 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAksharantar: Towards building open transliteration tools for the next billion users
Paper and Code
May 06, 2022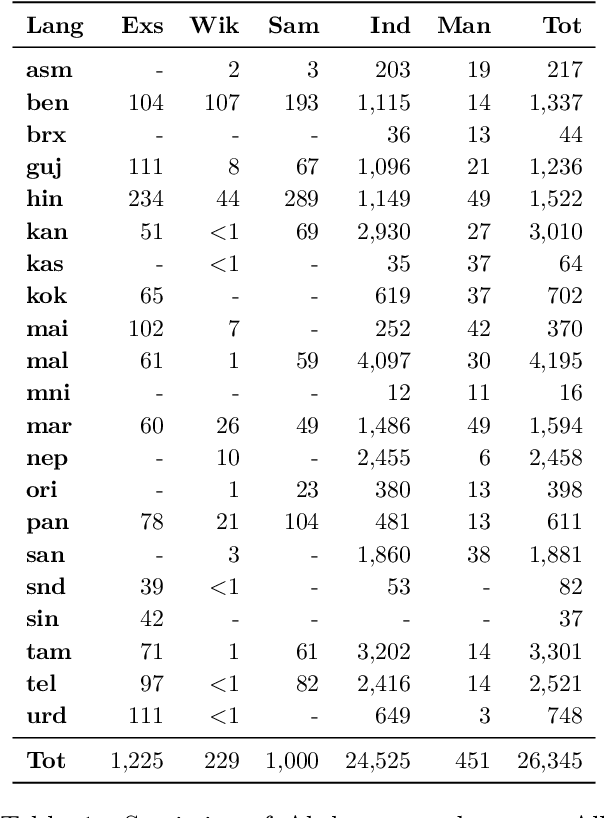


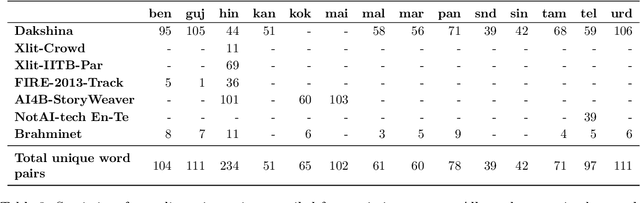
We introduce Aksharantar, the largest publicly available transliteration dataset for 21 Indic languages containing 26 million transliteration pairs. We build this dataset by mining transliteration pairs from large monolingual and parallel corpora, as well as collecting transliterations from human annotators to ensure diversity of words and representation of low-resource languages. We introduce a new, large, diverse testset for Indic language transliteration containing 103k words pairs spanning 19 languages that enables fine-grained analysis of transliteration models. We train the IndicXlit model on the Aksharantar training set. IndicXlit is a single transformer-based multilingual transliteration model for roman to Indic script conversion supporting 21 Indic languages. It achieves state-of-the art results on the Dakshina testset, and establishes strong baselines on the Aksharantar testset released along with this work. All the datasets and models are publicly available at https://indicnlp.ai4bharat.org/aksharantar. We hope the availability of these large-scale, open resources will spur innovation for Indic language transliteration and downstream applications.