 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic High-quality Verilog Assertion Generation through Subtask-Focused Fine-Tuned LLMs and Iterative Prompting
Nov 23, 2024



Formal Property Verification (FPV), using SystemVerilog Assertions (SVA), is crucial for ensuring the completeness of design with respect to the specification. However, writing SVA is a laborious task and has a steep learning curve. In this work, we present a large language model (LLM) -based flow to automatically generate high-quality SVA from the design specification documents, named \ToolName. We introduce a novel sub-task-focused fine-tuning approach that effectively addresses functionally incorrect assertions produced by baseline LLMs, leading to a remarkable 7.3-fold increase in the number of functionally correct assertions. Recognizing the prevalence of syntax and semantic errors, we also developed an iterative refinement method that enhances the LLM's initial outputs by systematically re-prompting it to correct identified issues. This process is further strengthened by a custom compiler that generates meaningful error messages, guiding the LLM towards improved accuracy. The experiments demonstrate a 26\% increase in the number of assertions free from syntax errors using this approach, showcasing its potential to streamline the FPV process.
ZOBNN: Zero-Overhead Dependable Design of Binary Neural Networks with Deliberately Quantized Parameters
Jul 06, 2024



Low-precision weights and activations in deep neural networks (DNNs) outperform their full-precision counterparts in terms of hardware efficiency. When implemented with low-precision operations, specifically in the extreme case where network parameters are binarized (i.e. BNNs), the two most frequently mentioned benefits of quantization are reduced memory consumption and a faster inference process. In this paper, we introduce a third advantage of very low-precision neural networks: improved fault-tolerance attribute. We investigate the impact of memory faults on state-of-the-art binary neural networks (BNNs) through comprehensive analysis. Despite the inclusion of floating-point parameters in BNN architectures to improve accuracy, our findings reveal that BNNs are highly sensitive to deviations in these parameters caused by memory faults. In light of this crucial finding, we propose a technique to improve BNN dependability by restricting the range of float parameters through a novel deliberately uniform quantization. The introduced quantization technique results in a reduction in the proportion of floating-point parameters utilized in the BNN, without incurring any additional computational overheads during the inference stage. The extensive experimental fault simulation on the proposed BNN architecture (i.e. ZOBNN) reveal a remarkable 5X enhancement in robustness compared to conventional floating-point DNN. Notably, this improvement is achieved without incurring any computational overhead. Crucially, this enhancement comes without computational overhead. \ToolName~excels in critical edge applications characterized by limited computational resources, prioritizing both dependability and real-time performance.
