 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUTE: Quantifying Uncertainty in TinyML models with Early-exit-assisted ensembles
Paper and Code
Apr 19, 2024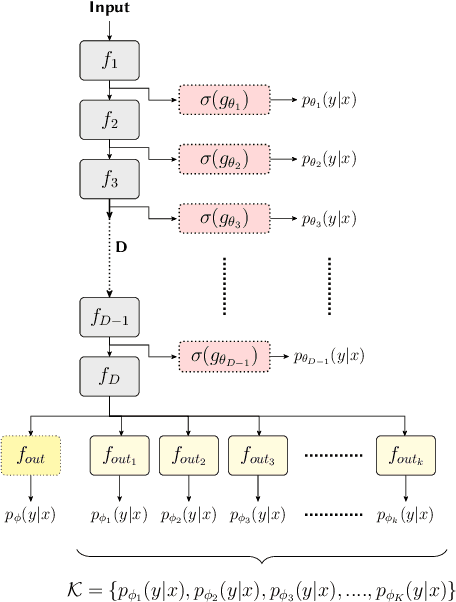
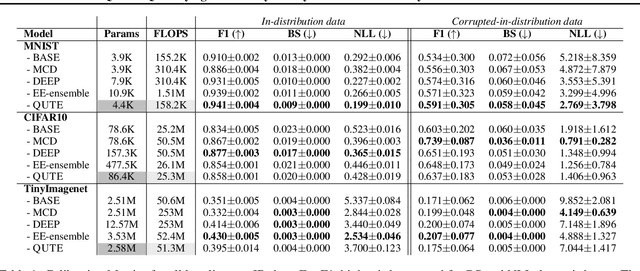
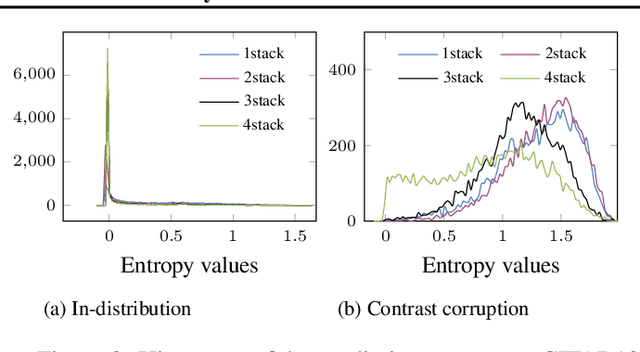

Existing methods for uncertainty quantification incur massive memory and compute overhead, often requiring multiple models/inferences. Hence they are impractical on ultra-low-power KB-sized TinyML devices. To reduce overhead, prior works have proposed the use of early-exit networks as ensembles to quantify uncertainty in a single forward-pass. However, they still have a prohibitive cost for tinyML. To address these challenges, we propose QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models. QUTE adds additional output blocks at the final exit of the base network and distills the knowledge of early-exits into these blocks to create a diverse and lightweight ensemble architecture. Our results show that QUTE outperforms popular prior works, and improves the quality of uncertainty estimates by 6% with 3.1x lower model size on average compared to the most relevant prior work. Furthermore, we demonstrate that QUTE is also effective in detecting co-variate shifted and out-of-distribution inputs, and shows competitive performance relative to G-ODIN, a state-of-the-art generalized OOD detector.