 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotated Speech Corpus for Low Resource Indian Languages: Awadhi, Bhojpuri, Braj and Magahi
Jun 26, 2022
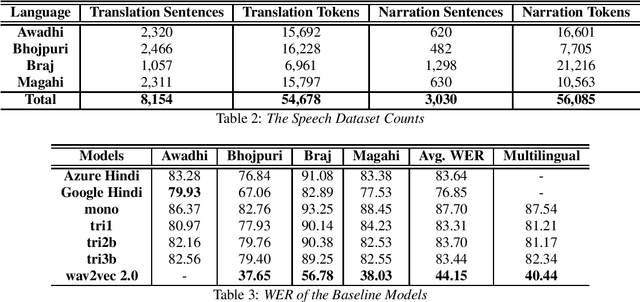
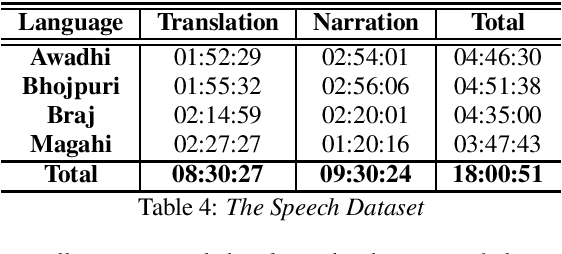
In this paper we discuss an in-progress work on the development of a speech corpus for four low-resource Indo-Aryan languages -- Awadhi, Bhojpuri, Braj and Magahi using the field methods of linguistic data collection. The total size of the corpus currently stands at approximately 18 hours (approx. 4-5 hours each language) and it is transcribed and annotated with grammatical information such as part-of-speech tags, morphological features and Universal dependency relationships. We discuss our methodology for data collection in these languages, most of which was done in the middle of the COVID-19 pandemic, with one of the aims being to generate some additional income for low-income groups speaking these languages. In the paper, we also discuss the results of the baseline experiments for automatic speech recognition system in these languages.