QUTE: Quantifying Uncertainty in TinyML models with Early-exit-assisted ensembles
Apr 19, 2024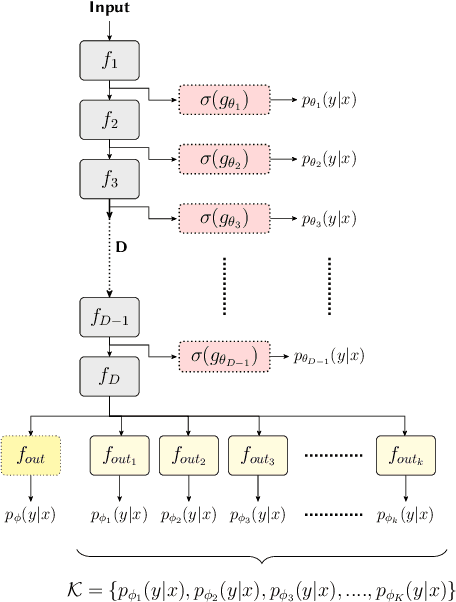
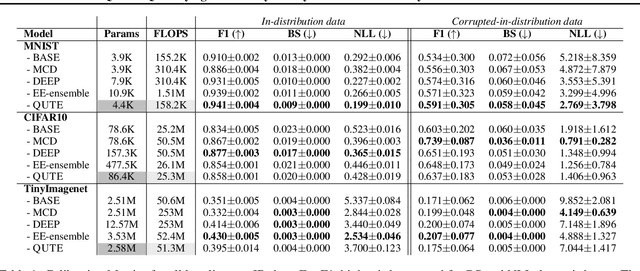
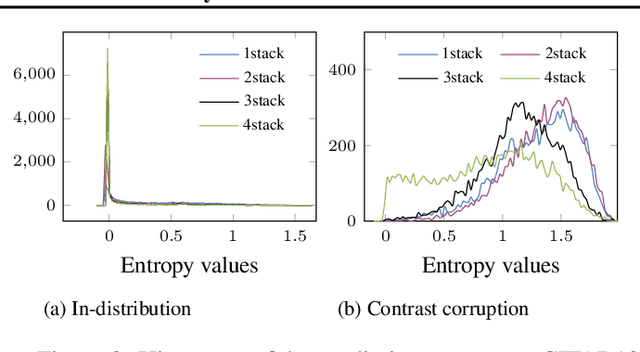

Existing methods for uncertainty quantification incur massive memory and compute overhead, often requiring multiple models/inferences. Hence they are impractical on ultra-low-power KB-sized TinyML devices. To reduce overhead, prior works have proposed the use of early-exit networks as ensembles to quantify uncertainty in a single forward-pass. However, they still have a prohibitive cost for tinyML. To address these challenges, we propose QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models. QUTE adds additional output blocks at the final exit of the base network and distills the knowledge of early-exits into these blocks to create a diverse and lightweight ensemble architecture. Our results show that QUTE outperforms popular prior works, and improves the quality of uncertainty estimates by 6% with 3.1x lower model size on average compared to the most relevant prior work. Furthermore, we demonstrate that QUTE is also effective in detecting co-variate shifted and out-of-distribution inputs, and shows competitive performance relative to G-ODIN, a state-of-the-art generalized OOD detector.
DNN Memory Footprint Reduction via Post-Training Intra-Layer Multi-Precision Quantization
Apr 03, 2024



The imperative to deploy Deep Neural Network (DNN) models on resource-constrained edge devices, spurred by privacy concerns, has become increasingly apparent. To facilitate the transition from cloud to edge computing, this paper introduces a technique that effectively reduces the memory footprint of DNNs, accommodating the limitations of resource-constrained edge devices while preserving model accuracy. Our proposed technique, named Post-Training Intra-Layer Multi-Precision Quantization (PTILMPQ), employs a post-training quantization approach, eliminating the need for extensive training data. By estimating the importance of layers and channels within the network, the proposed method enables precise bit allocation throughout the quantization process. Experimental results demonstrate that PTILMPQ offers a promising solution for deploying DNNs on edge devices with restricted memory resources. For instance, in the case of ResNet50, it achieves an accuracy of 74.57\% with a memory footprint of 9.5 MB, representing a 25.49\% reduction compared to previous similar methods, with only a minor 1.08\% decrease in accuracy.
