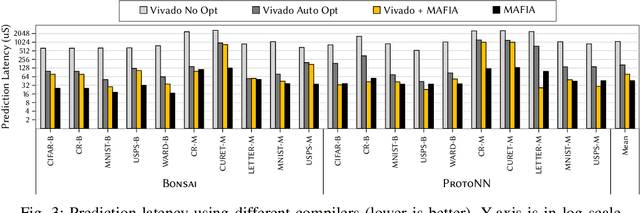
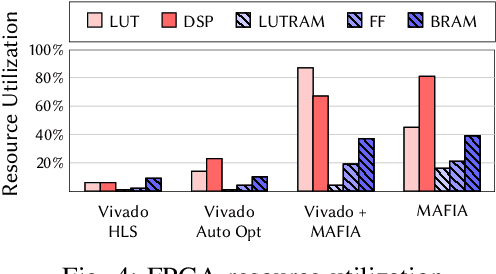
Recent breakthroughs in ML have produced new classes of models that allow ML inference to run directly on milliwatt-powered IoT devices. On one hand, existing ML-to-FPGA compilers are designed for deep neural-networks on large FPGAs. On the other hand, general-purpose HLS tools fail to exploit properties specific to ML inference, thereby resulting in suboptimal performance. We propose MAFIA, a tool to compile ML inference on small form-factor FPGAs for IoT applications. MAFIA provides native support for linear algebra operations and can express a variety of ML algorithms, including state-of-the-art models. We show that MAFIA-generated programs outperform best-performing variant of a commercial HLS compiler by 2.5x on average.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021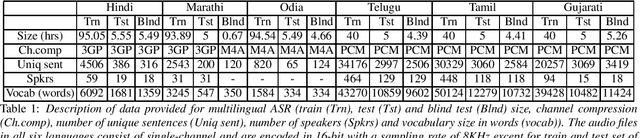
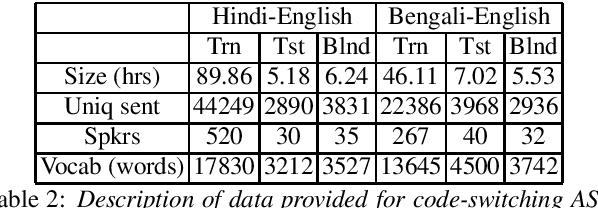
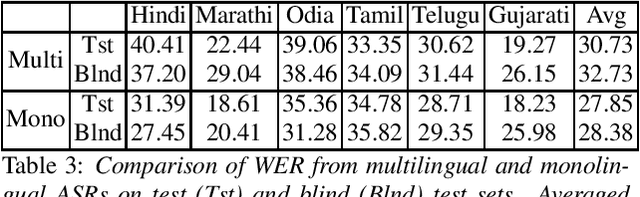
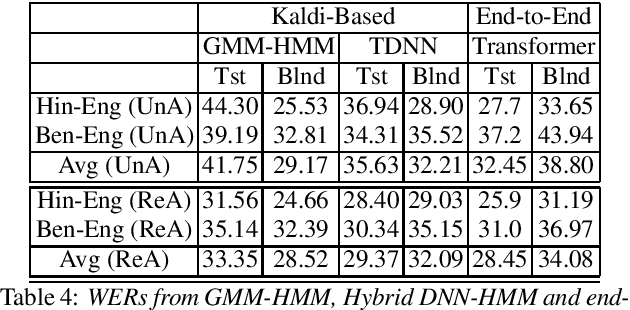
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.