T-RECX: Tiny-Resource Efficient Convolutional Neural Networks with Early-Exit
Jul 14, 2022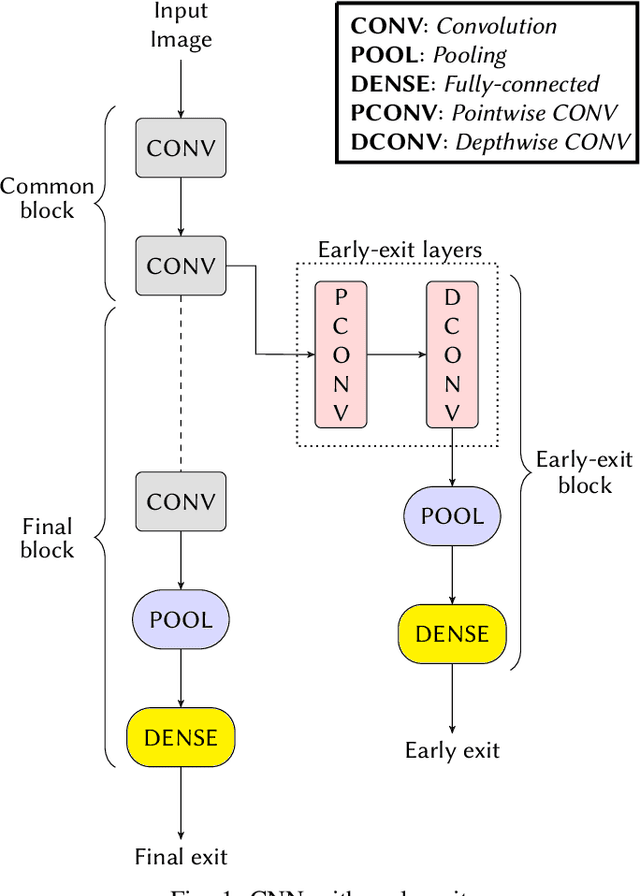
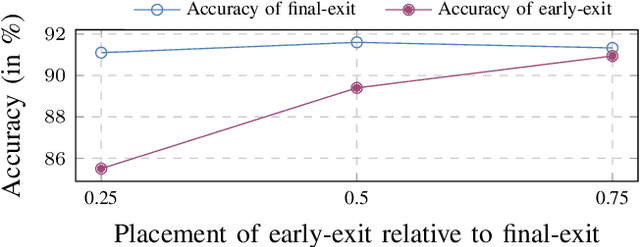
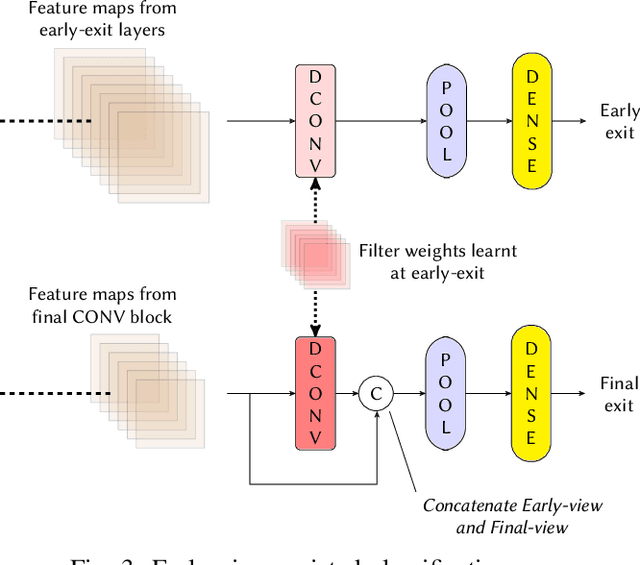
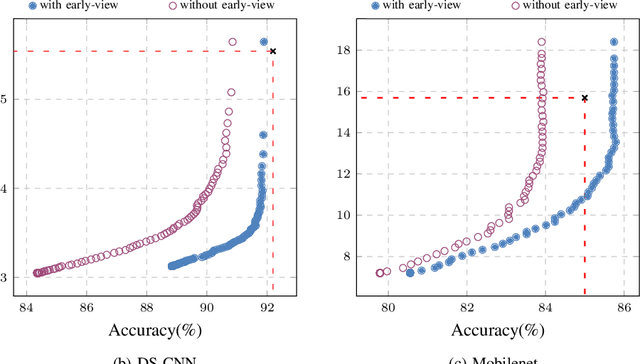
Deploying Machine learning (ML) on the milliwatt-scale edge devices (tinyML) is gaining popularity due to recent breakthroughs in ML and IoT. However, the capabilities of tinyML are restricted by strict power and compute constraints. The majority of the contemporary research in tinyML focuses on model compression techniques such as model pruning and quantization to fit ML models on low-end devices. Nevertheless, the improvements in energy consumption and inference time obtained by existing techniques are limited because aggressive compression quickly shrinks model capacity and accuracy. Another approach to improve inference time and/or reduce power while preserving its model capacity is through early-exit networks. These networks place intermediate classifiers along a baseline neural network that facilitate early exit from neural network computation if an intermediate classifier exhibits sufficient confidence in its prediction. Previous work on early-exit networks have focused on large networks, beyond what would typically be used for tinyML applications. In this paper, we discuss the challenges of adding early-exits to state-of-the-art tiny-CNNs and devise an early-exit architecture, T-RECX, that addresses these challenges. In addition, we develop a method to alleviate the effect of network overthinking at the final exit by leveraging the high-level representations learned by the early-exit. We evaluate T-RECX on three CNNs from the MLPerf tiny benchmark suite for image classification, keyword spotting and visual wake word detection tasks. Our results demonstrate that T-RECX improves the accuracy of baseline network and significantly reduces the average inference time of tiny-CNNs. T-RECX achieves 32.58% average reduction in FLOPS in exchange for 1% accuracy across all evaluated models. Also, our techniques increase the accuracy of baseline network in two out of three models we evaluate
MAFIA: Machine Learning Acceleration on FPGAs for IoT Applications
Jul 08, 2021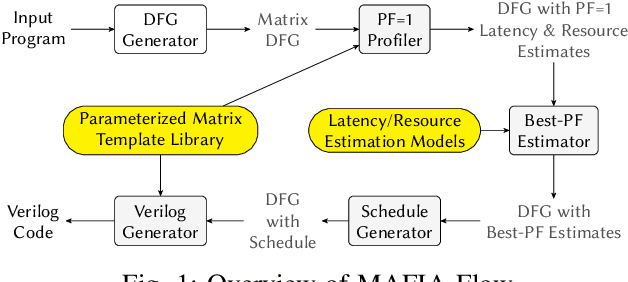
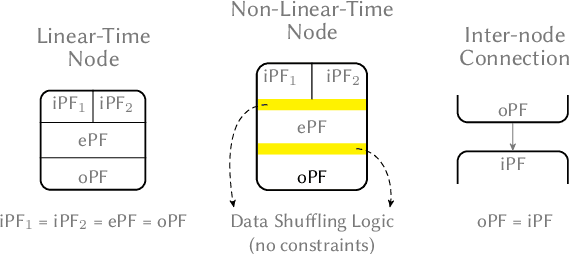
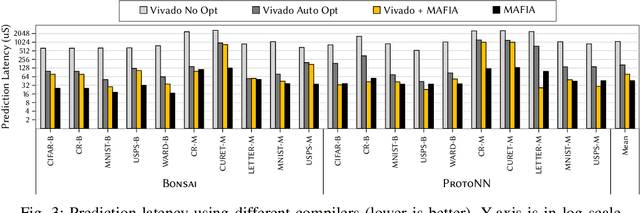
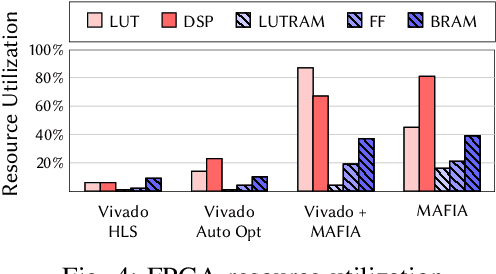
Recent breakthroughs in ML have produced new classes of models that allow ML inference to run directly on milliwatt-powered IoT devices. On one hand, existing ML-to-FPGA compilers are designed for deep neural-networks on large FPGAs. On the other hand, general-purpose HLS tools fail to exploit properties specific to ML inference, thereby resulting in suboptimal performance. We propose MAFIA, a tool to compile ML inference on small form-factor FPGAs for IoT applications. MAFIA provides native support for linear algebra operations and can express a variety of ML algorithms, including state-of-the-art models. We show that MAFIA-generated programs outperform best-performing variant of a commercial HLS compiler by 2.5x on average.